本章介绍了汇编语言的基础,讲解了机器级编程的概念
1. 过程
过程将一段代码封装,用一组指定的参数和一个返回值实现了某种功能,是一种很重要的抽象。
假设过程P调用过程Q,Q执行后返回P,在这个过程中,包含以下动作:
- 传递控制:在进入Q时,PC必须被设置为Q的代码的起始地址,在返回的时候,PC要设置为P调用Q后面那条指令的地址。
- 传递数据:P必须能向Q提供一个或多个参数,Q向P返回一个值。
- 分配和释放内存:在开始时,Q可能需要为局部变量分配空间,而在返回时,需要释放这些存储空间。
1.1 运行时栈
c语言的过程调用机制的一个关键特征在于使用了栈数据结构提供的先进后出的内存管理原则。在P调用Q时,Q在执行中,P以及P以上的调用链,都是被暂时挂起的。当Q运行时,它可以分配局部变量,或调用新的过程。同时当Q返回时,所有的局部变量的内存空间都要被释放。
所以,程序可以使用栈来管理它的过程所需要的内存空间,栈和程序寄存器存放着传递控制和数据,分配内存所需要的信息。

x86-64的栈是向低地址方向增长,栈指针%rsp指向栈顶元素,使用pushq和popq操作栈顶。
当x86-64的过程所需要的存储空间超出寄存器能存放的大小时,就会在栈上分配空间,被称为栈帧。当前执行的过程总是在栈顶,当P调用Q时,会把返回地址压入栈中,一般将其看作P的栈帧中的一部分。
通过寄存器,过程P最多可以传送六个参数(整数值),如果需要更多的参数,就需要在自己的栈帧中存储好这些参数。
当所有的局部变量都可以存放在寄存器中,并且不会去调用其他的过程,那么就不会用到栈。
%rbp 被称为帧指针(base pointer),在栈帧时不定长的时候需要使用,具体见P201
1.2 转移控制
将控制从过程P转移到过程Q只需要将PC设置为Q的代码起始地址。这个操作时由call指令实现的,调用过程Q即是call Q。和跳转相同,可以是直接的也可以是间接的。
1.3 数据传送
在x86-64中,寄存器最多传递六个整形参数,寄存器的使用是由顺序的,同时可以访问寄存器的适当部分来访问小于64位的参数。下图是传递参数的寄存器:
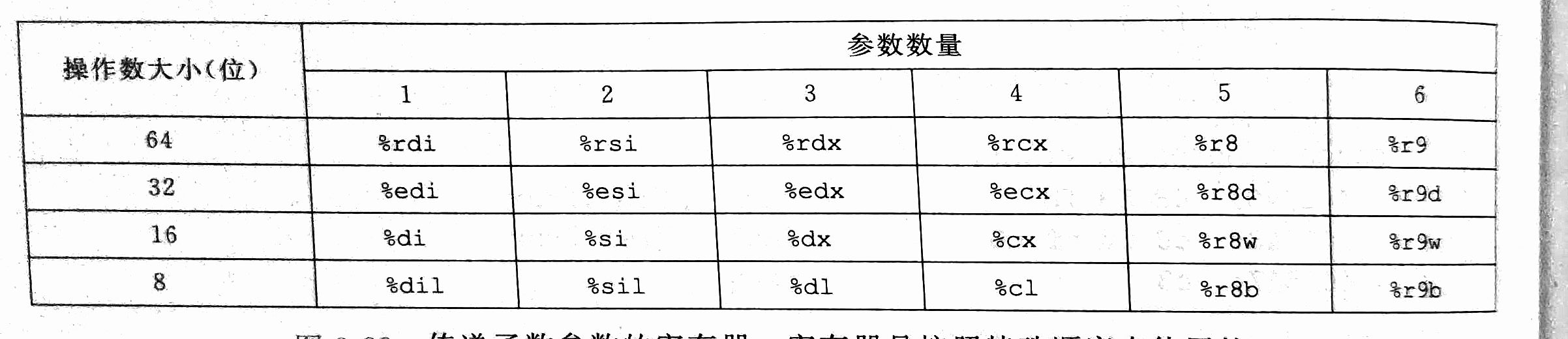
当参数大于六个时,就只能通过栈传递,参数7位于较低地址处,参数n位于较高的地址。同时,所有的数据大小都向8(字节)的倍数对齐,此部分就是参数构造区。下面是一个例子:
void proc(long a1, long *a1p,
int a2, int *a2p,
short a3, short *a3p,
char a4, char *a4p)
{
*a1p += a1;
*a2p += a2;
*a3p += a3;
*a4p += a4;
}
proc:
movq 16(%rsp), %rax
