本文主要介绍redis在业务中的使用场景,课程来自于黑马程序员。
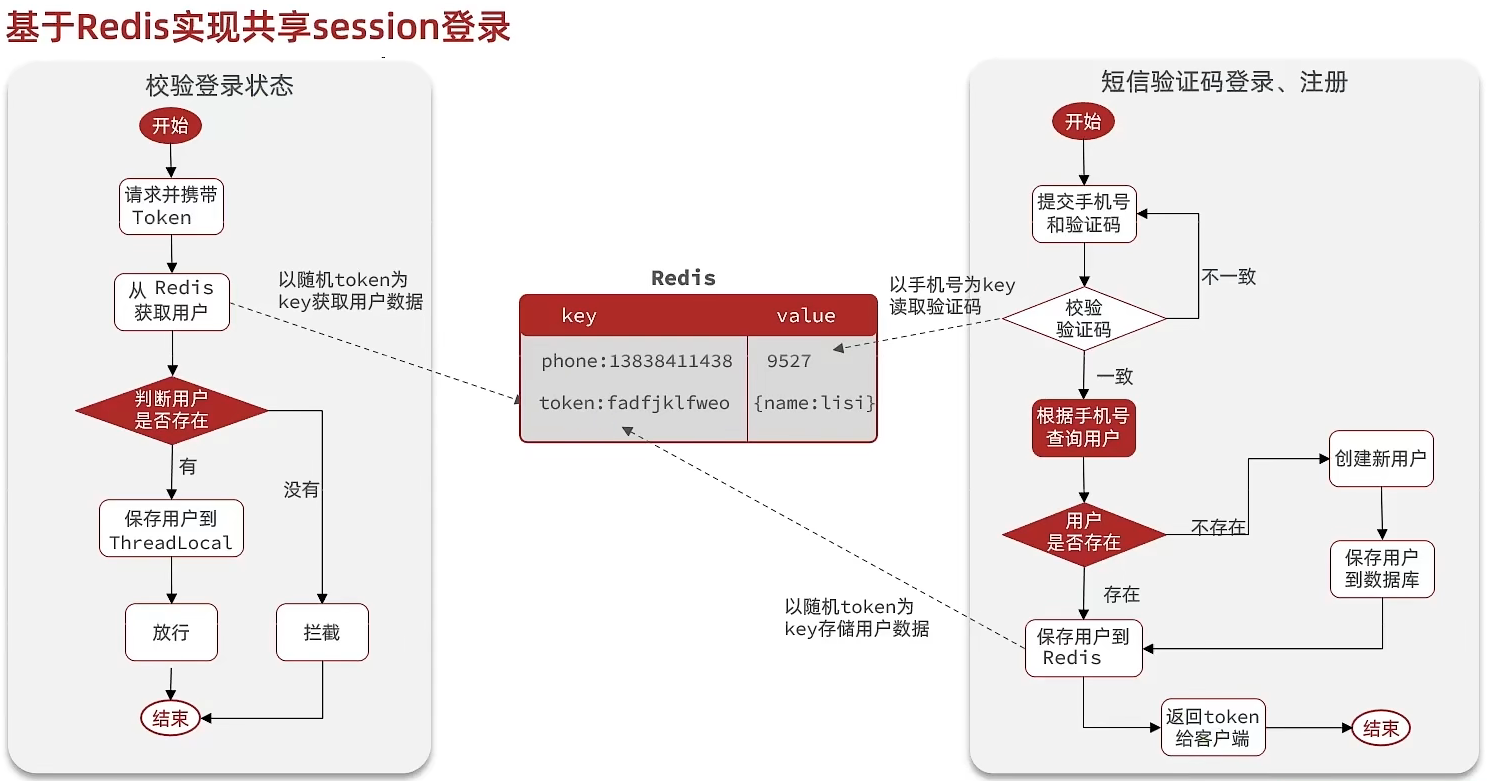
共享session
在单机版后端服务中,常常使用session来保持客户端的状态,但在分布式的场景下,不同机器之间的session是不互通的,所以需要一个第三方中间件来共享session,这里就用到了redis。可以采用string的数据结构,key做用户的唯一标识,value存储用户信息的序列化json串。
缓存
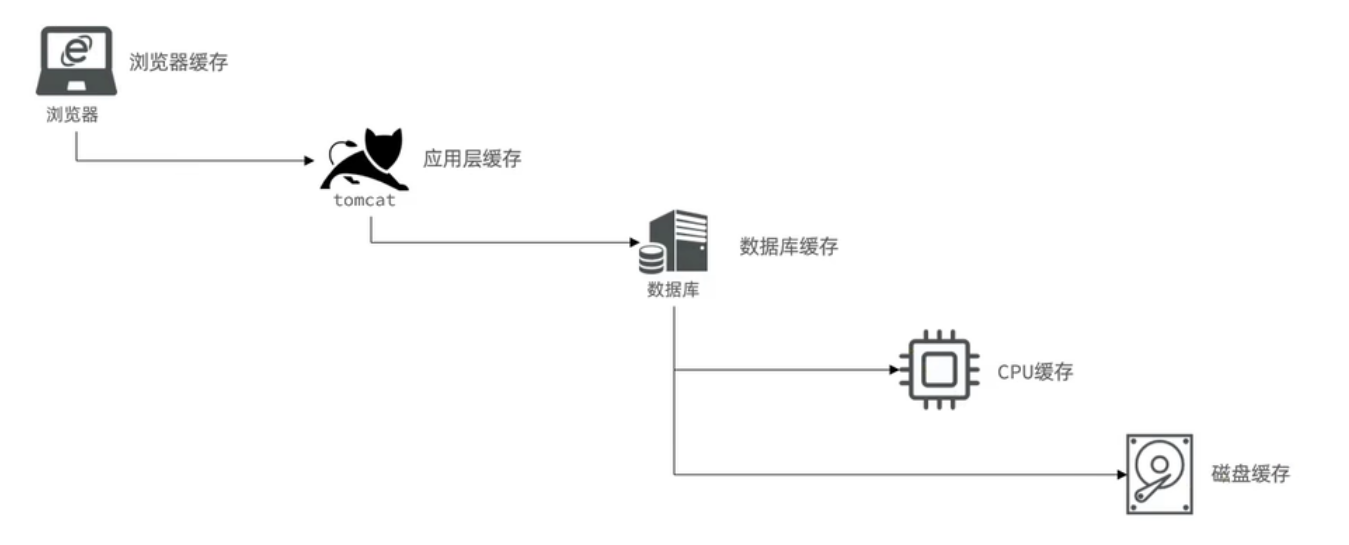
使用内存型数据库做基于磁盘的数据库的缓存,可以大大减少磁盘的I/O操作,加快响应时间,提高并发量。
实际上从前端一直到后端,整个链路上都存在着各种各样的缓存:
缓存的基本思路:查询数据库之前先查询缓存,如果缓存数据存在,则直接从缓存中返回,如果缓存数据不存在,再查询数据库,然后将数据存入redis。
缓存的更新策略
- 内存淘汰:当redis的内存占用达到上限后,会根据设置的淘汰策略来删除一些数据(lru,lfu)。
- 超时剔除:当数据达到TTL之后,将会被自动删除。
- 主动更新:人工的去删除缓存,主要是用来保证数据的一致性。
如何保证数据的一致性
- Cache Aside Pattern 人工编码方式:缓存调用者在更新完数据库后再去更新缓存,也称之为双写方案
- Read/Write Through Pattern : 由系统本身完成,数据库与缓存的问题交由系统本身去处理(抽象出一个缓存组件)
- Write Behind Caching Pattern :调用者只操作缓存,其他线程去异步处理数据库,实现最终一致(canal)
第二种方法实际上是对第一种方法的抽象,所以我们考虑采用硬编码的形式,人工的保证数据的一致性。
那么现在就有一些问题:
删除缓存还是更新缓存?
- 更新缓存:每次更新数据库都更新缓存,无效写操作较多。
- 删除缓存:更新数据库时让缓存失效,查询时再更新缓存。
如何保证缓存与数据库的操作的同时成功或失败?
