传统IO模型,上下文切换(陷入内核),内存拷贝
DMA
mmap
sendfile
在介绍零拷贝之前,需要先了解传统的阻塞I/O模型。
DMA
在没有DMA之前,在阻塞I/O的模式下,从磁盘读取到网卡发送:
while((n = read(diskfd, buf, BUF_SIZE)) > 0)
write(sockfd, buf , n);
工作流程如下: 
可以发现,在从磁盘读取的过程中,涉及到了两次CPU拷贝,两次上下文切换。在从向socket写数据的过程中,也涉及到了两次CPU拷贝,两次上下文切换,一共涉及到了四次CPU拷贝,四次上下文切换。
拷贝数据这种任务,属于又脏又耗时间的活,如果都让CPU干了,别的线程就要急死了,所以我们要想办法减少甚至不让CPU参与进来!
所以就引入了直接内存访问(Direct Memory Access,DMA),它就像CPU的小弟一样,指哪打哪。用来代替CPU完成数据拷贝这种任务。
DMA传输将数据从一个地址空间复制到另一个地址空间,提供在外设和存储器之间或者存储器和存储器之间的高速数据传输。当CPU初始化这个传输动作,传输动作本身是由DMA控制器来实现和完成的。DMA传输方式无需CPU直接控制传输,也没有中断处理方式那样保留现场和恢复现场过程,通过硬件为RAM和IO设备开辟一条直接传输数据的通道,使得CPU的效率大大提高。
在加入DMA后,工作流程有了一些改变:
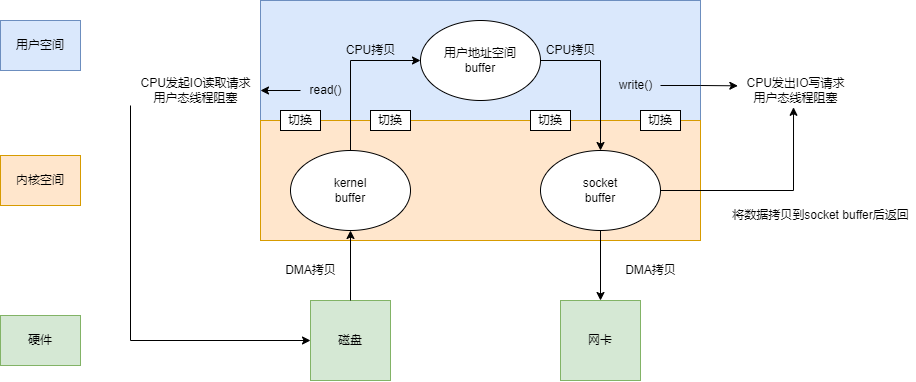
可以看出,现在一共涉及到了两次CPU拷贝,四次上下文切换。
零拷贝
【linux】图文并茂|彻底搞懂零拷贝(Zero-Copy)技术 - 知乎 (zhihu.com)
看一遍就理解:零拷贝原理详解 - 知乎 (zhihu.com)
我们可以看到,如果应用程序不对数据做修改,从内核缓冲区到用户缓冲区,再从用户缓冲区到内核缓冲区。两次数据拷贝都需要CPU的参与,并且涉及用户态与内核态的多次切换,加重了CPU负担。所以引入了零拷贝技术。
零拷贝字面上的意思包括两个,零和拷贝:
- 拷贝:就是指数据从一个存储区域转移到另一个存储区域。
- 零:表示次数为0,它表示拷贝数据的次数为0。
mmap
Linux内核黑科技——mmap实现详解 - 知乎 (zhihu.com)
mmap的函数原型如下:
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);
mmap是Linux提供的一种内存映射文件的机制,它实现了将内核空间缓冲区(Page Cache)与用户空间缓冲区地址进行映射,从而实现内核缓冲区与用户缓冲区的共享。我们知道,对文件进行读写时需要经过页缓存进行中转的。所以当虚拟内存地址映射到文件的页缓存后,就可以直接通过读写映射区内存来对文件进行读写操作。
下面介绍一下
mmap函数的各个参数作用:
addr:指定映射的虚拟内存地址,可以设置为 NULL,让 Linux 内核自动选择合适的虚拟内存地址。
length:映射的长度。
prot:映射内存的保护模式,可选值如下:
PROT_EXEC:可以被执行。PROT_READ:可以被读取。PROT_WRITE:可以被写入。PROT_NONE:不可访问。
flags:指定映射的类型,常用的可选值如下:
MAP_FIXED:使用指定的起始虚拟内存地址进行映射。MAP_SHARED:与其它所有映射到这个文件的进程共享映射空间(可实现共享内存)。MAP_PRIVATE:建立一个写时复制(Copy on Write)的私有映射空间。MAP_LOCKED:锁定映射区的页面,从而防止页面被交换出内存。- ...