addq %rdi, (%rsi)
addl %edx, (%rcx)
addw %r8w, (%r9)
movl 8(%rsp), %edx
addb %dl, (%rax)
ret
很明显,在获取前六个参数的值时,是通过直接寻址和间接寻址找到的,在第二行和倒数第三行是通过栈来获取参数7和参数8。并且char类型的参数也被编译为了8位字节,注意%rsp存放的是返回地址,8(%rsp)存放的才是第七个参数。
1.4 栈上的局部存储
有些时候局部数据必须存放在内存中,常见的情况有:
- 寄存器不足以存放所有的本地数据
- 对一个局部变量使用
&运算符,因此必须为它产生一个地址 - 某些局部变量是数组或结构,因此必须能够通过能通过引用访问到
在这里使用了leaq的第二个用法,它看上去是从内存读数据到寄存器,实际上它是将内存的有效地址放入寄存器中。
具体的例子详见p172。
1.5 寄存器中的局部存储空间
寄存器组是唯一被所有过程共享的资源,虽然在给定时刻只有一个过程是活动的,但我们仍需保证当一个过程调用一个过程时,被调用者不会覆盖调用者稍后会使用的寄存器的值。
根据惯例:寄存器%rbx,%rbp和%r12~%r15被划分为被调用者保存寄存器,当P调用Q时,Q必须保证寄存器的值和调用之前的值相同。要么不改变它,要么把原始的值压入栈中,改变寄存器的值,最后从栈中弹出旧值。
除了以上的寄存器和栈指针寄存器%rsp以外,都叫做调用者保存寄存器,在P调用Q时,Q可以随意改动这些寄存器的值。
所以一般过程都会选择先保存(pushq)要使用的被调用者保存寄存器,然后进行自己的运算,最后再存回去(popq),这样如果自己也需要调用其他的过程时,本身的数据也会被下一个过程所保存。
1.6 递归过程
由于每个过程都有自己私有的栈空间和被调用者保护寄存器,使得过程调用都有自己私有的状态信息,所以递归调用也就和普通调用相同了。
这里也可以看出迭代和递归的区别,每次递归都需要在栈中申请空间,一旦写出了无限递归的代码,由于操作系统会规定栈的最大深度,就有可能发生栈溢出。而迭代如果没有进行空间分配,最有可能发生的就是无限循环。
2. 数组
2.1 基本原则
对于数据类型T和整型常数N,有如下声明T A[N]。它在内存中分配一个L*N字节的连续地址,L是类型T的大小。其次A可以用来作为指向数组开头的指针,数组中元素i会被存放在地址为的地方。
在x86-64中,我们可以通过内存引用指令来简化数组访问,假设有以下声明:int A[10],如果我们要计算A[i],并且A的地址存放在寄存器%rax中,i存放在%rcx中,那么,可以使用以下指令:
movl (%rdx,%rcx,4) %eax
计算A[i],并放置到寄存器%eax中,伸缩因子取到1,2,4,8。
