并发吹剑录(一):CPU缓存一致性协议MESI - 知乎 (zhihu.com)
CPU中的缓存、缓存一致性、伪共享和缓存行填充 - 知乎 (zhihu.com)
2.4 CPU 缓存一致性 | 小林coding (xiaolincoding.com)
内存屏障(Memory Barrier)究竟是个什么鬼? - 知乎 (zhihu.com)
CPU Cache
首先引出现代CPU的架构:
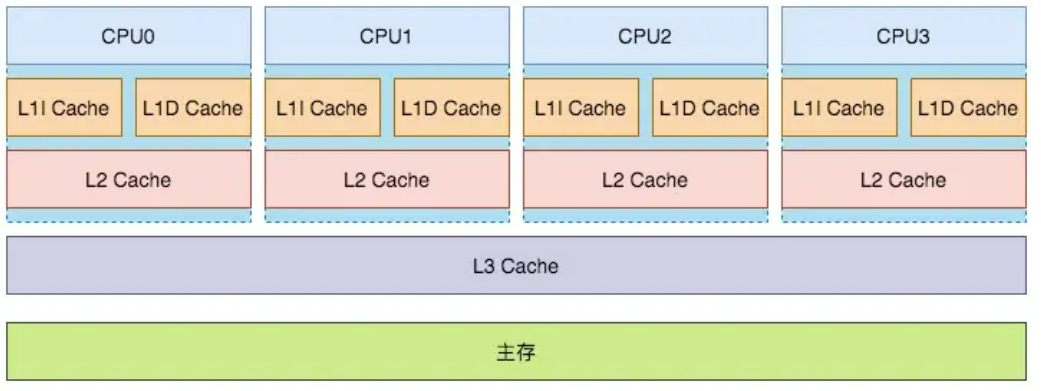
L1和L2都是片内缓存,只可由响应的CPU单独使用,而L3是由所有CPU所共享的。其中L1l是指令缓存,而L1D是数据缓存。缓存和主存都是RAM,只不过缓存时SRAM而主存时DRAM。
缓存的基本单位是缓存行,缓存行中包含一些头信息和具体的数据,头信息有很多,包括脏位等等。从主存中拿出一次就是拿出一行数据,可以通过下面的方式获取以字节为单位的缓存行的大小:
# L1D Cache
getconf LEVEL1_DCACHE_LINESIZE
# L1I Cache
getconf LEVEL1_ICACHE_LINESIZE
# L2 Cache
getconf LEVEL2_CACHE_LINESIZE
# L3 Cache
getconf LEVEL3_CACHE_LINESIZE
写缓存策略
这里涉及到计组的知识,写缓存包含两个策略:
- 写直达:每次写缓存后都直接写入内存中,保证数据一致性,但是xiaolv低下,每次写入不仅要访问缓存,而且要访问内存。
- 写回:写入缓存后,将脏位设置为1,不需要写入内存,当缓存块需要被替换下时,将缓存写回主存。
缓存不一致
由于写直达性能低下,一般采用写回法。但是这样就会引入CPU缓存不一致问题,设想当CPU1对数据x写入1,由于采用写回法,所以内存中的x依然为0。这时CPU2从内存中把x载入缓存中,读取的x就为0,现在就发生了缓存不一致的情况。
对于这种情况,我们要保证两点:首先要让CPU之间能够通信,也就是当CPU1修改x时,其他的CPU可以收到这个信息。一切的有序都要以沟通为基础,互相什么都不知道就无法保证有序和同步。
其次,我们需要将不同的CPU上的修改事件像数据库中的串行化一样执行,不然可能会出现以下情况:
首先CPU1将x改为1,通知其他的CPU。同时CPU2将x改为2,通知其他CPU。当CPU1发送通知时,占用总线,CPU2收到后将x改为1。当CPU1发送完毕后,CPU2发送通知,CPU1将x改为1,数据不一致的情况发生了。
总线嗅探
CPU感知其他CPU的行为(比如读、写某个缓存行)就是是通过嗅探(Snoop)线性中其他CPU发出的请求消息完成的,有时CPU也需要针对总线中的某些请求消息进行响应。这被称为”总线嗅探机制“。
总线嗅探上的六种消息如下:
Read: 读取某个地址的数据。目的地是其他的CPU和内存,包含待读取的数据地址。
Read Response: Read 消息的响应。包含数据内容,可能是内存返回的,也可能是其他CPU返回的。