fd:进行映射的文件句柄。
offset:文件偏移量(从文件的何处开始映射)。介绍完
mmap函数的原型后,我们现在通过一个简单的例子介绍怎么使用mmap:int fd = open(filepath, O_RDWR, 0644); // 打开文件 void *addr = mmap(NULL, 8192, PROT_WRITE, MAP_SHARED, fd, 4096); // 对文件进行映射在上面例子中,我们先通过
open函数以可读写的方式打开文件,然后通过mmap函数对文件进行映射,映射的方式如下:
addr参数设置为 NULL,表示让操作系统自动选择合适的虚拟内存地址进行映射。length参数设置为 8192 表示映射的区域为 2 个内存页的大小(一个内存页的大小为 4 KB)。prot参数设置为PROT_WRITE表示映射的内存区为可读写。flags参数设置为MAP_SHARED表示共享映射区。fd参数设置打开的文件句柄。offset参数设置为 4096 表示从文件的 4096 处开始映射。
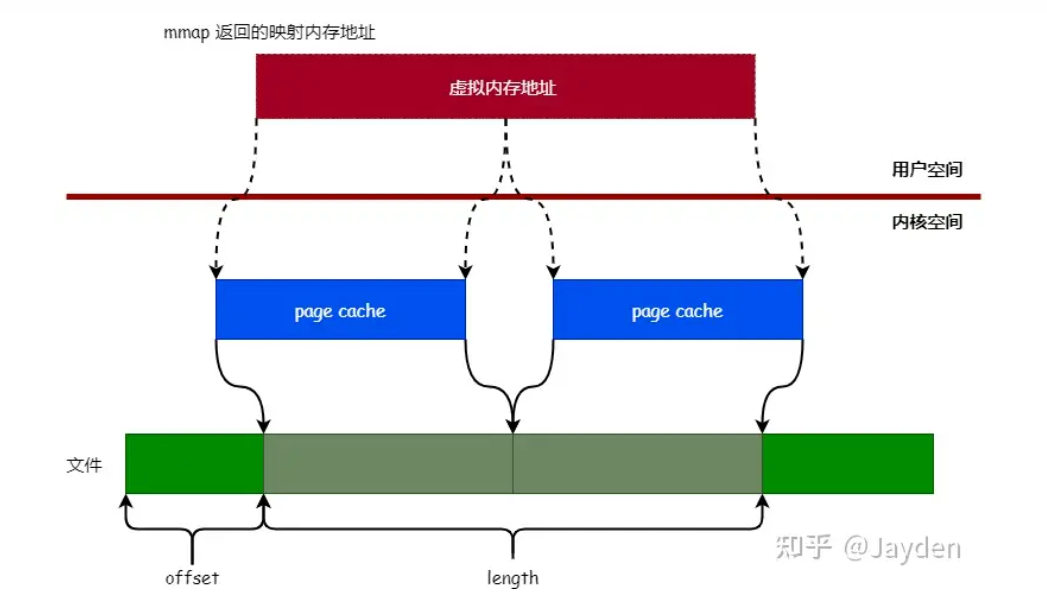
利用这一点,我们就无需将内核缓冲区的数据拷贝到用户缓冲区,直接在用户缓冲区操作,就相当于在内核缓冲区(Page Cache)上操作。
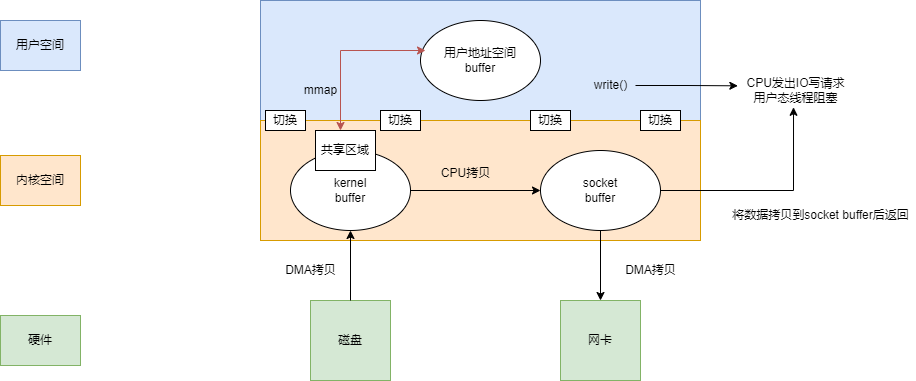
现在涉及到了一次CPU拷贝,四次上下文切换。并且用户进程内存是虚拟的,只是映射到内核的读缓冲区,可以节省一半的内存空间。
sendfile
我们知道上下文切换也是非常耗时的,CPU需要保存当前线程的状态上下文,并且还原要执行线程的状态上下文。但也是不可或缺的,因为些特殊操作,如磁盘文件读写、内存的读写等等。因为这些都是比较危险的操作,不可以由应用程序乱来,只能交给底层操作系统来,需要程序陷入内核态,才可以执行特权操作,我们现在涉及到了两次陷入内核,相当于四次切换上下文,还需要想办法优化。
