anaconda
- 激活环境:conda active xx
torch
reshape
conv_img=torch.reshape(conv_img, (-1, 3, 30, 30))
# batch_size, channels, Height, Width
Conv2d
self.conv1 = nn.Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)
# padding 为边缘填充
# stride 为步幅
# out_channels 即为卷积核的数量,也是输出的channel数
SOTA
Sota实际上就是State of the arts 的缩写,指的是在某一个领域做的Performance最好的model,一般就是指在一些benchmark的数据集上跑分非常高的那些模型。
SOTA model:并不是特指某个具体的模型,而是指在该项研究任务中,目前最好/最先进的模型。 SOTA result:指的是在该项研究任务中,目前最好的模型的结果/性能/表现。
数据处理\特征工程

归一化 标准化
归一化 (Normalization)、标准化 (Standardization)和中心/零均值化 (Zero-centered)-CSDN博客
这些都是针对某一个维度来做的,而不是一个样本。
归一化:将数据缩放到固定范围(如[0,1]或[-1,1]),不改变原始分布形状,仅缩放范围。
标准化:将数据调整为均值为0、标准差为1的分布。使数据更接近标准正态分布
是标准差。
消除量纲的影响: 不同的特征可能有不同的 单位(如米、千克、秒),标准化可以消除这些量纲的差异。
提高算法性能: 对于依赖于距离的算法(如 KNN、SVM 等)或基于梯度下降优化的算法(如神经网络、线性回归),标准化可以加快收敛速度。
处理偏态分布: 标准化可以帮助数据更接近正态分布,方便进一步分析。
机器学习问题
- 回归(根据历史信息进行预测)
- 分类:K近邻、决策树、朴素贝叶斯、逻辑回归、支持向量机、随机森林
- 聚类:K-Means
- 生成
机器学习分类
监督学习
是使用足够多的带有label的数据集来训练模型,数据集中的每个样本都带有人工标注的label。通俗理解就是,模型在学习的过程中,“老师”指导模型应该向哪个方向学习或调整。
- 线性回归(Linear Regression):用于回归任务,预测连续的数值。
- 逻辑回归(Logistic Regression):用于二分类任务,预测类别。
- 支持向量机(SVM):用于分类任务,构建超平面进行分类。
- 决策树(Decision Tree):基于树状结构进行决策的分类或回归方法。
无监督学习
是指训练模型用的数据没有人工标注的标签信息,通俗理解就是在“没有老师指导”的情况下,靠“学生”自己通过不断地探索,对知识进行归纳和总结,尝试发现数据中的内在规律或特征,来对训练数据打标签。
K-means 聚类:通过聚类中心将数据分组。
1.首先,我们选择一些类/组来使用并随机地初始化它们各自的中心点。要想知道要使用的类的数量,最好快速地查看一下数据,并尝试识别任何不同的分组。中心点是与每个数据点向量相同长度的向量,在上面的图形中是“X”。
2.每个数据点通过计算点和每个组中心之间的距离进行分类,然后将这个点分类为最接近它的组。
3.基于这些分类点,我们通过取组中所有向量的均值来重新计算组中心。
4.对一组迭代重复这些步骤。你还可以选择随机初始化组中心几次,然后选择那些看起来对它提供了最好结果的来运行。
K-Means聚类算法的优势在于它的速度非常快,因为我们所做的只是计算点和群中心之间的距离;它有一个线性复杂度O(n)。
另一方面,K-Means也有几个缺点。首先,你必须选择有多少组/类。这并不是不重要的事,理想情况下,我们希望它能帮我们解决这些问题,因为它的关键在于从数据中获得一些启示。K-Means也从随机选择的聚类中心开始,因此在不同的算法运行中可能产生不同的聚类结果。因此,结果可能是不可重复的,并且缺乏一致性。其他聚类方法更加一致。
半监督学习:是在只能获取少量的带label的数据,但是可以获取大量的的数据的情况下训练模型,让学习器不依赖于外界交互,自动地利用未标记样本来提升学习性能,半监督学习是监督学习和非监督学习的相结合的一种学习方法。
强化学习
(Reinforcement Learning)一种机器学习的方法,通过从外部获得激励来校正学习方向从而获得一种自适应的学习能力。
具备人类反馈的强化学习 (RLHF):在 RLHF 中,人类用户通过评估来响应生成的内容,此类评估可以帮助模型进行更新,以提高其准确性和相关性。通常,RLHF 涉及相关人员根据相同的提示对不同的输出进行“评分”。但这也可以很简单,比如让人员输入文字或通过语音回复聊天机器人或虚拟助手,以纠正其输出结果。
基本机器学习算法
线性回归算法(Linear Regression)
单变量回归,多变量回归
支持向量机算法(Support Vector Machine,SVM)
寻找一个维度为m-1决策超平面将n个维度为m的数据区分为两类数据。
将距离超平面最近的距离成为间隔,训练的目标是找到最大间隔。距离超平面最近的点称为支持向量
决策树