2.2 指针和数组
在语言中,如果对指针进行运算,它会根据指针引用的数据类型的大小进行伸缩,如果p是一个指定T数据类型的指针,p的值是x,那么,p + i 的值就是x+L*i,其中,L是T的大小。
假设有以下声明:int A[10],数组名A可以看作数组的起始地址,也就是第一个元素的起始地址,它是不可改变的,根据实验得到下图:
 、
、
指针也可以指向函数:对于函数声明:int fun(int x, int *p);
声明一个指针: int (*p) (int, int *); 赋值:p = fun;
调用:int x = 1;p(x,&x);
2.3 多维数组
在c中,多维数组遵循行优先的原则,对于数组D,D[i][j]的内存地址为:,其中L是数组元素的类型大小,是数组其实地址,C是列数。
3. 异质的数据结构
c中提供了两种将不同的数据类型组合到一起创建数据类型的机制:结构(structure)和联合(union)。
3.1 结构
c通过struct将不同类型的数据聚合到一个对象中,类似于数组的实现,结构的所有部分都存放在一段连续的内存中,指向结构的指针就是结构中第一个元素的第一个字节地址,通过每一个字段的字节偏移,来实现对结构元素的引用
3.2 联合
联合提供了一种方式来规避c中的类型检查,允许多种类型来引用一个对象,它是用不同的字段来引用相同的内存块,也就是说,联合中的元素是互斥的。联合中的所有元素的起始地址相同,都是联合的起始地址,同时,联合的字节大小是所有元素中的最大的字节大小。
联合可以用来访问不同数据类型的为模式,考虑以下代码:
unsigned long doubule2bits(double d)
{
union {
double d;
unsigned long u;
} temp;
temp.d = d;
return temp.u;
}
此段代码可以用来获取double类型的位模式,利用了union的元素是互斥的,以及unsigned long类型的无符号64位特性。
3.3 数据对齐
许多计算机系统会对数据类型的合法地址进行限制,要求其必须是某个值K的倍数(2,4,8),这种对齐限制简化处理器和硬件的设计成本,提升了cpu的效率。假设一个double类型的变量所处的地址不是8的倍数,那么低于总是从内存中取8个字节的处理器来说,就需要两次操作。K通常和数据类型的大小相同。
举例:
struct{
int i;
char c;
int j;
}
假设结构体起始地址为0,那么i的起始地址为0,c的起始地址为4,j的起始地址为5,这种情况下是不满足对齐要求的,通常会在c后补上3个字节,使起始地址变为0,4,8,同时编译器会让起始地址满足4字节对齐。这样三个元素都满足四字节对齐。
有时还会向结构体末尾加入冗余字节,保证结构数组的每个都满足字节对齐要求。
