zookeeper是一个高性能的,为分布式系统提供协调服务的程序。
可用作配置中心,注册中心,分布式锁的实现方式。
Replicated state machine
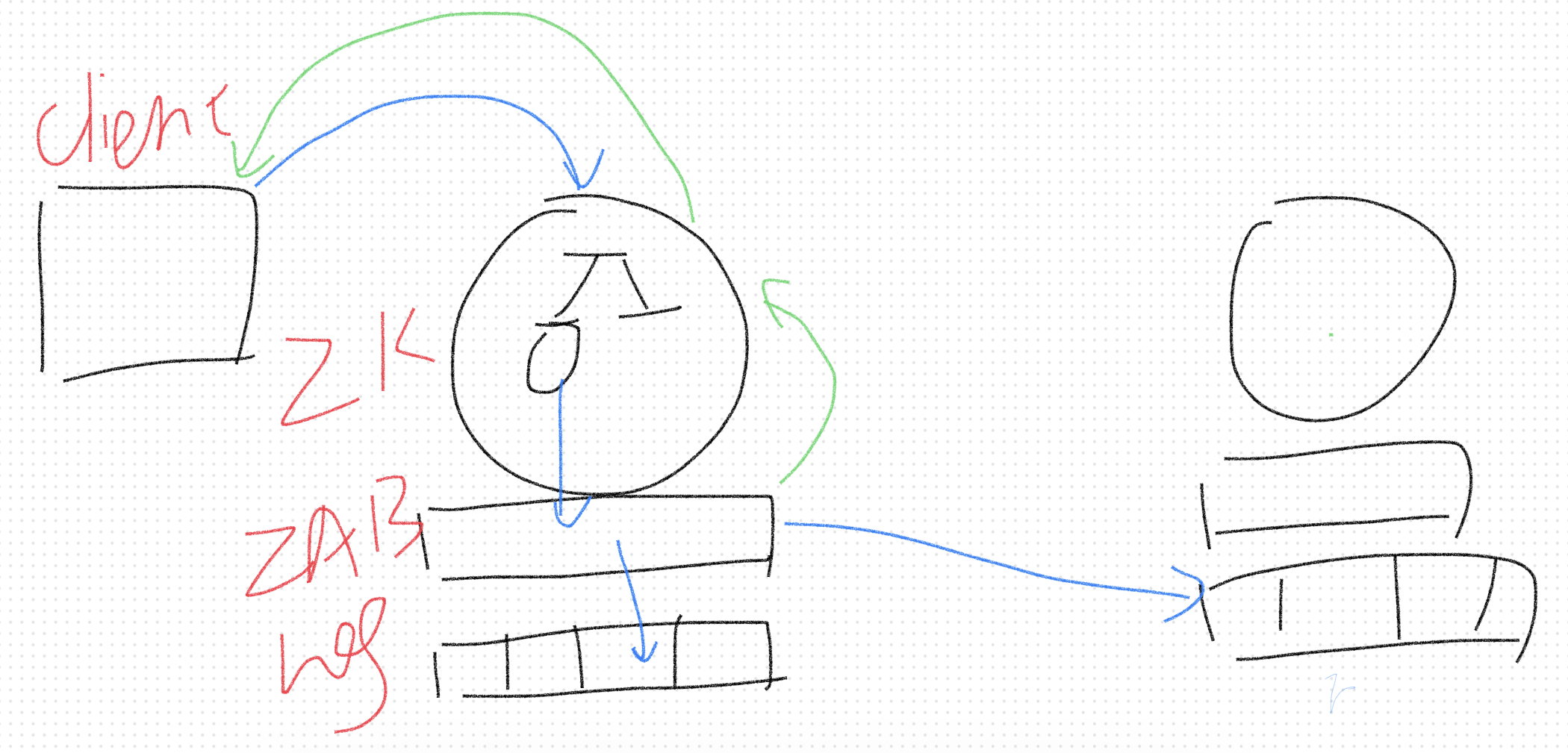
高性能
Zookeeper通过多台机器读以及操作异步化来保证高吞吐。