Invalidate: 请求其他 CPU invalid 地址对应的缓存行。
Invalidate Acknowledge: Invalidate 消息的响应。
Read Invalidate: Read + Invalidate 消息的组合消息。
Writeback: 该消息包含要回写到内存的地址和数据。
MESI
接下来就要设计一种协议来保证修改的串行化,MESI协议是:
- Modified,已修改
- Exclusive,独占
- Shared,共享
- Invalidated,已失效
的缩写,代表缓存行的状态,存在于缓存行的Tag。
如果缓存行的状态是S或者E,代表可以当前缓存和主存中数据是一致的。
如果缓存行中的状态是E或者M,代表当前的读写操作可以直接对缓存进行。
由此可以看出,对于一个CPU来说,一个缓存行可能存在四种事件:本地读,本地写,远程读,远程写。
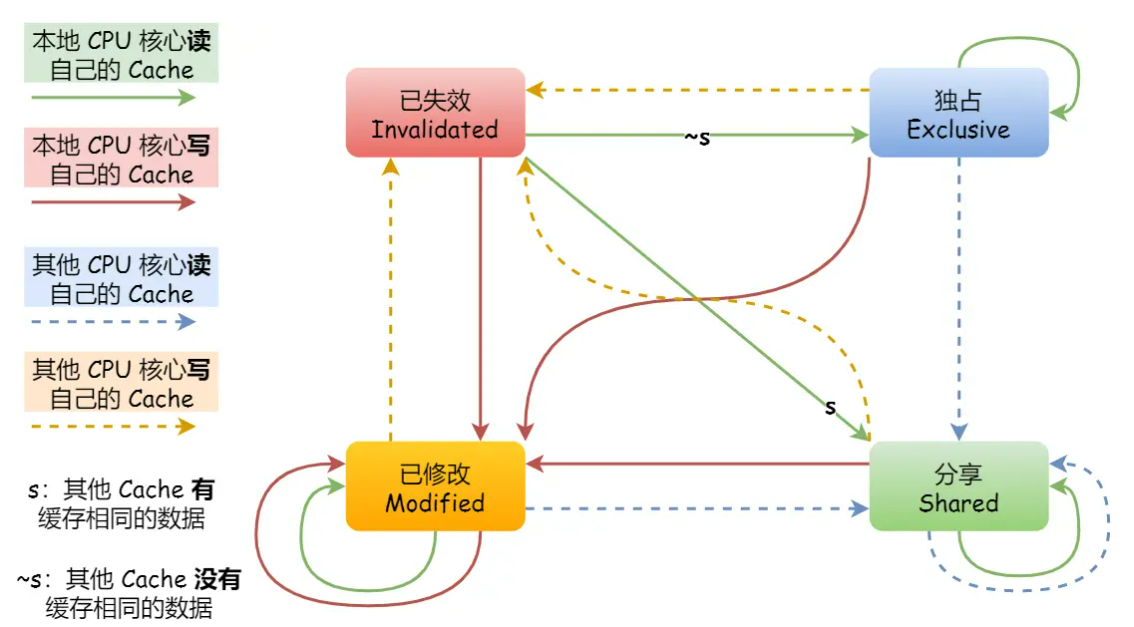
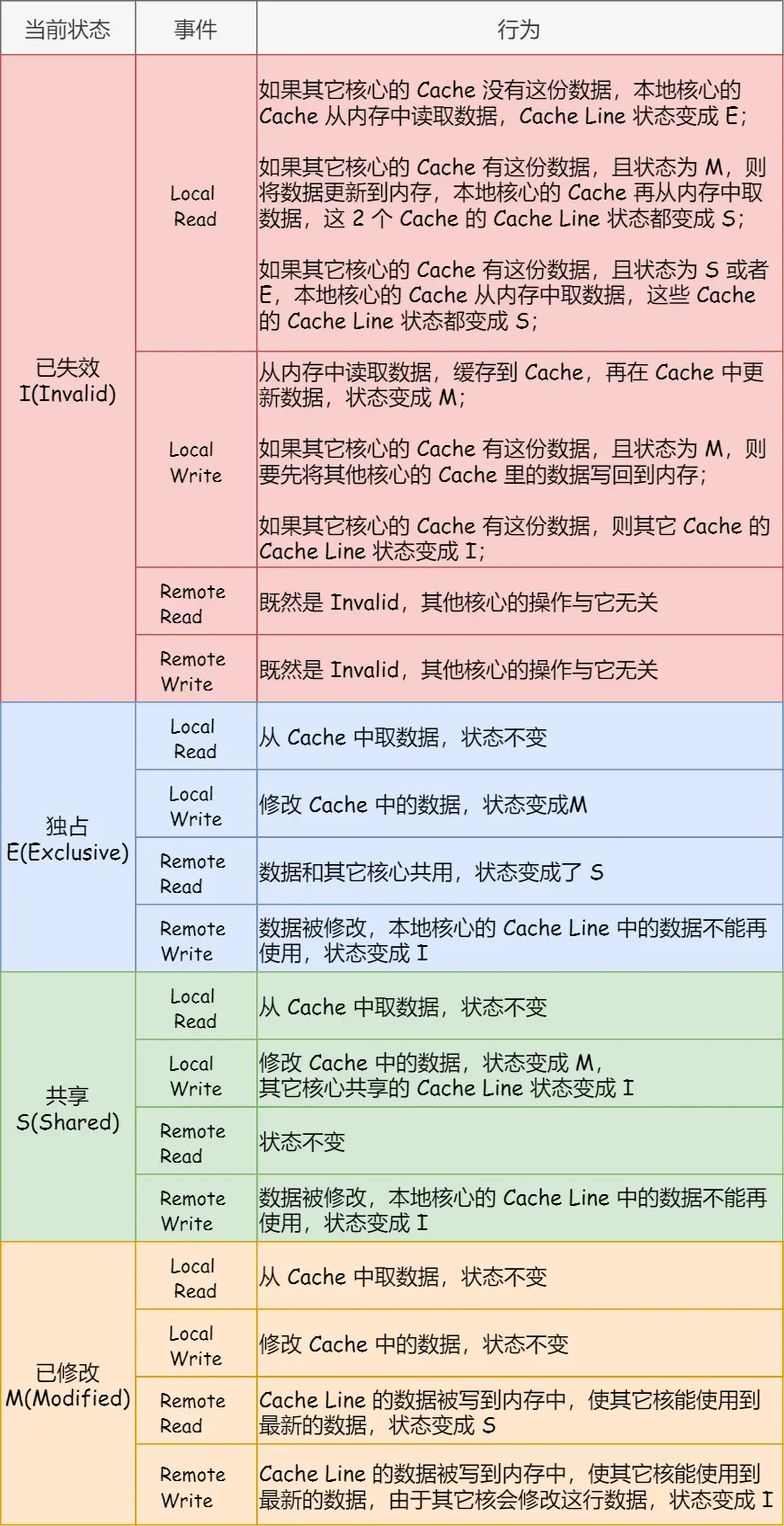
上面的图是缓存行的状态机表示图,下面的是整个流程的状态和数据的变化:
Store buffer
Store buffer是CPU和cache之间的一个缓冲区,CPU不会等待其他的CPU将信息发送过来才将缓存行改变,而是将要改变的值放入Store buffer中,等待其他CPU响应后,CPU才把数据写入缓存行中。所以CPU会先查Store buffer,再查cache(Store Forwarding)。
Invalided Queue
接收方的CPU存在一个队列,当收到其他CPU相关的Invalided消息后,将对应的缓存行放入队列中,然后就可以直接返回了。
一旦将一个invalidate(例如针对变量a的cacheline)消息放入CPU的Invalidate Queue,实际上该CPU就等于作出这样的承诺:在处理完该invalidate消息之前,不会发送任何相关(即针对变量a的cacheline)的MESI协议消息。
总线风暴
我们知道,多核处理器都是公用的同一个总线,如果一个CPU占用了总线,那么其他的CPU就不能够使用总线。对于多个线程操作同一个变量来说,我们可能会用到CAS机制,其中可能涉及到CPU的盲轮询,倒是总线上的缓存一致性流量激增,降低CPU的效率。
内存屏障
写内存屏障
在引入了Store buffer后,可能会出现下面的问题:
int a = 0 , b = 0;
void fun0() {
a = 1;
b = 1;
}
void fun1() {
while (b == 0) continue;
assert(a == 1); // error
}
CPU0执行fun0,拥有b的缓存,CPU1执行fun1,拥有a的缓存。
- CPU 0执行a=1的赋值操作,由于a不在local cache中,因此,CPU 0将a值放到store buffer中之后,发送了read invalidate命令到总线上去。