struct s{
int i;
int j;
char c;
}
如果只考虑单个结构体,它已经满足了数据对齐的要求,但是考虑以下声明:
struct s d[4];
在后续的结构体中,不满足对齐要求,所以通常会在结构体的后面分配字节来满足要求。这个例子会在最后多分配3个字节。
4. 缓冲区溢出
4.1 内存分配
对于x86-64来说,我们可用的只有47位,高位由内核虚拟内存占用,下面是理论内存分配图:

栈一般分配在内存的最高地址,向下增长,在ubuntu中,可以使用
unlimit -s
来获取当前计算机的栈最大深度,一般都是8M。
shared libraries是程序需要的动态库,它会在程序运行时动态加载进来。我们可以看到,heap和stack相反,它是由低地址向高地址增长,它里面是由malloc等一系列内存分配函数所分配的空间。data里面存的是全局变量,text里面存的是执行代码。
4.2 缓冲区溢出
我们知道,c不会对数组引用不做任何边界检查,并且局部变量和状态信息都存在栈中,这两种情况结合在一起就有可能导致一些非法的写操作修改栈中的状态信息,尤其是修改返回地址。
一种比较常见的状态破坏是缓冲区溢出(buffer overflow)。通常在栈中分配某个字符数组来保存一个字符串,但是字符串的长度超出了为数组分配的空间。
库函数gets就包含这个问题,它获取到了缓冲区的起始指针,却没有获取缓冲区的大小,在这样的情况下,输入超出缓冲区大小的字符串,就会修改到栈上的其他信息,如果存储的返回地址被修改了,那么就有可能跳转到一个其他的地方,有可能是攻击者设置的危险函数。
攻击者会输入给程序一串可执行代码的字节编码,同时还有另外的一些字节会用一个指向攻击代码的指针覆盖返回地址,那么返回指令的效果就是跳转到攻击代码。
4.3 对抗缓冲区溢出攻击
首先是使用更加安全的库函数,例如使用fgets代替gets,这样能抵挡初级的攻击。
4.3.1 栈随机化
在之前程序的栈地址很容易预测,对于同样的程序和操作系统版本的系统,攻击者如果可以确定一个机器所使用的栈空间,那么就可以在多个机器上实施攻击,这种现象称为安全单一化。
栈随机化的思想使得栈的位置在程序每次运行时都有一些变化,实现方式是:在程序开始时,在栈上分配一段随机大小的空间,但是大小要把控好,太大会浪费多余空间,太小不能获得足够多的栈地址变化。
#include <stdio.h>
#include <stdlib.h>
int global = 1;
void useless() {return;}
int main()
{
int local = 1;
int p = 1;
void *pr = malloc(100);
