本章对分布式有了一个简单的介绍,同时讲解了Google开源的MapReduce。
分布式系统简介
分布式系统就是由若干只能通过网络进行通信交互的系统构成的系统。
为什么使用分布式系统
- sharing:系统之间资源共享
- 大量数据的并行计算
- 提高系统容错(如果是单机系统,一旦出故障即服务完全不可用)
挑战
- 高并发场景
- 机器故障(网络分区)
- 性能
基础设施
- 存储(storage):文件系统,kv存储
- 计算(computation):计算框架,如MapReduce
- 通信(communication):网络通信,如RPC
主题
- 容错(fault failure)
- 高可用(availability):复制技术
- 恢复(recoverability):日志(redo),事务,参见ostep-persistence中的崩溃日志一章。
- 一致性(consistency)
- 强一致性:多个机器的行为像串行一样。
- 最终一致性:只保证最后一个行为之后机器的状态一致,过程不保证
- 性能(performance)
- 吞吐量(throughput)
- 低延迟(latency):尾部延迟(tail latency)
分布式系统无法同时兼顾三点,一般的分布式系统会根据应用场景选择其中的两点满足。
MapReduce
MapReduce 就是为了编写在普通机器上运行的大规模并行数据处理程序而抽象出来的编程模型,为解决多机并行协同,网络通信,处理错误,提高执行效率 等通用性问题的一个编程框架。
逻辑流程
程序员通过编写无状态的map和reduce函数实现分布式的数据处理,由MapReduce来实现分布式的细节。

上图是MapReduce的最常见应用,采集文件中单词的个数。其中用户只需要编写Map函数,切割文件,获取文件单词个数,以及编写Reduce函数,将values累加即可。
map(String key, String value):
// key: document name
// value: document contents
for each word w in value:
EmitIntermediate(w, "1");
reduce(String key, Iterator values):
// key: a word
// values: a list of counts
int result = 0;
for each v in values:
result += ParseInt(v);
Emit(AsString(result));
其中Shuffle是将每个Map worker生成的k/v对按需排列,以便Reduce使用。
我们可以将上述流程抽象为以下模型:
- map: (k1,v1) -> list(k2,v2)
- reduce: (k2,list(v2)) -> list(v2)
其中可以加上一层shuffle:
- shuffle: list(k2,v3) -> (k2,list(v2))
物理流程
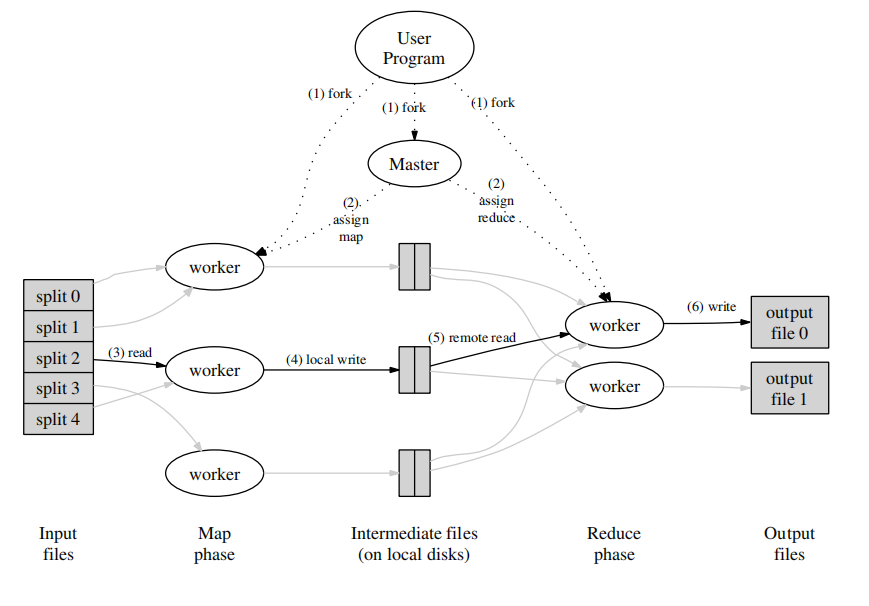
上面的图片是MapReduce-paper[1]的图片。

上面的图片出自MapReduce论文导读[2]。
注意,MapReduce在这篇论文中是和GFS联合起来用的,所以很多地方不需要进行网络通信,只在Reduce worker从中间文件中拉取数据时用到了RPC。
容错
worker容错
由于worker是无状态的,所以一旦master无法连接上worker,就认为出现了故障,将其他完成任务的同类型worker调用起来再次执行该任务。
master
一般master只有一个,不会认为它出现故障,一旦出现故障,一般的会选择重启整个任务。
掉队机制
同尾部延迟,如果一个worker能力较弱,同时又分配了较为多的任务,有可能影响到整个MapReduce,所以采用了backup task机制,存在一些备用worker执行剩下的任务。
MapReduce还有很多其他的机制,可以参见MapReduce-paper[1:1],以及MapReduce论文导读[2:1]。