- CPU 1执行 while (b == 0) 循环,由于b不在CPU 1的cache中,因此,CPU发送一个read message到总线上,看看是否可以从其他cpu的local cache中或者memory中获取数据。
- CPU 0继续执行b=1的赋值语句,由于b就在自己的local cache中(cacheline处于modified状态或者exclusive状态),因此CPU0可以直接操作将b新的值1写入cache line。
- CPU 0收到了read message,将最新的b值”1“回送给CPU 1,同时将b cacheline的状态设定为shared。
- CPU 1收到了来自CPU 0的read response消息,将b变量的最新值”1“值写入自己的cacheline,状态修改为shared。
- 由于b值等于1了,因此CPU 1跳出while (b == 0)的循环,继续执行。
- CPU 1执行assert(a == 1),这时候CPU 1的local cache中还是旧的a值,因此assert(a == 1)失败。
- CPU 1收到了来自CPU 0的read invalidate消息,以a变量的值进行回应,同时清空自己的cacheline。
- CPU 0收到了read response和invalidate ack的消息之后,将store buffer中的a的最新值”1“数据写入cacheline。
总结来说就是CPU0对a的写操作还在Store buffer,对b的写却直接写入cache line,导致CPU1只拿到了b的最新值,而a的值还是cache line中的旧值。
所以在这里要引入写内存屏障(Store Memory Barrier)
int a = 0 , b = 0;
void fun0() {
a = 1;
smp_mb();
b = 1;
}
void fun1() {
while (b == 0) continue;
assert(a == 1);
}
写内存屏障保证了数据在本地cache中的操作顺序是和程序相同的,在上文中就是必须要a=1写入cache line完毕后,才能执行b=1写入cache line。
一种做法是,直接清空Store buffer,CPU等待所有Store buffer中的数据写入cache line后再执行下一条指令。
另一种做法是记录Store buffer中的顺序,并且对需要等待表项marked,并且当Store buffer中含有数据时,即使下一条指令的数据存在cache line中,也需要加入Store buffer,只不过不需要marked。
读内存屏障
上面的做法仍然有问题:
a = 0 , b = 0;
void fun0() {
a = 1;
smp_mb();
b = 1;
}
void fun1() {
while (b == 0) continue;
assert(a == 1);
}