printf("local data:%lx\n",&p);
printf("heap small data:%lx\n",pr);
printf("global data:%lx\n",&global);
printf("code:%lx\n",useless);
return 0;
}
运行多次上面的代码,得到以下结果:
local data:7fffccaabdc4
heap small data:56304ce902a0
global data:56304cb67010
code:56304cb64189
local data:7fffd2142a64
heap small data:55fb9fc2a2a0
global data:55fb9ed7d010
code:55fb9ed7a189
发现无论栈地址、代码地址、全局变量地址还是堆地址,都是在变化的。这被称为地址空间布局随机化,栈随机化是其中的一种
4.3.2 限制可执行代码区域
一般,只有编译器产生的代码的那对内存才是需要可执行的,其他的部分可以被限制为读和写。所以系统会通过不同的方法将内存打上标记,以区分是否可执行。
4.3.3 栈破坏检测
GCC中加入了一种叫做栈保护者的机制,它的思想是在缓冲区和局部状态之间加入一个金丝雀值,也称为哨兵值,每次程序运行随机产生的,在每次恢复寄存器状态和返回调用之前,程序检查金丝雀值是否改变,如果是,那么程序异常终止。
可以在编译时加入 -fno-stack-protector 选项取消金丝雀值设置
伪汇编如下:
echo:
movq %fs:40,%rax
movq %rax, 8(%rsp)
...
call gets
...
xorq %fs:40,%rax
指令%fs:40指明金丝雀使用段寻址,将金丝雀放置一个特殊的段中,并标记为只读,这样就无法被覆盖,存入栈中。在恢复寄存器状态和返回调用之前,将栈上的值和金丝雀值相比较,如果不相等那么代表栈被破坏,程序终止。
5. 浮点代码
这里的浮点指令基于AVX2,给定指令参数-mavx2,GCC会生成AVX2代码。本节只记录常用的命令,不去深究原理。
5.1 媒体寄存器
AVX浮点结构允许数据存储在一组叫做AVX(高级向量扩展)的寄存器组中。

YMM是256位,32字节的,XMM是128位,16字节。对标量进行运算时,它只能存放浮点数只使用低64位或32位。
5.2 浮点传送操作
浮点数的传送指令的操作数和通用寄存器相同,只是指令有所不同。
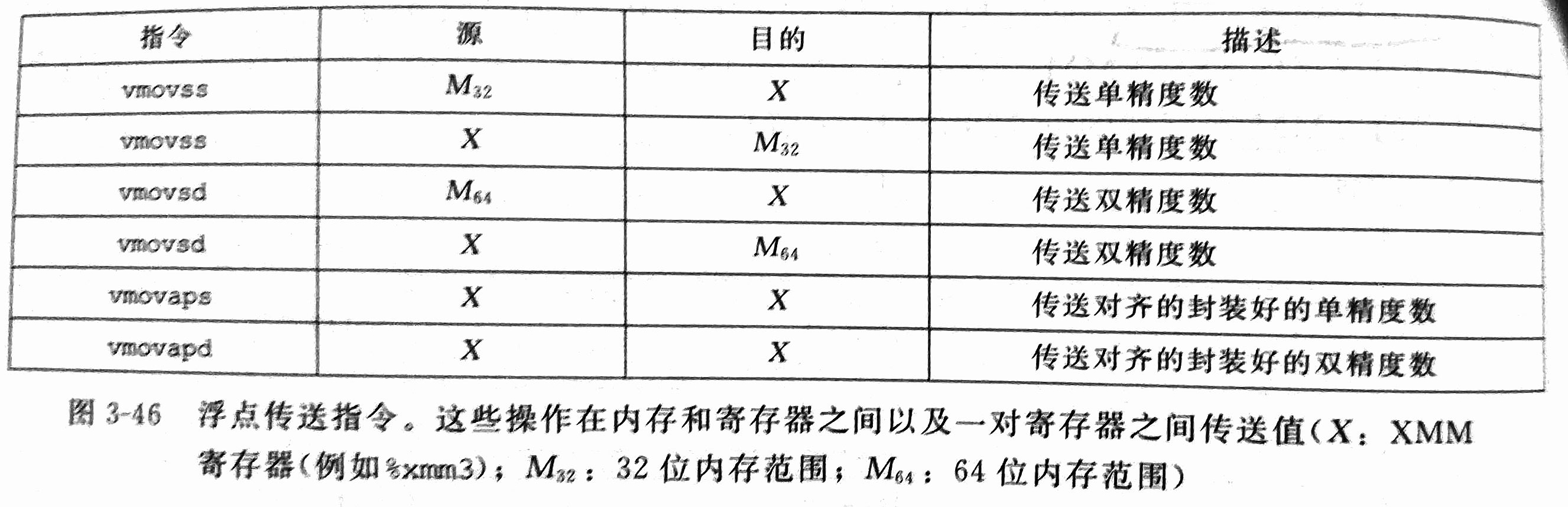
5.3 浮点转换操作
浮点数和整数之间的转换操作:
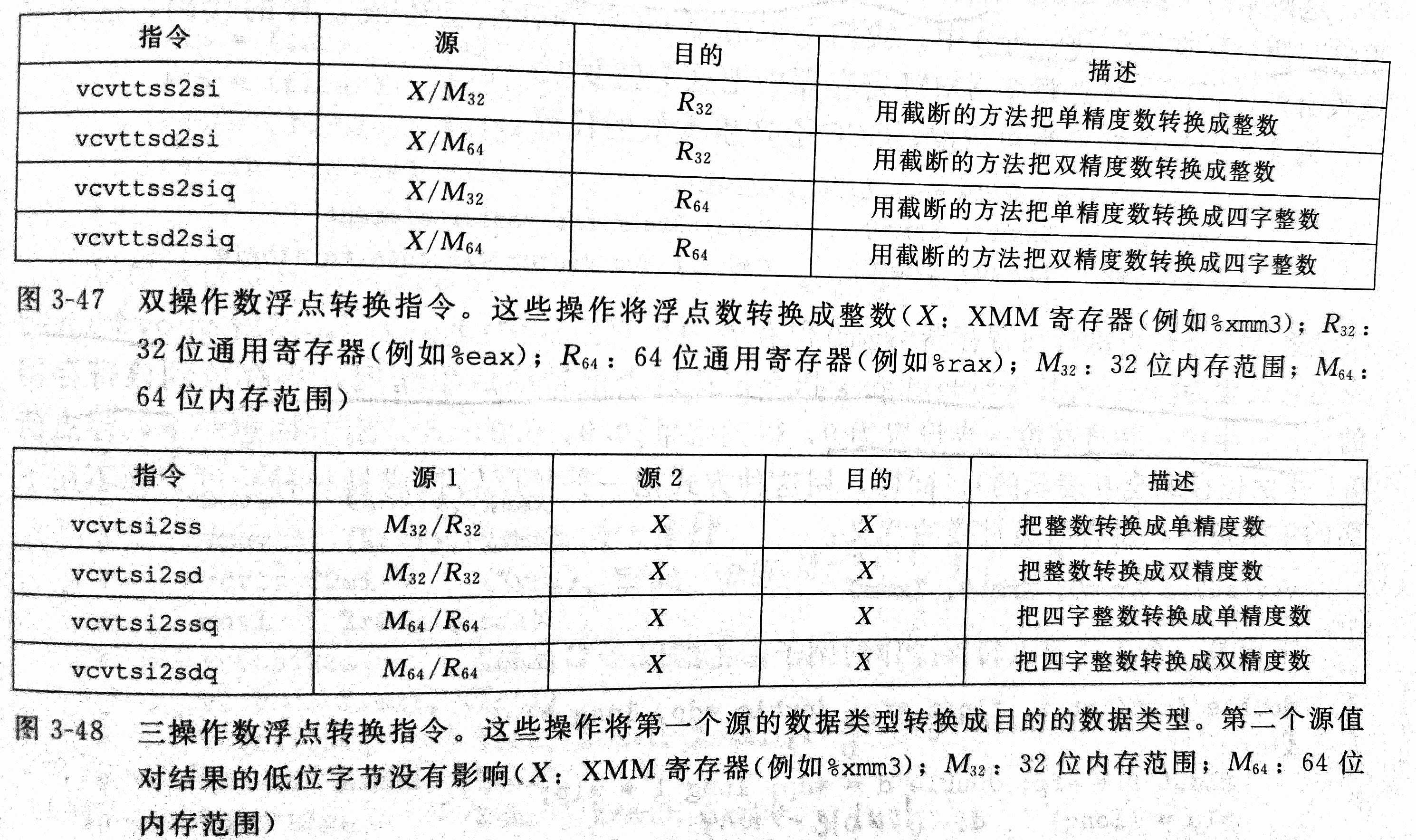
三操作的浮点转化中的源2和目的通常是相同的,同时三操作的目的只能是XMM寄存器。