- 单体系统,将缓存与数据库操作放在一个事务。
- 分布式系统,利用TCC等分布式事务方案。
先操作缓存还是先操作数据库?
应该是要先操作数据库,如果先操作缓存,可能会出现数据的不一致性。
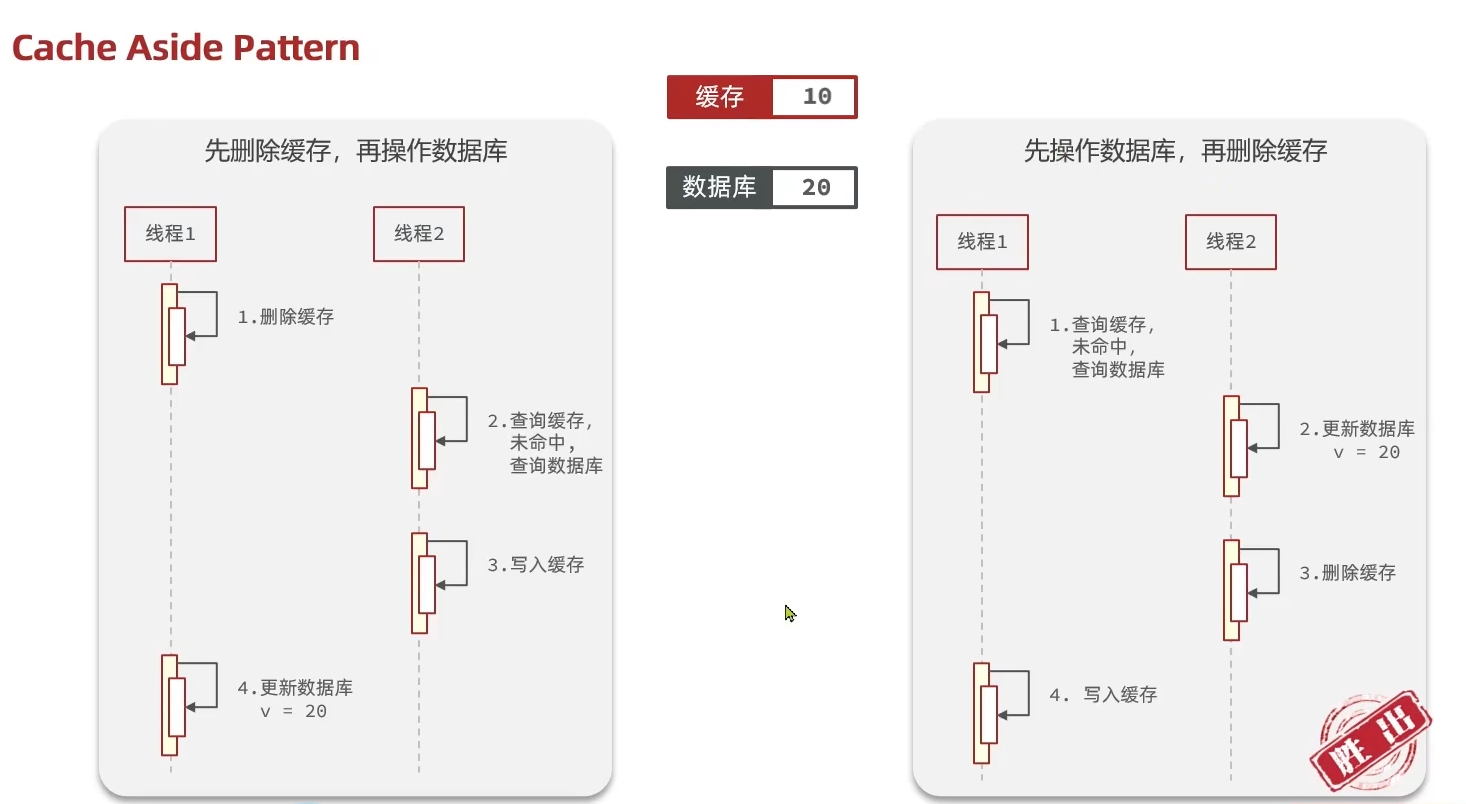
实际上第二种也是存在并发问题的,线程1先操作数据库,还没来得及更新缓存,线程2就返回了脏缓存数据。这里引入了延迟双删的策略。
延迟双删
延迟双删即采用先删除缓存,再更新数据库的策略,但是最后会加一步延时删除缓存的步骤保证数据的最终一致性。
对于单机redis和mysql,实际上最后的延迟是没什么必要的,但是如果做了读写分离,主从同步。那么就需要这个延时时间来保证主从一致性,当然这个时间是估计出来的。
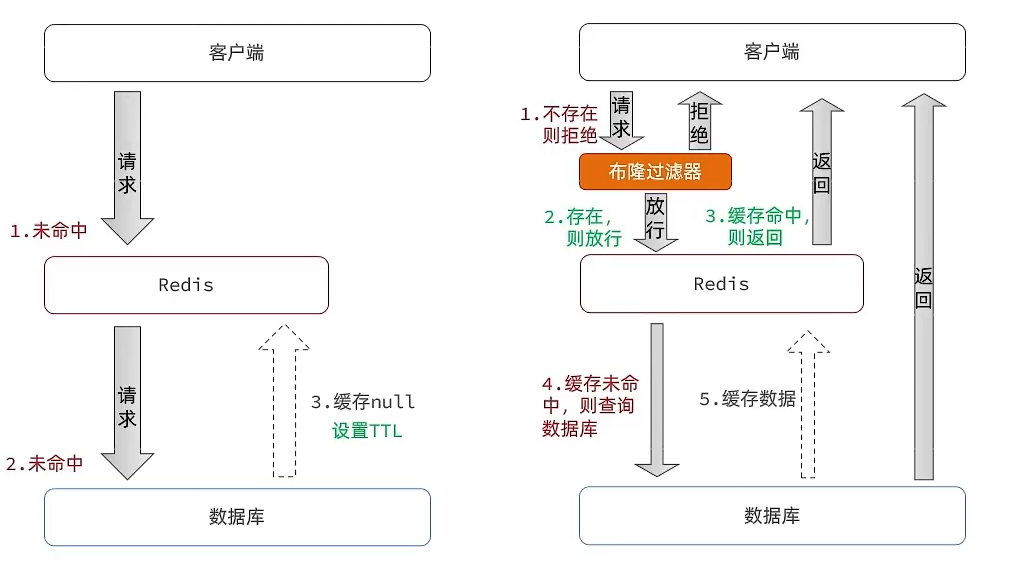
缓存穿透
缓存穿透是指客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库。
常见的解决方案有两种:
- 缓存空对象
- 优点:实现简单,维护方便
- 缺点:
- 额外的内存消耗
- 可能造成短期的不一致
- 布隆过滤
- 优点:内存占用较少,没有多余key
- 缺点:
- 实现复杂
- 存在误判可能(Hash冲突)
缓存击穿
缓存击穿问题也叫热点Key问题,就是一个被高并发访问并且缓存重建业务较复杂的key突然失效了,或者热key在服务的最开始还没有来的及构建,无数的请求访问会在瞬间给数据库带来巨大的冲击。