当请求中读操作的比例较多时,zookeeper实例越多吞吐量越高,因为读操作可以在不同的机器上进行,且不需要和master通信。
当请求中的写操作比例较多时,zookeeper实例越少吞吐量越高,写操作改变了状态,需要对状态进行同步。
Zookeeper的正确性
一致性问题
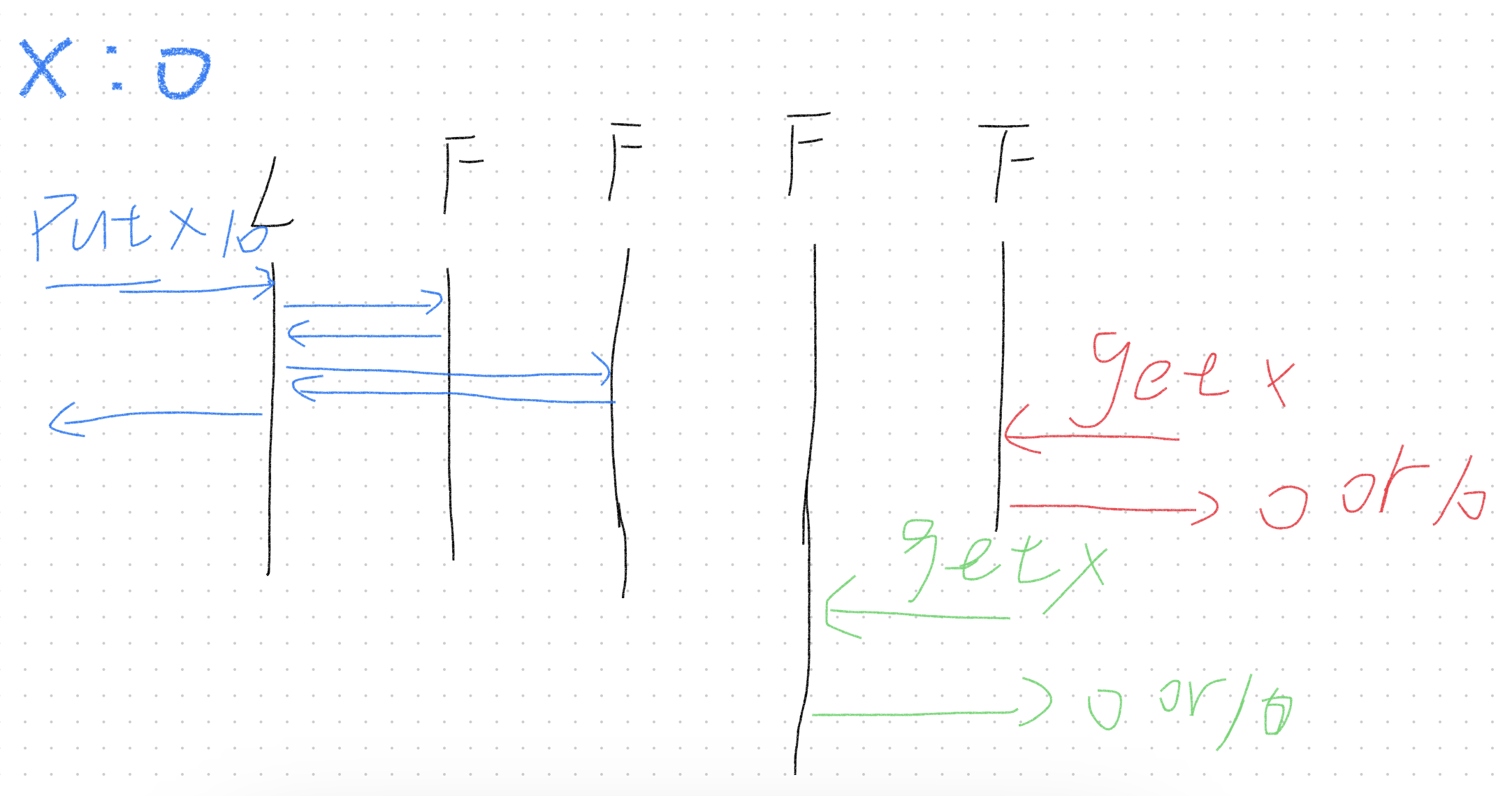
对于当前的的定义,如果有以上两个请求到达时,x的值有可能时多少?