将float转换为double,通常使用以下指令:
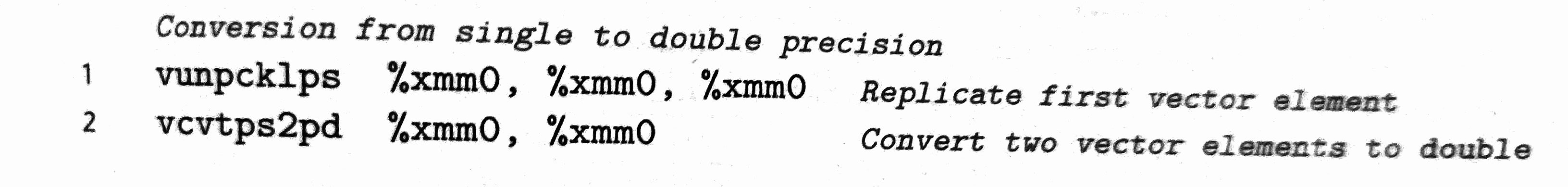
vunpcklps指令将两个XMM寄存器的值交叉放置到第三个寄存器中,如俩个XMM寄存器的内容分别为:[s3,s2,s1,s0]和[d3,d2,d1,d0],那么目的寄存器中的值就是[s1,d1,s0,d0]。在上面的代码中,三个操作数使用了同一个寄存器,如果源寄存器值为:[x3,x2,x1,x0]那么结果就是:[x1,x1,x0,x0]。vcvtpspd指令将源XMM寄存器中的两个底位单精度扩展称为XMM的俩个双精度值,得到[dx0,dx0],最后得到将单精度x0转换为双精度dx0的两个副本。
将double转换为float,使用以下指令:

vmovddup将[x1,x0]转换为[x0,x0]。vcvtpdpsx指令将这两个值转换为单精度的值,放入目的寄存器的低64位中,同时将高64位设置为0。
5.4 过程中的浮点代码
- XMM寄存器只可以传递最多8个浮点参数
- 函数通过%xmm0来返回浮点值
- 所有的XMM寄存器都是调用者保存的,被调用者可以随意覆盖。
传递参数时,整数和浮点数使用的寄存器个数是分开来计算的。
5.5 浮点运算操作
浮点运算有自己的一套指令:

5.6 定义和使用浮点数
和整数的运算操作不同,AVX浮点操作不能以立即数值作为操作数。编译器必须为所有的常量值分配和初始化存储空间,然后代码把这些值从内存中读入。下面是演示代码:
#include <stdio.h>
double cel2fahr(double t)
{
return 1.8 * t + 32.0;
}
int main()
{
cel2fahr();
return 0;
}
cel2fahr:
mulsd .LC0(%rip), %xmm0
addsd .LC1(%rip), %xmm0
.LC0:
.long 3435973837
.long 1073532108
.align 8
.LC1:
.long 0
.long 1077936128
.align
函数从.LC0中获取到两个值,由于机器是小端机器,所以第一个是低位。组合得到以下位模式:3ffccccccccccccd,转换后得到1.8。
5.7 在浮点代码中使用位级操作
类似于通用寄存器:

5.8 浮点比较操作
AVX2中提供了两条比较指令:

这些指令类似于CMP指令,但是S2必须位于XMM寄存器中,S1可以在内存或寄存器中。浮点比较指令会设置三个条件码:ZF、CF和PF(奇偶标志位)。当两个操作数有一个是NAN时,会设置该标志。在C中,有一个参数是NAN时,就认为比较失败了。

当任一参数是NAN时,就会出现无序的情况。