- 选择一个当前最优的特征(颜色),将当前数据分割成子集。
- 对于每一个子集,若子集都属于一个类别(label,好瓜),则标记为叶子节点,结束。否则标记为分支节点,循环。
最优特征
- 根据信息增益:即使用当前节点的信息熵减去所有子节点的信息熵的加权平均值。越大则说明该特征能够将样本划分的更好,更纯。缺点:更偏好取值较多的特征。
- 根据增益比:将信息增益除以IV(A),其是特征的固有属性,特征可能取值却多,其越大。一般来说先从候选划分特征中找出信息增益高于平均水平的属性,再从中选择信息增益率最高的。
- 根据基尼系数:基尼系数是一种衡量数据集纯度的指标,表示从数据集中随机抽取两个样本,其类别标签不一致的概率。
缺点
随着深度增加,容易过拟合:预剪枝,后剪枝。
随机森林
是一个包含多个决策树的分类器, 并且其输出的类别是由个别树输出的类别的众数而定。随机森林解决决策树泛化能力弱的特点
神经网络
分类问题
采用one-hot对类别进行编码,最后输出一个向量,对其进行softmax表示预测概率。
采用交叉熵作为损失函数,相较于MSE,更容易收敛。
激活函数
Relu:不建议使用sigmoid作为激活函数,因为其两端具有梯度饱和性,容易造成梯度消失。relu在大于零的区间导数值恒为一,便于参数优化。计算速度快。促进稀疏表示。
sigmoid:将任意实数映射到 (0, 1) 区间,表示概率。
softmax:将多个实数映射为概率分布,所有输出值的和为 1。
- 二分类任务:优先使用 Sigmoid(更简洁高效),二分类问题下,softmax等同于sigmoid但是计算量更大。
- 多分类任务(标签互斥):必须使用 Softmax。
- 多标签分类(标签独立):为每个标签使用独立的 Sigmoid。
优化
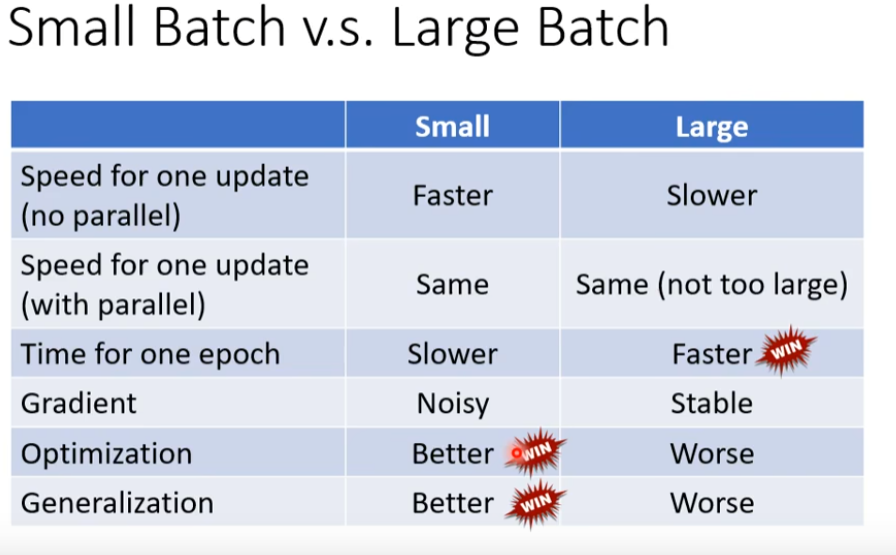
当loss无法继续下降时,考虑局部最小,马鞍点,LR设置不当,batch_size设置不当。
epoch
训练的轮次,一个epoch就已经看过了完整的一遍训练数据
batch_size
每个batch更新一次参数,一个batch是并行处理的。
Adma
最基础的优化器是SGD,其中是学习率。
momentum
梯度的一阶动量。可借助动量跳出局部最优点。
翻译为动量,即不仅考虑本次的梯度方向,还考虑上一次的更新方向,迭代下来就是第i次更新不仅看第i次的梯度,还要看以往所有梯度,通过一个系数来调整影响效果,m更新的方向由上一次的动量和当前动量的矢量和构成,其中是超参数,默认值为0.9.

优化后的公式为
其中,
RMSProp
引入梯度的二阶矩的估计,二阶动量。稀疏数据场景下表现好;自适应调节学习率。
σ最常用的设置方式为RMSProp,引入超参数,常设置为0.999
其中当接近一时,σ的变化取决于当前的梯度计算,梯度越大,更新的步伐就会变小。
校正
初始时m和都为零,会导致它们在初始阶段被低估。特别是当两个接近一时。为了补偿这种估计的偏差,Adam 算法引入了偏差校正步骤。
详细来说就是对上述两种做下面的公式:
总结
RMSProp + momentum + warm up
最终就是:
加上是防止除零,默认1e-8。

warm up
由于刚开始训练时,模型的权重是随机初始化的,loss比较大,此时若选择一个较大的学习率,可能带来模型的不稳定(振荡),选择Warmup的方式,可以使得开始训练的几个epoch或者一些step内学习率较小,在预热的小学习率下,模型可以慢慢趋于稳定,等模型相对稳定后再选择预先设置的学习率进行训练,有助于保持模型深层的稳定性,使得模型收敛速度变得更快,模型效果更佳。
正则化
正则化即为对学习算法的修改,旨在减少泛化误差而不是训练误差。正则化的策略包括:
- 约束和惩罚被设计为编码特定类型的先验知识。
- 偏好简单模型。
- 其他形式的正则化,如:集成的方法,即结合多个假说解释训练数据。
batch normalization
对于一个batch内的数据,做标准化,可以在任何一层加入BN层:

在test或inference中,往往不能立即获得一个batch的数据,常常使用moving average来获得均值和标准差,如:
其中p是超参数,常设为0.1
LOSS
分类问题常用 交叉熵损失函数
回归用均方差(MSE)
问题
过拟合:泛化误差大,泛化能力弱
欠拟合:训练误差大,模型过于简单
局部点
一阶偏导数为零,不一定陷入了局部最小值,马鞍点的一阶偏导数也是零,通过对L(θ)进行泰勒展开计算Hessian矩阵(由二阶偏导组成的矩阵,用于判断极值点类型)。泰勒展开公式如下:
其中,在局部点和马鞍点中g向量都为零,而H矩阵,即为hessian矩阵,若其正定,即为局部最小值点,负定即为局部最大值,故为:
同时,hessian矩阵也可指出更新的方向,若H矩阵有特征向量与特征值:
则上述泰勒展开公式可进一步写作:
这样根据该特征值的正负,就可使得Loss进一步降低
CNN
GPT总结
卷积神经网络(CNN,Convolutional Neural Network)是深度学习中一种用于处理具有网格结构数据(如图像)的神经网络。它是图像识别、目标检测、语音识别等领域的核心技术之一。以下是一些主要的知识点:
1. CNN的基本组成
CNN通常由以下几层组成:
- 卷积层(Convolutional Layer):这是CNN的核心层。卷积操作通过滑动一个小的滤波器(也叫做卷积核)在输入图像上,以提取特征。卷积核的尺寸通常较小(如3×3、5×5等),但是可以通过多个卷积层逐步学习更高级的特征。
- 激活函数(Activation Function):在卷积操作后,通常使用非线性激活函数(如ReLU)来引入非线性,使得模型能够学习复杂的模式。
- 池化层(Pooling Layer):池化层通常跟随在卷积层后面。它的作用是对特征图进行降采样,减少数据的维度,从而减小计算量并提高模型的鲁棒性。常见的池化方法是最大池化(Max Pooling)和平均池化(Average Pooling)。
- 全连接层(Fully Connected Layer):在网络的最后部分,通常会有一个或多个全连接层,用来将卷积层提取的高维特征映射到最终的输出类别。全连接层的每个节点与前一层的每个节点相连接。
- 输出层(Output Layer):输出层根据任务的不同,可以是分类任务的softmax层(用于多分类),或者是回归任务的线性输出层。
2. 卷积操作
卷积操作是CNN的关键,它通过对输入数据(如图像)应用滤波器(卷积核)来提取局部特征。每个卷积核可以识别一个特定的模式(例如边缘、纹理、颜色等),通过多个卷积层,网络可以逐渐学习到更复杂的特征。
- 步幅(Stride):控制卷积核滑动的步长,步幅越大,输出的特征图尺寸越小。
- 填充(Padding):为了保持卷积操作后特征图的尺寸不变,或者减小特征图的尺寸,通常会在输入数据的边缘进行填充(常用的方法是零填充)。
3. 常见的CNN结构
- LeNet:最早的CNN之一,主要用于手写数字识别(MNIST数据集)。
- AlexNet:是现代CNN的开创性工作之一,曾在2012年ImageNet竞赛中大获成功,带来了深度学习在计算机视觉领域的爆炸式发展。
- VGGNet:通过使用更多的卷积层来加深网络结构,采用3×3的小卷积核堆叠来构建深层网络。
- ResNet:提出了“残差连接”的概念,通过跳跃连接解决了深层网络训练中的梯度消失问题,使得网络可以更加深层化。
- Inception:使用了不同尺寸的卷积核来并行处理输入,从而提取多尺度的特征,较为高效。
4. CNN的优点
- 特征自动提取:CNN能够自动从数据中提取特征,减少了人工设计特征的工作量。
- 局部感知:卷积层通过局部连接(局部感知)使得网络能够专注于局部区域的特征,减少了参数量。
- 参数共享:同一个卷积核在输入的不同位置共享参数,进一步减少了需要学习的参数数量,提高了计算效率。
5. 应用领域
- 图像分类:CNN常用于图像分类任务,例如识别物体类别。
- 目标检测:可以用来检测图像中的特定目标(如YOLO、Faster R-CNN)。
- 语音识别:CNN还被用于处理一维的音频信号,进行语音识别任务。
- 自然语言处理(NLP):虽然RNN和Transformer更为主流,但CNN在文本分类等任务中也能表现得很好。
- 图像生成:如生成对抗网络(GAN)中的生成器部分也使用CNN来生成逼真的图像。
6. 优化技巧
- 批量归一化(Batch Normalization):通过规范化每一层的输入,减少梯度消失和梯度爆炸问题,进而加速训练。
- Dropout:在训练过程中随机丢弃一部分神经元,减少过拟合。
- 数据增强:通过对训练数据进行变换(如旋转、裁剪、翻转等),增加数据多样性,提升模型泛化能力。
感悟
全连接->引入感受野->共享参数,最终得到滤波器(卷积核)的概念,一步一步的降低网络的弹性,使得网络不断提升一个卷积核识别一个特征的能力,比如一张鸟的图片,极大概率上会有鸟嘴这一特征
GAN
生成对抗网络(GAN)由生成器和判别器两个部分组成。它们通过博弈论的方式进行训练。
组成
- 生成器:学习生成与真实数据相似的数据。
- 判别器:学习区分生成的数据和真实的数据。
生成器和判别器互相对抗,生成器的目标是让判别器无法区分生成的假数据与真实数据,判别器的目标是尽可能准确地区分这两者。
训练
在训练过程中,生成器和判别器通过以下方式相互作用:
- 固定生成器,训练判别器,判别器接收输入数据,输出一个值表示输入数据是真实数据的概率。
- 固定判别器,训练生成器,生成器通过随机噪声(高斯分布)生成假数据,判别器判断生成的假数据是否真实。
- 生成器的目标是使判别器认为假数据是真实的,而判别器的目标是识别真假数据。
- 训练过程中,生成器和判别器交替优化。生成器通过反向传播调整其参数,以欺骗判别器;判别器则通过反向传播优化,以准确地区分真实数据和生成数据。
大模型
预训练
预训练是一种自监督学习。
通过大量数据和算法,AI模型学会识别和生成规律。模型参数在此过程中不断调整,以最小化预测与实际值之间的误差,从而使其具备适应各种任务的学习能力,涵盖图像识别到自然语言处理等多个领域。
微调(fine-tuning)
DeepSpeed Accelerate VLLM Llama-Factory Lora SFT
微调过程为SFT(监督微调)和RLHF(基于人类反馈的强化学习)。而SFT微调根据微调的参数量可分为full-tuning和PEFT(Parameter-Efficient Fine-Tuning,参数高效微调)。