假设 a 存在于 CPU 0 和 CPU 1 的 local cache 中,b 存在于 CPU 0 中。CPU 0 执行 fun1() , CPU 1 执行 fun2() 。操作序列如下:
CPU 0执行a=1的赋值操作,由于a在CPU 0 local cache中的cacheline处于shared状态,因此,CPU 0将a的新值“1”放入store buffer,并且发送了invalidate消息去清空CPU 1对应的cacheline。
CPU 1执行while (b == 0)的循环操作,但是b没有在local cache,因此发送read消息试图获取该值。
CPU 1收到了CPU 0的invalidate消息,放入Invalidate Queue,并立刻回送Ack。
CPU 0收到了CPU 1的invalidate ACK之后,即可以越过程序设定内存屏障(第四行代码的smp_mb() ),这样a的新值从store buffer进入cacheline,状态变成Modified。
CPU 0 越过memory barrier后继续执行b=1的赋值操作,由于b值在CPU 0的local cache中,因此store操作完成并进入cache line。
CPU 0收到了read消息后将b的最新值“1”回送给CPU 1,并修正该cacheline为shared状态。
CPU 1收到read response,将b的最新值“1”加载到local cacheline。
对于CPU 1而言,b已经等于1了,因此跳出while (b == 0)的循环,继续执行后续代码。
CPU 1执行assert(a == 1),但是由于这时候CPU 1 cache的a值仍然是旧值0,因此assert 失败。
Invalidate Queue中针对a cacheline的invalidate消息最终会被CPU 1执行,将a设定为无效。
总结来说就是当引入Invalided Queue后,我们的Invalided Queue中的失效信息不是实时和Cache line匹配的,当我们将失效信息放入队列中时,我们仍然读的是cache line中的旧数据。
所以需要引入读内存屏障(Load Memory Barrier)
a = 0 , b = 0;
void fun0() {
a = 1;
smp_mb();
b = 1;
}
void fun1() {
while (b == 0) continue;
smp_rmb();
assert(a == 1);
}
当CPU执行memory barrier指令的时候,对当前Invalidate Queue中的所有的entry进行标注,这些被标注的项被称为marked entries,而随后CPU执行的任何的load操作都需要等到Invalidate Queue中所有marked entries完成对cacheline的操作之后才能进行。也就是所有的读操作,都需要queue清空,将失效信息放置到cache line后才可以进行。