sendfile是Linux2.1内核版本后引入的一个系统调用函数,API如下:
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
- out_fd:为待写入内容的文件描述符,一个socket描述符。
- in_fd:为待读出内容的文件描述符,必须是真实的文件,不能是socket和管道。
- offset:指定从读入文件的哪个位置开始读,如果为NULL,表示文件的默认起始位置。
- count:指定在fdout和fdin之间传输的字节数。
sendfile表示在两个文件描述符之间传输数据,它是在操作系统内核中操作的,避免了数据从内核缓冲区和用户缓冲区之间的拷贝操作,因此可以使用它来实现零拷贝。
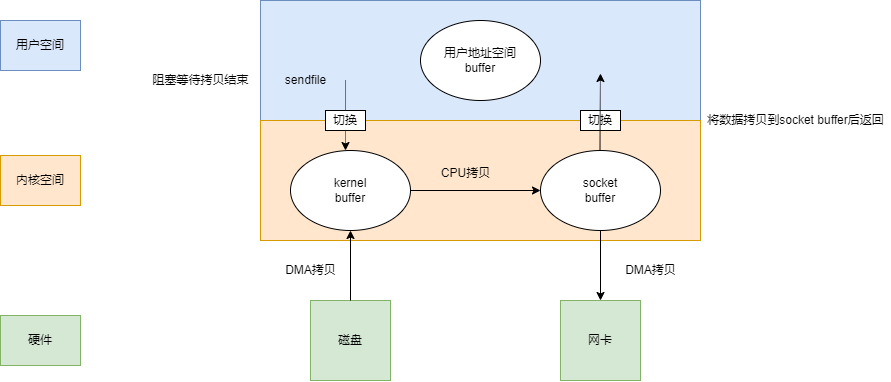
现在涉及到了一次CPU拷贝,两次上下文切换。人总是贪婪的,能不能不要CPU原地打滚,直接使用现成的数据呢?
sendfile+DMA拷贝
Linux 2.4 内核对 sendfile 系统调用进行优化,但是需要硬件DMA控制器的配合。引入SG-DMA技术,其实就是对DMA拷贝加入了scatter/gather操作,它可以直接从内核空间缓冲区中将数据读取到网卡。
升级后的sendfile将内核空间缓冲区中对应的数据描述信息(文件描述符、地址偏移量等信息)记录到socket缓冲区中。
DMA控制器根据socket缓冲区中的地址和偏移量将数据从内核缓冲区拷贝到网卡中,从而省去了内核空间中仅剩1次CPU拷贝。

最后只剩下了两次上下文切换。