本章介绍有关于MySQL索引的相关知识。
索引(index)是帮助MyQL高效获取数据的数据结构(有序。在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据, 这样就可以在这些数据结构上实现高级查找算法,这种数据结构就是索引。

索引结构

B+Tree
谈起搜索树,首先会从二叉搜索树看起:通俗易懂讲解 二叉搜索树,但是二叉搜索树会有两个缺点:
- 当顺序插入时,二叉搜索树会退化为一个链表,搜索时间复杂度退化为
- 对于大量数据,树的层级加深,检索速度慢
为了解决这些缺点,这里引入了B-树(多路平衡查找树)。
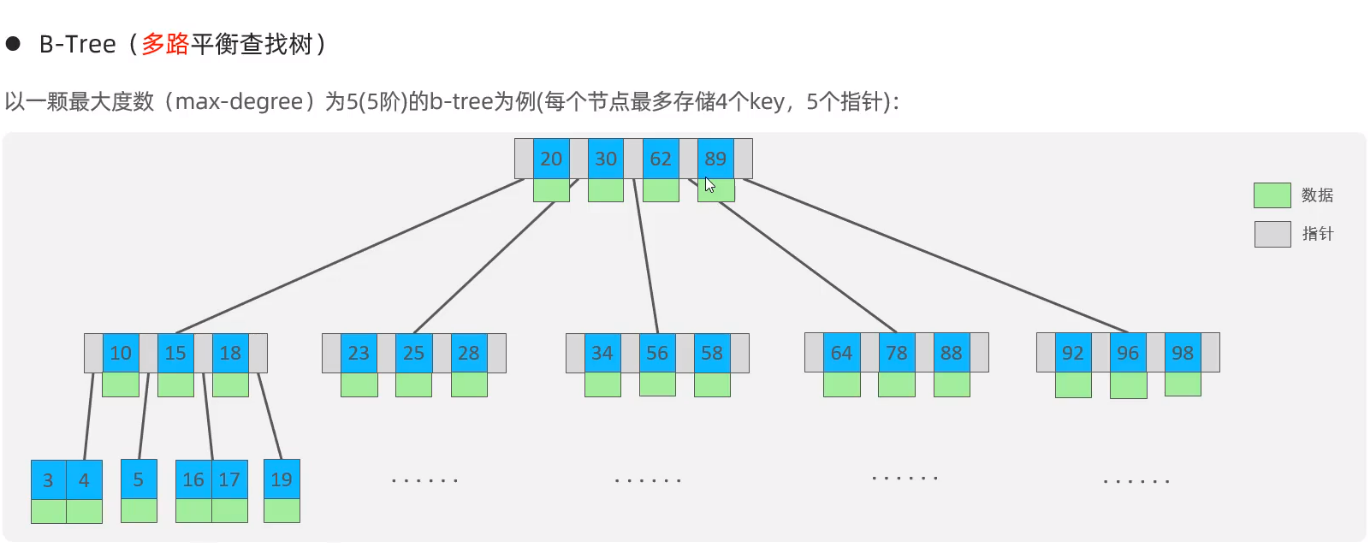
B-树是专门为外部存储器设计的,具有磁盘友好性,它对于读取和写入大块数据有良好的性能,所以一般被用在文件系统及数据库中。
而B+树是B-树的变体,不同之处在于
- 所有关键字存储在叶子节点出现,内部节点(非叶子节点并不存储真正的 data),数据都集中在一个页中,减少了随机IO。同时非叶子节点扇出更多,树的高度降低,随机IO减少。
- 为所有叶子结点增加了一个链指针
同时为了增加区间访问性,一般会对B+树进行优化:将叶子节点的单项指针变为双向指针,也就是将单链表转化为了双向链表。
每一个节点都是MySQL的最小存储单元:页(page)。
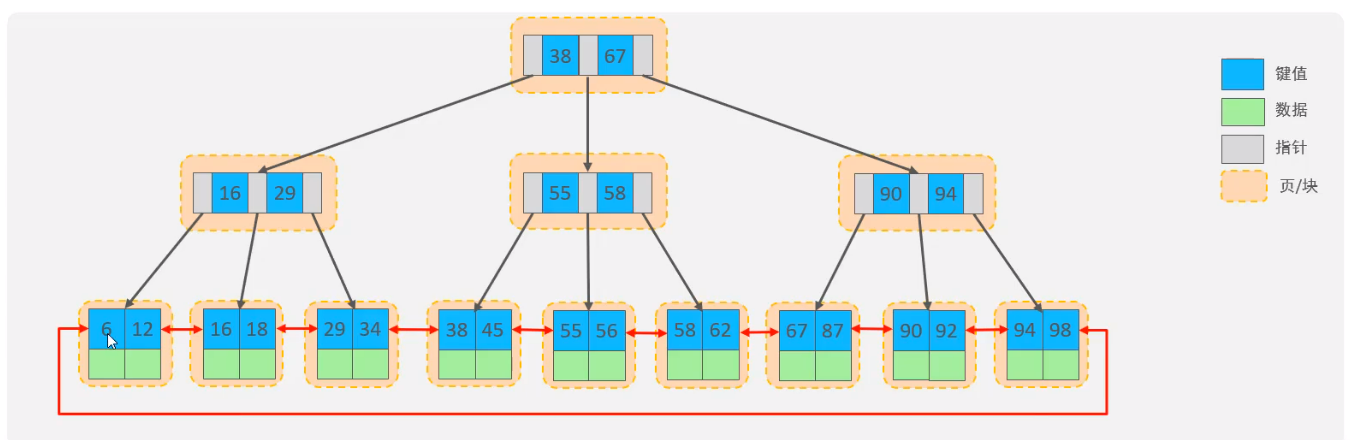
B+树相较于B树有以下特点:
- 查找的时间复杂度稳定在:对于B树来说,由于内部节点存放了数据,所以最好的时间复杂度为。
- 区间访问方便:B+树叶节点两两相连可大大增加区间访问性,可使用在范围查询等,而B-树每个节点 key 和 data 在一起,则无法区间查找。B+树可以很好的利用空间局部性,提前将相邻的数据加载如MySQL的BufferPool中。
- 更适合外部存储:由于内部节点不存储数据,对于叶子节点就可以存储更多的数据,一次IO操作取出的页中就会存在更多的数据。
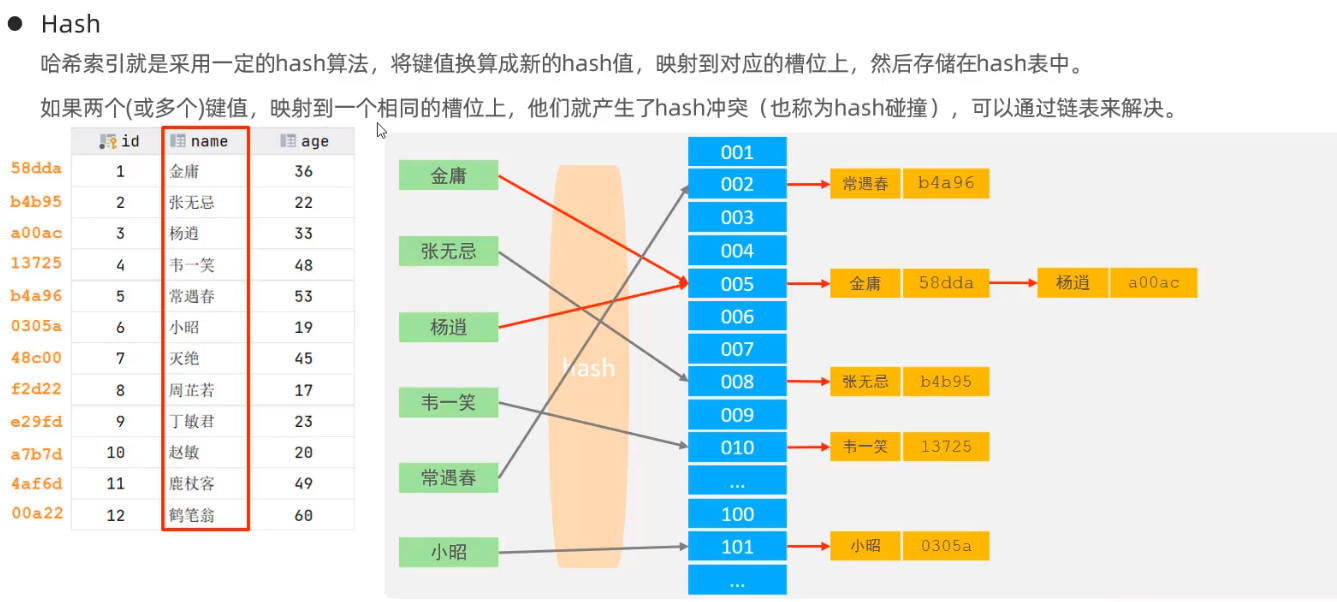
hash