监督微调(SFT)
监督微调(SFT)是使用有标签的数据来调整一个预训练模型。是在预训练的基础上,用特定任务的数据进行进一步的训练,让模型适应具体的任务。比如,在自然语言处理中,预训练模型如BERT或GPT已经在大规模文本上进行了训练,然后通过SFT在特定任务的数据集(如问答、分类)上进行微调,以提高在该任务上的性能。这时候模型通过监督学习,利用输入和对应的标签来调整参数,最小化预测误差。
定义:基于有标签数据对预训练模型进行任务适配,通过最小化预测误差(如交叉熵损失)调整模型参数。
示例:使用标注的对话数据微调语言模型,使其生成符合特定风格的回复。
PEFT
Lora
在模型的决定性层次中引入小型、低秩的矩阵来实现模型行为的微调,而无需对整个模型结构进行大幅度修改。
- 确定微调目标权重矩阵:首先在大型模型(例如GPT)中识别出需要微调的权重矩阵,这些矩阵一般位于模型的多头自注意力和前馈神经网络部分。
- 引入两个低秩矩阵:然后,引入两个维度较小的低秩矩阵A和B。假设原始权重矩阵的尺寸为dd,则A和B的尺寸可能为dr和r*d,其中r远小于d。
- 计算低秩更新:通过这两个低秩矩阵的乘积AB来生成一个新矩阵,其秩(即r)远小于原始权重矩阵的秩。这个乘积实际上是对原始权重矩阵的一种低秩近似调整。
- 结合原始权重:最终,新生成的低秩矩阵AB被叠加到原始权重矩阵上。因此,原始权重经过了微调,但大部分权重维持不变。这个过程可以用数学表达式描述为:新权重 = 原始权重 + AB。
关键训练参数
- 输入长度
- Query 的最大长度设置为 512 tokens。
- Passage 的最大长度设置为 2048 tokens,充分利用 BGE‑M3 模型处理长文本的能力。
- 学习率与训练周期 如设置学习率为 1e-5,训练 5 个 epoch,以确保模型平稳收敛。
- 知识蒸馏与损失函数 启用知识蒸馏(参数
knowledge_distillation True),并采用适用于 Embedding 模型的损失函数(如 m3_kd_loss)来优化模型。- 梯度累积与混合精度 通过设置
gradient_accumulation_steps、启用--fp16和--gradient_checkpointing等,达到训练稳定性与显存使用之间的平衡。- 其他优化策略 如归一化 Embedding 向量(
normalize_embeddings True)和跨设备负样本构造(negatives_cross_device),进一步提升训练效果。
推理
建立在训练完成的基础上,将训练好的模型应用于新的、未见过的数据。模型利用先前学到的规律进行预测、分类或生成新内容,使得AI在实际应用中能够做出有意义的决策,例如在医疗诊断、自动驾驶和自然语言理解等领域。
在推理阶段,训练好的模型被用于对新的、未见过的数据进行预测或分类。大型模型在推理阶段可以处理各种类型的输入,并输出相应的预测结果。推理可以在生产环境中进行,例如在实际应用中对图像、语音或文本进行分类,也可以用于其他任务,如语言生成、翻译等。
这两个关键能力的有机结合使得AI模型成为企业数据分析和决策的强大工具。
通过训练,模型从历史数据中提取知识;通过推理,将这些知识应用于新场景,从而做出智能决策。
self-attention
Self-Attention & Transformer完全指南:像Transformer的创作者一样思考 - 知乎
单头注意力
vector之间的关联度(attention score)用来表示,的计算方式:
dot product:两个向量分别乘以得出q k向量,然后做点积获得相似度
然后做一层soft-max: 。
计算v向量:,
计算b向量 计算时是并行处理的 。
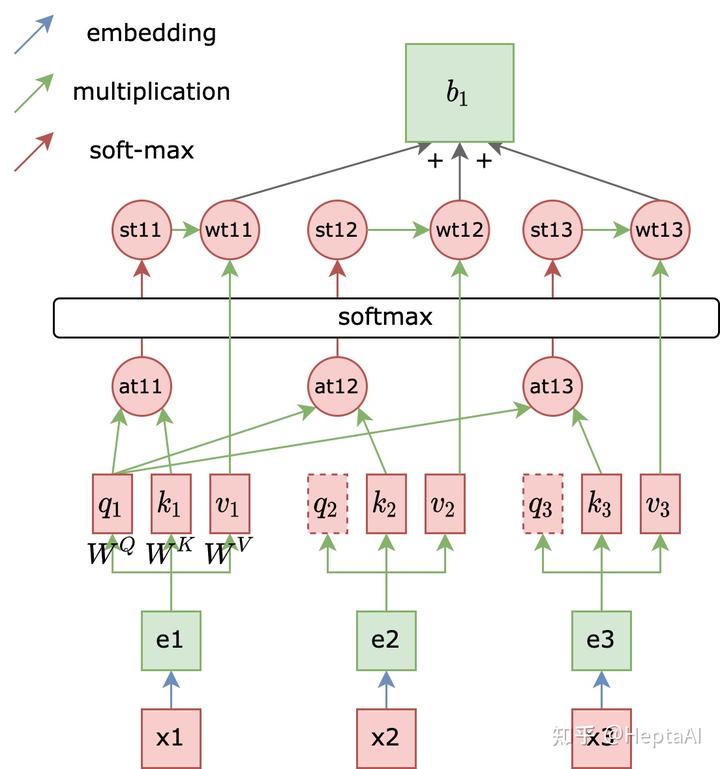
qkv是token x 在隐空间的某种语义表示。
输出的token不依赖于任何上一时刻的状态,因为使用了position embedding使得模型能够感知token的相对位置信息。
以矩阵的角度理解self-attention:
d就是d_model也就是embedding_size。
n是token个数。
X矩阵是将所有的token的embedding矩阵横着拼在一起。
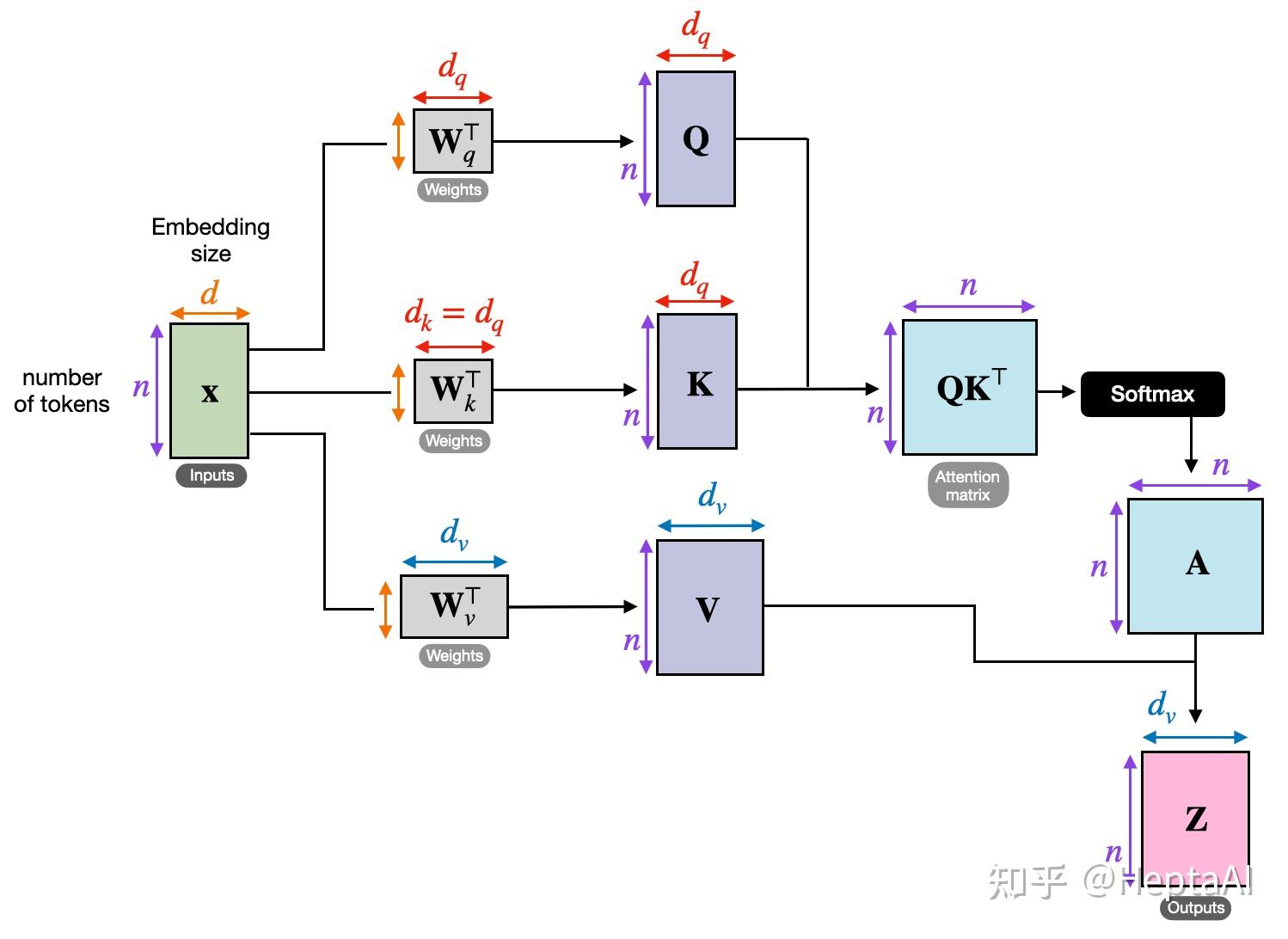
self-attention的本质,由于QKV是将X做线性变换映射到隐空间中增加特征,故我们可以先舍去QKV来看本质:
其中经过展开会发现是每一个token和所有token做内积(token实际上在这里已经被embedding),而做内积的结果即是两个向量的相似度,也可以理解为一个向量对另一个向量的关注程度。
做了softmax后,矩阵A的每一行也就是对的关注分数,每一行的和为1。
最后将softmax后的关注度矩阵和X矩阵相乘后就得到了赋予注意力的embedding矩阵。
多头注意力