对于第一次的读请求,由于leader获取到了大多数的保证,所以可以直接返回。但是对于下次访问时,有可能当前读操作访问数据的状态还未传播到当前访问机器,就会导致数据的不一致性。
由于存在网络分区的原因,每一次访问的实例不一定是同一个,并且zookeeper还存在负载均衡的策略。
那么假设第一次获取到了10,第二次呢?第二次也有可能访问到一个还未同步的机器,任然有可能读到脏数据。
由此可见zookeeper并不是线性一致性(强一致性)。
线性一致性(Linearizability),线性一致性需要保证满足一下三个条件:
整体操作顺序一致(total order of operations)
即使操作实际上并发进行,你仍然可以按照整体顺序对它们进行排序。(即后续可以根据读写操作的返回值,对所有读写操作整理出一个符合逻辑的整体执行顺序)
实时匹配(match real-time)
顺序和真实时间匹配,如果第一个操作在第二个操作开始前就完成,那么在整体顺序中,第一个操作必须排在第二个操作之前(换言之如果这么排序后,整体的执行结果不符合逻辑,那么就不符合"实时匹配")。
读操作总是返回最后一次写操作的结果(read return results of last write)
zookeeper一致性保证
zookeeper实际上对第二种情况做了保证,以下是zookeeper的一致性保证:
对于写操作,提供线性一致性的保证。
对于所有操作,保证客户端发来的FIFO顺序。
对于读操作,就有了以下的特点:
- 至少可以读到自己的修改。
- 有可能读不到其他客户端的修改。
- 对于同一个数据的读取,保证第二次读取一定是与第一次读取相同或更新。
zookeeper一致性原理
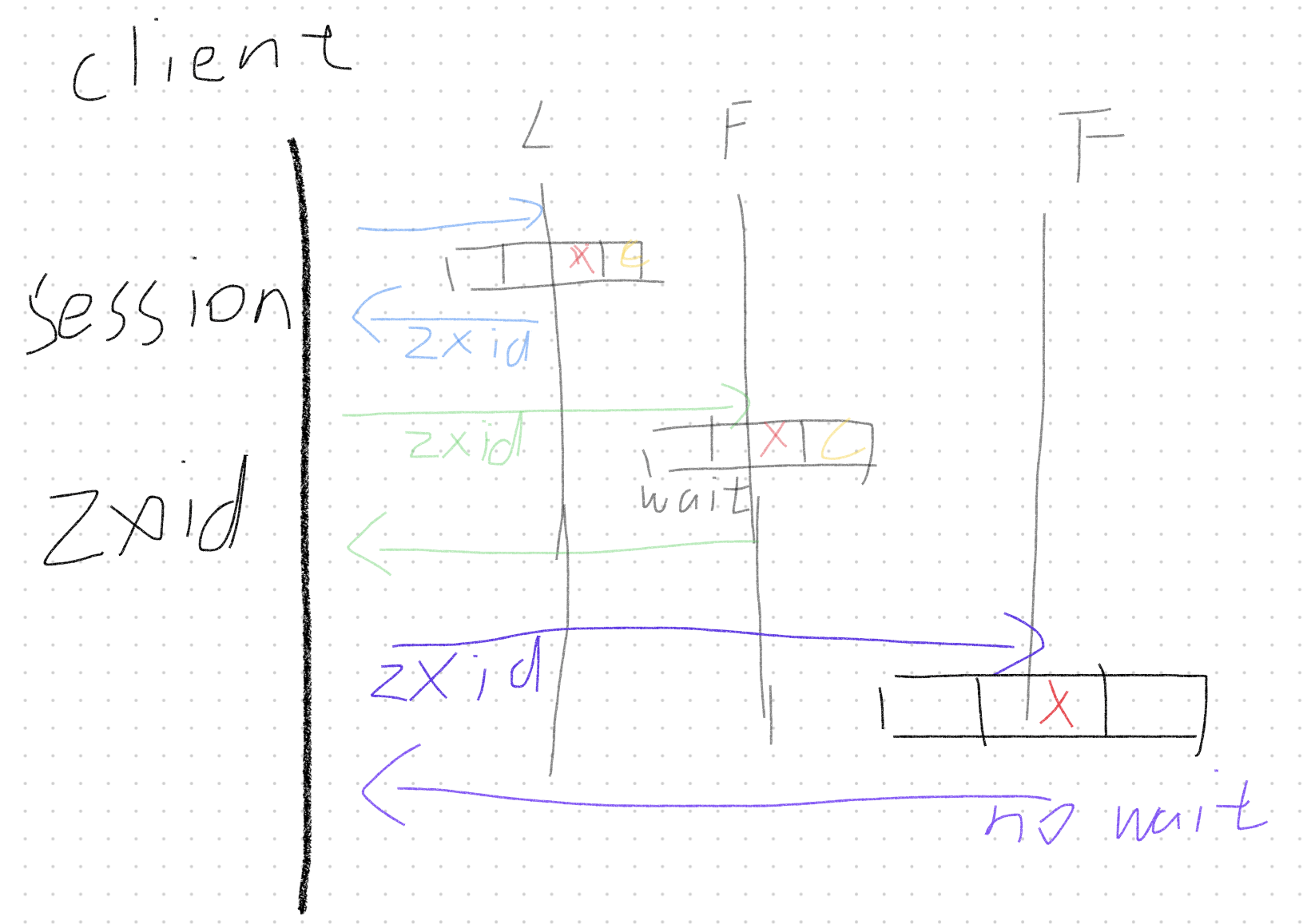
zookeeper客户端使用session来维护状态,在发送写请求时,写入成功后会返回日志的zxid,由客户端来记录保存,在随后的请求中都带上zxid。
在第二次读请求时,发现当前访问实例没有对应zxid记录,所以会阻塞等待log同步。
在最后一次读请求之前,有其他的客户端更新了日志,当时这一次请求的实例还没有同步,所以又带着上一次的zxid访问读取,这次会直接返回上一次的结果。
可以看出读请求是会存在读脏数据的,但是也是符合zookeeper的正确性定义的。
zookeeper规则
FIFO

FIFO规则保证了对于上方的命令会以FIFO的顺序进行执行,使得读取的f1和f2项是最新的。但是如果exists是位于del的前面,那么读取的f1和f2就不一定是最新的了,这时就要引入watch机制。
watch
ZooKeeper 实现的方式是通过客服端和服务端分别创建有观察者的信息列表。客户端调用 getData、exist 等接口时,首先将对应的 Watch 事件放到本地的 ZKWatchManager 中进行管理。服务端在接收到客户端的请求后根据请求类型判断是否含有 Watch 事件,并将对应事件放到 WatchManager 中进行管理。
在事件触发的时候服务端通过节点的路径信息查询相应的 Watch 事件通知给客户端,客户端在接收到通知后,首先查询本地的 ZKWatchManager 获得对应的 Watch 信息处理回调操作。这种设计不但实现了一个分布式环境下的观察者模式,而且通过将客户端和服务端各自处理 Watch 事件所需要的额外信息分别保存在两端,减少彼此通信的内容。大大提升了服务的处理性能。