索引分类
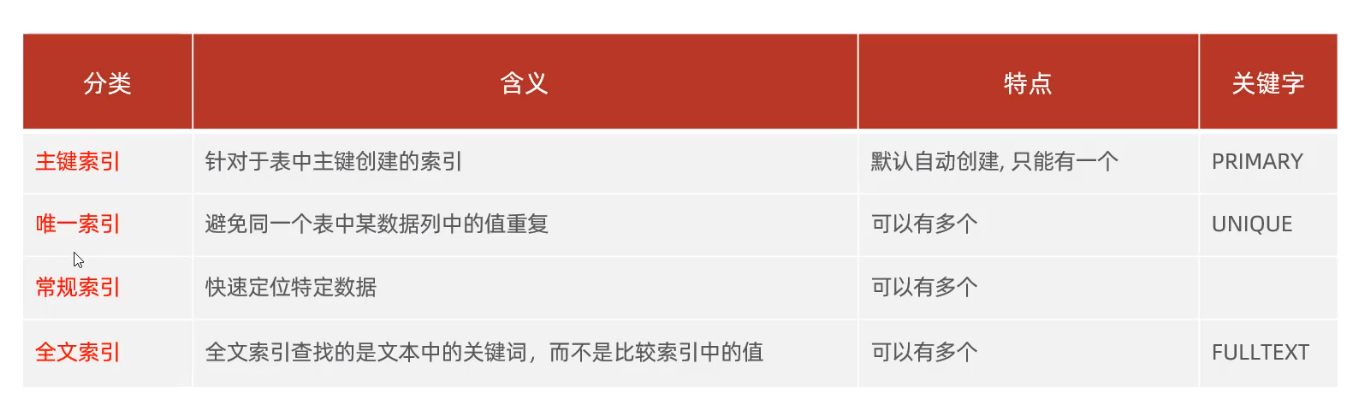
按照存储类型分:

按照索引个数分:
- 单列索引
- 联合索引
索引语法
-- 创建索引
create index idx_table_c1_c2 on table(c1,c2);
-- 查看索引
show index from table;
-- 删除
drop index idx_name on table;
性能分析
一般只对select进行性能优化,以下命令查询SQL执行频率


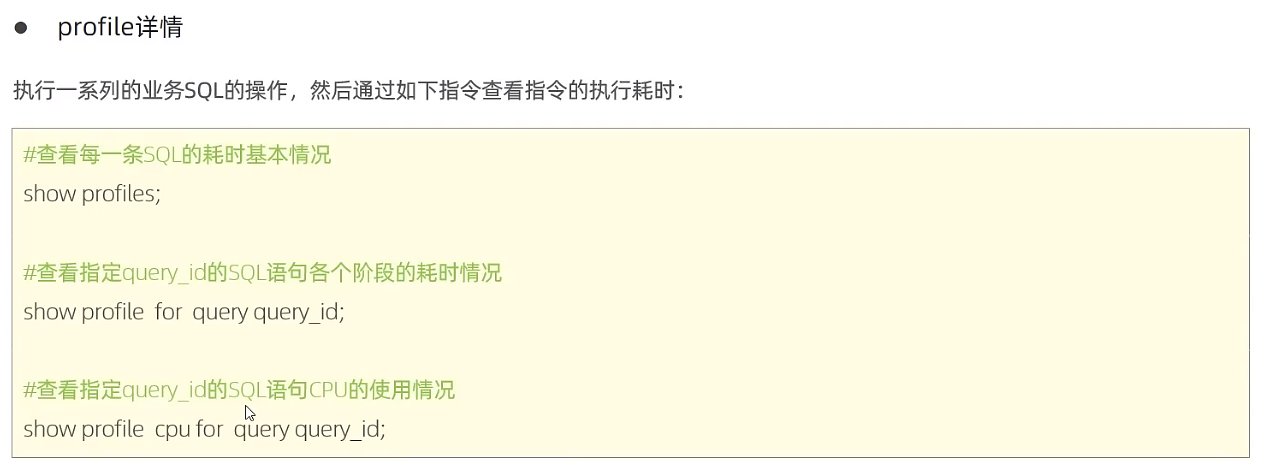


使用原则
最左前缀法则
对于联合索引,查询要从索引的最左侧开始,不能跳过,如果跳过某一列,那么后面字段索引将失效。
结合联合索引的结构很好理解,MySQL对于联合索引是首先按照前面的的索引进行排序,在相等时,按照后面的索引进行排序。相当后面的索引是基于前面索引的局部有序,而第一个索引是全局有序的。所以如果要跳过其中一个,后面的排序很明显无法进行了。
索引失效
- 联合索引中,出现了范围查询(<,>),范围查询右侧的列索引失效
- 索引类上进行运算操作
- 发生隐式转换(字符串和数字之间)
- 头部模糊查询
- 查询条件中使用 or,且 or 的前后条件中有一个列没有索引,涉及的索引都不会被使用到;
- 没有遵循最左前缀法则
- 数据分布影响:如果MySQL评估使用索引慢于全表查询,则不会使用索引
SQL提示

回表查询
基于二级索引的查询并且select包含了除了索引和id以外的字段,就会出现先查二级索引,再查聚集索引的情况,因为二级索引的数据只是主键的值。
索引覆盖
只需要在一棵索引树上就能获取SQL所需的所有列数据,无需回表,速度更快。explain的输出结果Extra字段为Using index时,能够触发索引覆盖。
通常使用联合索引来实现索引覆盖:
create table user (
id int primary key,
name varchar(20),
sex varchar(5),
index(name,sex)
)engine=innodb;
select * from where name = "xx";
这样二级索引的索引键值就包含了所有需要的数据,不需要再去回表查询。
前缀索引