在单头注意力的基础上,采用多个独立无关的权重矩阵完成多个方向的注意力计算。
每个注意力头都有自己的权重矩阵QKV,是相互独立的,用于学习不同的特征。
为什么每个注意力头计算的是整个嵌入向量,但是d_k=d_model / h
每个注意力头(共
h个)都会接收完整的d_model维嵌入向量作为输入,但通过独立的线性变换矩阵(例如W^Q,W^K,W^V)将输入投影到维度为d_k = d_model / h的子空间中。例如,若d_model=512且h=8,则每个头处理512维输入,但投影后的Q/K/V维度为512/8=64。每个注意力头通过自己独特的权重矩阵,将embedding投影到不同的子空间中,计算不同的注意力值。
投影到子空间本质上是一种 特征解耦 技术,让模型能并行地从不同角度分析信息,类似人类多任务协同的工作方式。
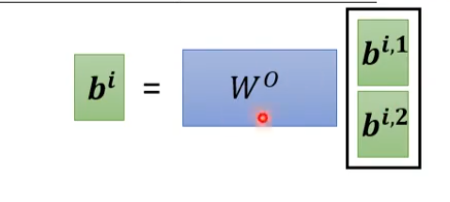
然后乘上权重矩阵,将多个注意力计算的结果整合。
常见参数含义
d_model: 模型中向量的维度大小,定义了模型内部每一层的大小
嵌入层的大小
在模型的输入端,单词或其他类型的标记会被转换为固定大小的向量。
d_model就是这些向量的维度。embedding_size在Transformer 模型的上下文中,嵌入层的大小通常与模型中其他部分的大小一致,这是为了保持信息在模型中流动时的维度一致性。
自注意力机制的大小
在自注意力层中,
d_model决定了查询(Query)、键(Key)、值(Value)向量的维度。这些向量的大小直接影响了模型处理信息的能力。然而,自注意力机制内部还涉及到一些其他的维度,如
d_k和d_v(分别代表键和值的维度),在一些变体中,这些维度可能会与d_model不同,特别是当使用多头注意力时,d_k和d_v可能会被设置为d_model除以头数的结果。前馈网络的输入和输出大小
在Transformer模型的每个编码器和解码器层中,都包含有一个前馈神经网络(Feed Forward Neural Network, FFNN)。这个网络的输入和输出层的维度通常也是
d_model。 这是为了保证信息能够顺畅地在模型层之间传递。然而,前馈网络内部的隐藏层的维度(通常表示为d_ff)通常是d_model的几倍,这样做是为了在模型内部提供更多的表示空间,从而捕获更复杂的特征。h:指的是注意力头数。
d_k(head_size):指的是每个单头中
qk向量的维度
Tokenizer与Embedding
从词到数:Tokenizer与Embedding串讲 - 知乎
Tokenizer:
将一串字符串进行切割为Token,不一定是单词。GPT家族使用BPE,具体参见上文。
embedding:
而ELMo之后则爆发了直接将embedding层和上面的语言模型层共同训练的浪潮(ELMo的全名就是Embeddings from Language Model)。Bert的第一层就是embeddings层。
在Tokenizer后,生成token的数字形式,然后生成独热编码。假设词汇表中有30k个 token,那么该独热向量的长度就是30k。假设输入的token数量为4(也就是n),那么经过tokenizer后shape就是(4,30K)。假设我们需要将其降维到embedding_size为768,也就是经过embedding后的shape为(4,768),那么我们需要训练的embedding参数矩阵的shape就是(30k,748),即Bert的embedding层大小。
embedding的本质就是查表,具体的可以看上面的文章。
KV cache
由于self-attention是自回归任务,我们每次的输出只需要最后一个token,再配合上masked-self-attention,使得前面的token无需对后面的token做attention计算,我们也就无需再缓存前面token的Q了,只需缓存前面token的kv和最后token的q做attention计算即可得到预测向量
position encoding
基础的self-attention并没有关于位置的信息,vector出现在序列的前方或后方,可能会影响最终的结果。
self-attention与CNN
CNN是self-attention的特例,self-attention在一定的约束条件下可变为CNN,self-attention相当于让机器自己学习卷积核的大小。
故在数据量较小的情况下,CNN这种复杂性较低的模型有更好的性能。
self-attention与RNN
最主要的区别是RNN无法做到并行处理,只能串行。
GPT&实战
对于Transformer的优化
将LayerNorm提前
引入final LayerNorm
使用tan近似的GELU代替RELU
将embedding层和lm_head共享参数(实际是transformer做的)
实战注意点
数据类型
FP,TP,BF
int8适用于推理