需要注意的是客户端的 Watcher 机制是一次性的,触发后就会被删除,zookeeper保证被监听的写事件发生后,会在下一次写操作发生前完成事件通知。
Znode
ZNode有三种类型:
- regular:常规节点,它的容错复制了所有的东西
- ephemeral:临时节点,节点会自动消失。比如session消失或Znode有段时间没有传递heartbeat,则Zookeeper认为这个Znode到期,随后自动删除这个Znode节点
- sequential:顺序节点,它的名字和它的version有关,是在特定的znode下创建的,这些子节点在名字中带有序列号,且节点们按照序列号排序(序号递增)。
API
可以通过使用version来实现无锁并发。
- create接口,参数为path、data、flags。
create(path, data, flags),这里flags对应上面ZNode的3种类型 - delete接口,参数为path、version。
delete(path, version) - exists接口,参数为path、watch。
exists(path, watch) - getData原语,参数为path、version。
getData(path, version) - setData原语,参数为path、data、version。
setData(path, data, version) - getChildren接口,参数为path、watch。
getChildren(path, watch),可以获取特定znode的子节点
实现分布式锁
简易版
Lock:
while(true) {
if(create("/lock", EPHEMERAL)) {
break;
}
if(exists("/lock",watch)) {
wait watch
}
}
Unlock:
del("/lock")
zookeeper在应对并发创建/lock时能够保证只执行其中一个,所以只会由一个机器拿到锁。同时采用EPHEMERAL防止机器掉线后导致死锁。
在得知自己没有拿到锁后,采用watch机制监听节点变化。
当锁被删除后,使用watch机制唤醒所有等待的节点,这些节点会进行争夺,再次选出一个节点获取到锁,所以可以看出,当前的锁是非公平的。
同时,如果有1000个节点同时获取锁,当第一个节点释放锁后,zookeeper服务器会收到999个请求,随后是998,997....。这被称为羊群效应,对zookeeper服务器是一种很大的负担:深入解析集群的羊群效应。
优化版
Lock:
// 在同一前缀下以临时和有序的特性创建znode
n = create(prefix + "/lock-", EPHEMERAL | SEQUENTIAL)
// 获取前缀下的所有子节点
C = getChildren(prefix, false)
// 如果当前节点是最小的节点,代表获取到锁,退出
if n is lowest znode in C, exit
// 否则监听当前节点的前一个节点
p = znode in C ordered just before n
if exists(p, true) wait for watch event
goto 5
Unlock
delete(n)
这样就可以采用类似java中AQS 的处理形式,由前一个节点负责唤醒后一个节点。