解决方案:
分布式锁+double check:大大的降低了数据库的压力,但是会降低系统的并发度
提前预热:针对热点数据提前预热,将其存入缓存中并设置合理的过期时间比如秒杀场景下的数据在秒杀结束之前不过期。
逻辑过期:即将过期时间value中,由程序员手动控制,优点是异步的构建缓存,加大并发度,缺点在于在构建完缓存之前,返回的都是脏数据。具体操作如下:
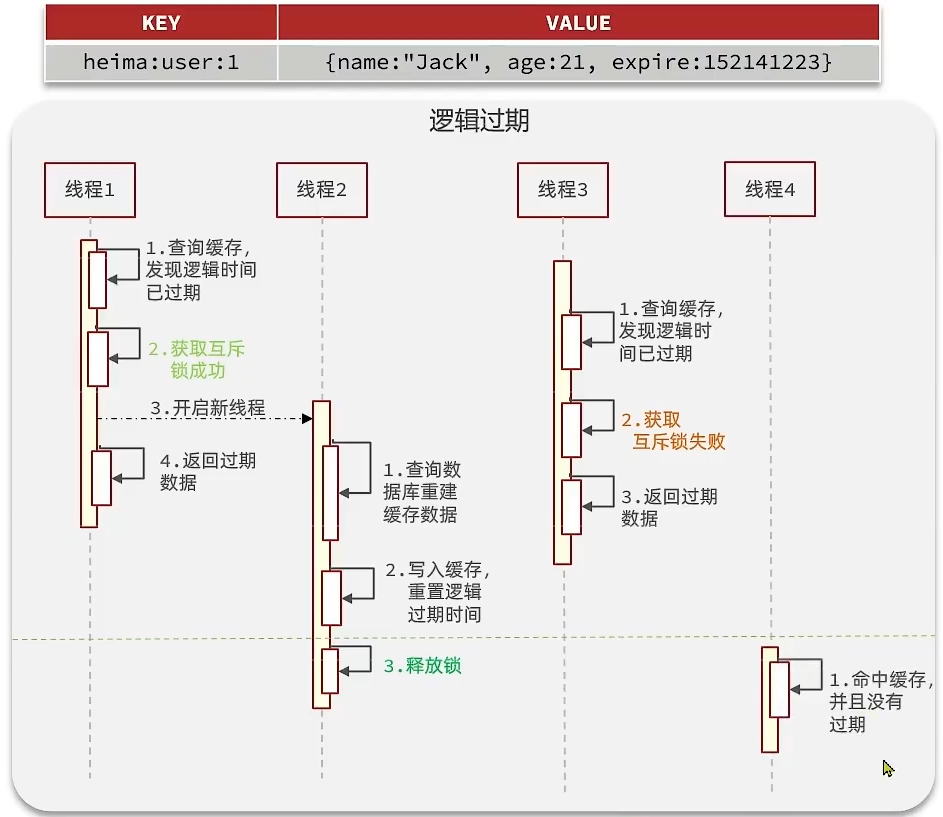
缓存雪崩
缓存雪崩是指在同一时段大量的缓存key同时失效或者Redis服务宕机,导致大量请求到达数据库,带来巨大压力。
解决方案:
- 给不同的Key的TTL添加随机值
- 利用Redis集群提高服务的可用性
- 给缓存业务添加降级限流策略
- 给业务添加多级缓存
秒杀场景
参考: 秒杀场景
点赞
使用zset存储文章的点赞用户id,score存储点赞时间戳,可以按照排名获取前几名点赞的用户。
关注
使用set维护关注列表,使用交集求共同关注。
FeedStream
- TimeLine:按照时间排序,不做筛选,常用于好友或关注。
- 智能推荐:发现页面
TimeLine
- 拉模式(读扩散):消息保存在发送方,消费方上线后主动去拉取。适合消费者少的场景,空间占用小。
- 推模式(写扩散):当消息出现时,主动的发送到消费方。适合消费者多的场景,拉去速度快。
- 推拉结合模式:也叫做读写混合,将发送方和消费者标记
- 如果订阅的消费者较多,那么采用拉模式,但是对于其标记的活跃粉丝,采用推模式,主动将消息推送给活跃粉丝。
- 如果订阅的消费者较少,那么采用拉模式。
实现
在实现FeedStream时,不能使用传统的分页模式,而要使用滚动分页的模式,记录上一次的最后时间戳,同时要记录偏移量。
Set<ZSetOperations.TypedTuple<String>> typedTuples = stringRedisTemplate.opsForZSet()
.reverseRangeByScoreWithScores(key, 0, max, offset, 2);
// key min max offset count
// zset key, 最小值,最大值,偏移量,个数
// 偏移量:上次的相同的最小值的个数
签到
使用BitMap,签到记为1。key使用year+month,因为BitMap只有32位。
- 当月签到天数
- 连续签到:使用位运算逆序查找第一个不为1的位置。
UV统计
使用HyperLogLog:
stringRedisTemplate.opsForHyperLogLog().add("key",user);
Long size = stringRedisTemplate.opsForHyperLogLog().size();
有一定的误差,但是占用内存空间很小。