e代表指数位数,m代表精度位数。
torch.set_float32_matmul_precision(precision: Literal[
'highest', # 最高精度, 默认值
'high', # 高精度
'medium', # 中精度
] = 'highest')
GPT-2的参数初始化
https://www.bilibili.com/video/BV12s421u7sZ?t=4453.5
同步问题
在完成一次optimizer.step()后,GPU实际上并没有完成计算,可能还在队列中,我们可以调用: torch.cuda.synchronize()同步等待计算完成。
model = torch.compile(model)
降低python解释负载,减少GPU IO
transformr
seq2seq模型,输入和输出长度未知,输出长度由机器自己决定,可以将任何数据都看作sequence,例如图像,声音等。
end2end模型,如语音翻译功能,模型直接获取语音数据,直接输出文本数据,避免多个模块协同处理带来损耗。
AR模型,一个token一个token的进行推理,循环输入。
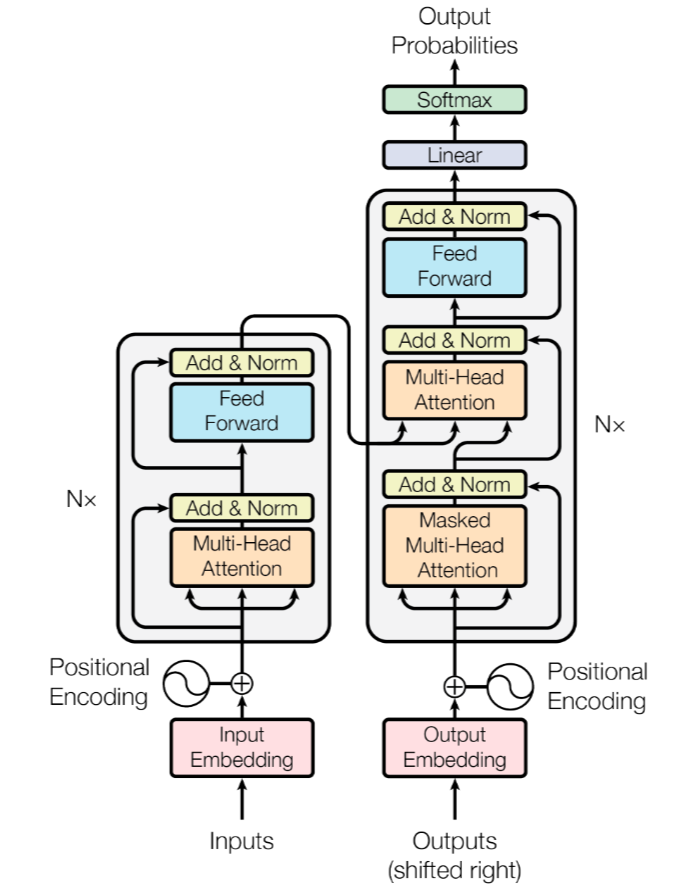
transformer由左边N个无关的encoder和右边N个无关的decoder组成。
什么是编解码
将一系列输入经过数字化,保留其语义和输入之间的相对关系。将输入投影到潜空间,潜空间是连续的,对于没有学习过的情况,也可以推测出来。
encoder
encoder具体细节如下图:

首先对输入向量做self-attention,然后进行一步残差连接和层归一化(区别于BN)处理,之后放入一个前馈神经网络(FFN),之后在进行一个残差连接与层归一化(区别于BN是对一个batch内的一个维度做归一化,层归一化是对一个序列内做归一化)获得最终的encoder输出。
FFN
Transformer前馈神经网络两层结构: 包括两个线性变换,并在它们之间使用ReLU激活函数。两个线性层的差异主要体现在它们的作用和维度变化上。
第一层线性变换负责将输入映射到更高维度的空间,并引入非线性;而第二层线性变换则负责将输出映射回与输入相同的维度(或兼容的维度),通常不引入额外的非线性。
第一层线性变换:这是一个全连接层,它接收自注意力层的输出作为输入,并将其映射到一个更高维度的空间。这个步骤有助于模型学习更复杂的特征表示。
激活函数:在第一层全连接层之后,通常会应用一个非线性激活函数,如ReLU(Rectified Linear Unit)。ReLU函数帮助模型捕获非线性关系,提高模型的表达能力。
第二层线性变换:这也是一个全连接层,它将前一层的输出映射回与输入相同的维度(或与模型其他部分兼容的维度)。这一层通常没有非线性激活函数。
attention是通信,而MLP是映射
decoder
transfomer是一种自回归的解码器,推理过程如下:

整体来说,decoder接受来自encoder的输出和decoder以往的输出,通过softmax获取预测向量,输出最大概率的token。
将decoder拆开,第一层是masked attention,由于在推理第一个token时,后面的token还不存在,故设置掩码,防止前面token推理的注意。
第二层是一个名叫cross attention的注意力层,其中encoder的输出向量生成k v向量,而decoder的masked attention层的输出向量生成q向量,对其进行cross attention。
第三层和encoder相同。
最后通过一个全连接层生成logits向量,通过softmax生成概率。
训练过程
以语音辨识为例,给出语音和文本对应的资料,在训练过程中,decoder的循环输入不会使用自己的输出,而是使用正确的答案,这被称为teacher forcing。但是在推理过程中,我们无法预知正确答案,为了更好的训练模型,在训练过程中通常会随机的改变decoder的循环输入(扰动),以增强模型的性能。
最终的输出是一个概率向量,类似于分类问题,我们可以使用交叉熵损失函数进行训练。
为什么要除以d_k
- 当 dk变大时,Q 和 K 的点积的方差也会变大,导致点积值的差异增大。
- 差异增大后,softmax 函数的输出会趋于one-hot 编码,即最大值接近 1,其他值接近 0,这使得 softmax 的梯度趋于 0,从而导致梯度消失问题。
- 缩放实际上是将点积归一化为均值为 0、方差为 1 的标准分布
BERT
bert是一种encoder-only的架构,是由transformer中的encoder堆叠而成。采用预训练-微调的训练过程,预训练采用大量无需标注数据的自监督学习,微调采用少量domain标注数据进行监督学习。
预训练
预训练包括两个自监督过程:
MLM
对输入采用masking input(special token,random mask token)随机mask一些input,使用[MASK]表示。让bert根据上下文信息预测mask的内容,类似于完形填空。

NSP
给定两个句子,判断句子B是否是句子A的下一句,使用[SEP]分割句子。每个句子以[CLS]开头,其输出可用于分类任务的输出,同时也可用于下游任务(downstream-work)。

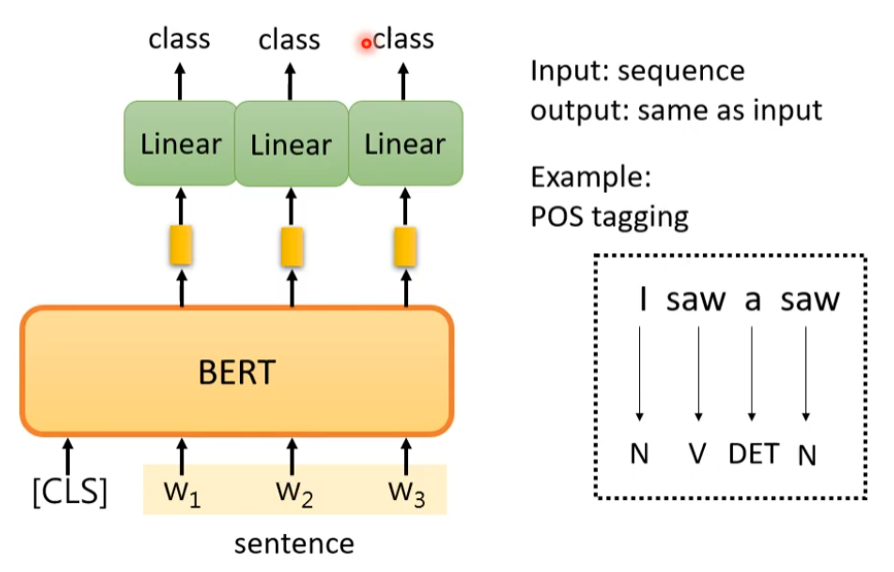
微调
根据下游任务的不同,会对bert采用不同的微调策略。
情感分析

词性标注
基于文本的问答
给定一个文本和问题,答案必须能够在文本中直接找到。
输入D Q向量集合,输出两个数字,表示答案在文本的起始和中止的位置。

在训练过程中,还需要学习两个额外的向量,对于document输出的向量,分别和这两个向量做点积,分别获取获取两个概率最大的位置,即为结果。

RAG
LLM问题:hallucination, outdated,a lack of verifiable reasoning
是从知识库中检索到的context,增强了LLM的提示词(prompt),LLM拿着增强后的Prompt生成了问题答案
chunk
固定分块:
选择合适的分块:文本的特性,embedding模型的特性(BERT是512 token,所以chunk_size通常设为400-500字。而overlap一般设为chunk_size的10%-25%,比如对于512的块,重叠50-128字。),query特性,LLM的token限制。
chuk_size:256,chunk_overlap:20
基于语义:基于标点符号,使用NLP工具包(NLTK)
特定的处理:md,latex
embedding
将高维离散数据映射到低维连续向量空间的技术,将一系列输入经过数字化,保留其语义和输入之间的相对关系。将输入投影到潜空间,潜空间是连续的,对于没有学习过的情况,也可以推测出来。
模型用的BGE-M3(BAAI General Embedding),将文本嵌入为稠密向量(dense vector)和稀疏向量(Sparse vector)
向量数据库
草履虫都看得懂的向量数据库教程,一文就够了_向量数据库使用-CSDN博客
ANN
pre-retrieve
Query Transformations:base on history,sub-query,假设文档嵌入 (HyDE,大模型生成假设性答案,问题和假设性答案一起检索),Small2Big(匹配一段文本,返回周围的文本)
检索
元数据:检索时可通过meta data先过滤,例如检索time range内的chunk,确保是新鲜的信息。
文本相似性:
tf-idf
tf:词频,即词组在该文档出现的次数,idf:逆文档频率(log(文档总数/含有该词的文档数量+1))
tf-idf = tf * idf
为什么使用log:
首先对于那些词频特别高,几乎每个文档都有的词条t(如“的”,“是”),文档集中含t的数量约等于总的文档集数量,即N/n=1(N/n恒大于1)。在只使用TF的情况下,t所占的权重很大,但是它并没有区分能力,与我们的期望不符。使用IDF(带对数函数)之后,由于log(1) = 0,则t通过TF-IDF计算出的权重就为0(根号就达不到这样效果),符合我们的期望。 另外一个原因就是,使用log可以防止权重爆炸。如果某些词只出现一篇或者少数几篇文档中(比如错别字),在没有log的情况下,IDF就会非常的大(分母过小),从而影响其权重,而使用log能减轻这种影响。
BM25
引入k1和b参数
k1:词频的饱和化处理,避免过度堆砌关键词对最终的影响。
b:通过b参数对文档的长度进行归一化,避免长文档对最终结果的影响。
倒排索引
数据结构:
- 词典(Term Dictionary) :存储所有唯一的关键词(如“苹果”、“手机”)。Trie树
- 倒排列表(Posting List) :每个关键词对应一个列表,记录:
优势:
- 快速查找:通过关键词直接定位文档,时间复杂度接近O(1)。 比如搜索“苹果”,直接返回文档1和3,无需遍历所有文档。
- 支持布尔查询:通过倒排列表的交集(AND)、并集(OR)操作实现复杂查询。 例如:“苹果 AND 手机” → 取"苹果"和"手机"列表的交集(文档1)。
- 高效压缩:倒排列表(文档ID)通常用差值压缩存储(如Delta Encoding),节省空间。 例如文档ID列表[100, 200, 300]可存储为[100, 100, 100]。
- 支持排序:结合TF-IDF、BM25等算法,为搜索结果排序提供基础数据。
假设有以下3个文档:
文档1:苹果手机评测
文档2:华为手机降价
文档3:苹果发布会新品
倒排索引的构建结果:
"苹果" → [文档1(词频1), 文档3(词频1)]
"手机" → [文档1(词频1), 文档2(词频1)]
"评测" → [文档1(词频1)]
"华为" → [文档2(词频1)]
"发布会" → [文档3(词频1)]
正排索引就是:
文档一:苹果,手机,评测
...
...
向量相似性:
稀疏检索(Sparse Retrieval, SR):将文档投射到一个稀疏向量上,顾名思义,这个稀疏向量通常与文档的语言词汇一致。查询与文档表示为高维稀疏向量(维度对应词典中的词项,非零值表示词频或TF-IDF权重)。
稠密检索(Dense Retrieval, DR):将documents编码为低维稠密向量(Dense Vector),通常使用的是[CLS]表示法将整个文本嵌入到一个向量中。
相似度:
cos:忽略向量长度,专注方向一致性(适合文本语义匹配)。
dot product:同时受向量方向和长度影响。若向量已归一化(L2范数为1),点积等价于余弦相似度,结合长度信息的排序(如商品价格与用户偏好加权)。
L2:衡量绝对空间距离,对向量各维度敏感。
曼哈顿距离:对高维稀疏数据更鲁棒
多路召回,混合检索:
- 基于关键词的召回:依赖倒排索引,快速定位包含精确词项的文档(如BM25算法)。
- 基于向量的召回:利用稠密向量(如BERT)或稀疏向量(如Splade)的相似度计算,捕捉语义相关性。
- 基于知识图谱的召回:通过实体关系索引回答结构化问题(如“苹果公司的CEO是谁?”)。
- 动态路由机制:根据查询复杂度自动选择最优召回路径(如简单查询走关键词召回,复杂语义查询走向量召回
粗排,RRF:
- N:参与融合的检索系统数量(如A、B两路)。
- ranki(d):文档d在第i个检索系统中的排名(未出现则视为无穷大)。
- k:平滑参数,通常设为60(经验值),用于调节低排名文档的贡献衰减速度、
- 用于调节多路召回比重,和为一。
强调高排名文档、无需得分归一化。
post-retrieve
rerank:微调rerank模型,cohere-rerank
上下文压缩
- 一个是避免prompt超长,超过LLM的窗口限制
- 另一个是找到基础信息,强调关键信息,将不相关的内容压缩、精简、淡化
精排
评估
Hit Rate即命中率,一般指的是我们预期的召回文本(真实值)在召回结果的前k个文本中会出现,也就是Recall@k时,能得到预期文本。一般,Hit Rate越高,就说明召回算法效果越好。
MRR即Mean Reciprocal Rank,是一种常见的评估检索效果的指标。MRR 是衡量系统在一系列查询中返回相关文档或信息的平均排名的逆数的平均值。例如,如果一个系统对第一个查询的正确答案排在第二位,对第二个查询的正确答案排在第一位,则 MRR 为 (1/2 + 1/1) / 2。
在N个查询中,每个理应在首位的文档的排名的倒数和。
| hit_rate | mrr | |
|---|---|---|
| bm25_top_1_eval | 0.7975 | 0.7975 |
| embedding_top_1_eval | 0.6075 | 0.6075 |
| ensemble_top_1_eval | 0.7009 | 0.7009 |
| ensemble_rerank_top_1_eval | 0.8349 | 0.8349 |
ResNet
单纯加深网络层数可能会导致模型偏差,模型退化(和过拟合区别)
Sparse Attention
Flash Attention
MOE COT
glove word2vec
评价标准
混淆矩阵 TP TN FN FP
常用于有监督学习,处理分类问题。
第一个字母表示是否正确预测,第二个字母表示预测的类别。
如果有癌症记为一positive,无癌症记为零negative,则:
| 实际\预测 | 有癌症(1) | 无癌症(0) |
|---|---|---|
| 有癌症(1) | TP | FN |
| 无癌症(0) | FP | TN |
对角线的两个元素TP TN就是预测正确的数量。
准确率 (Accuracy)
即在所有的预测中中判断正确的:
当数据集类别不平衡时,准确率可能会产生误导。例如,在一个极端类别不平衡的情况下(例如,99% 样本为负类),即使模型总是预测为负类,它也能得到很高的准确率,但实际模型性能可能很差。
精确率 (Precision)
所有判断为positive样本中,真正为positive的比例:
适用于positive预测错误代价高的场景,要降低预测错误的概率,预测错误如将正常邮件(negative)识别为垃圾邮件(positive),可以承受少量漏报。
召回率 (Recall)
即所有真正为positive的样本中,判断为positive的比例:
适用于漏报代价高的场景,要降低漏报的概率,如入侵检测,癌症检测等。
F1-score
F1-score 是精确率和召回率的调和平均数,综合考虑了精确率和召回率的平衡。
数学
- 讲解熵,交叉熵,KL散度:链接: pan.baidu.com/s/1oCwpVY 提取码: tde7
标准差&方差
方差是一组数据与该组数据平均值之差的平方数的平均值。标准差是其开根。
- 方差,标准差,均方差:方差、标准差(均方差)、均方误差、均方根误差 - 知乎
大数定理
当样本数量足够多时,样本均值收敛于期望值
信息量
概率越小的事件,信息量越大,越惊喜(surprisal),取lb是为了使得独立事件的信息量可以相加。
信息熵
针对一个分布,其平均信息量(信息量的期望值)为该概率分布的熵:
交叉熵
交叉熵即两个分布的跨分布度量:
交叉熵是大于等于熵的。
具体到神经网络的二分类问题上,即为:
KL散度
用于衡量两个分布的近似程度:
该公式表示了使用分布Q来近似分布Q的效率,在训练中,只有Q有关于参数,第二项H(P)对参数求导后为零,故损失函数可直接写作交叉熵。
- KL散度是不对称的:从交叉熵的定义很容易得出
- KL散度大于等于零:
- 当
P = Q时,KL散度为零 - 当
P != Q时,熵是最小的平均无损编码,也就是交叉熵减去熵大于等于零
- 当
牛顿迭代法
通过将问题转化为方程,将函数进行泰勒展开到一阶,简化问题的计算:
若要求的大小,则可转化为求方程的根,将其泰勒展开
进行化简则有
再将不断进行迭代,直到迭代的变化小于精度。
牛顿迭代法的好坏很大程度上依赖于的取值,同时也受到函数形态的限制:
- 在迭代点处一阶导数值不能太小。
- 在迭代点处二阶导数值不能太大。
期望

大数定理
当样本数量足够多时,样本均值收敛到总体均值。
中心极限定理
样本的均值与总体的平均值类似,且呈现正态分布。
极大似然估计
提供了一种给定观察数据来评估模型参数的方法。也就是似然函数的直观意义是刻画参数 与样本数据的匹配程度。
Wait
训练和推理时不同:dropout,batchnorm
ANN
对于vocab_size=50257,初始loss应该在证明参数足够随机:
假设模型预测概率分布 与真实概率分布
因为即lable一般是独热编码,对于交叉熵的的公式:可以简化为
所以初始loss应该为
超参数设置
八股
梯度消失
- 隐藏层的层数过多,反向传播求梯度时的链式求导法则,某部分梯度小于1,则多层连乘后出现梯度消失
- 采用了不合适的激活函数,如sigmoid函数的最大梯度为1/4,这意味着隐藏层每一层的梯度均小于1(权值小于1时),出现梯度消失。
解决方法:
relu激活函数,使导数衡为1
batch norm
残差结构
梯度爆炸
- 隐藏层的层数过多,某部分梯度大于1,则多层连乘后,梯度呈指数增长,产生梯度爆炸。
- 权重初始值太大,求导时会乘上权重
解决方法:
- 梯度裁剪
- 权重L1/L2正则化
- 残差结构
- batch norm
过拟合
原因:
数据噪声太大
特征太多
模型太复杂
解决方法:
增强数据。
减少模型参数,降低模型复杂度。
正则化。
欠拟合
欠拟合原因:
- 训练样本数量少
- 模型复杂度过低
- 参数还未收敛就停止循环
欠拟合的解决办法:
- 增加样本数量
- 增加模型参数,提高模型复杂度
- 增加循环次数
- 查看是否是学习率过高导致模型无法收敛
模型退化
如果在无论是训练集还是数据集,模型性能都不好则可能是发生了模型退化。ResNet引入残差连接(residual connection)。残差连接的基本思想是将输入信息直接传递到输出,使得网络在训练过程中能够学习到输入与输出之间的残差关系,从而减轻网络学习的负担。具体来说,假设原始网络的映射关系为H(x),我们将其拆分为两部分:F(x)和x。其中,F(x)表示网络需要学习的映射关系,x表示输入信息的直接传递。这样,原始网络的映射关系就可以表示为H(x) = F(x) + x。通过这种方式,网络只需要学习F(x)与x之间的残差关系,从而降低了学习难度。
数据增强
- 反转,裁剪,缩放,旋转,高斯噪声,颜色
- 同义词替换,随机(插入,删除,交换),回译
正则化
dropout
随机的使得某些神经元失效,增强模型的鲁棒性,只在训练时生效。
标准化
神经网络训练过程中,由于每一层的参数不断更新,导致网络各层的输入数据分布持续变化。这种分布的变化会使得网络层需要不断适应新的数据分布,从而降低学习速度,增加训练难度。数据分布改变。
BN
在一个维度上做标准化,BN对batch比较敏感,batch_size不能太小;训练和推理行为不一致
LN
在一个样本内部做标准化,对batch不敏感,训练和推理行为一致。
如果NLP领域使用BN,会破化一个句子的语义。