本文介绍生成分布式id的一种方法,雪花算法。
雪花算法
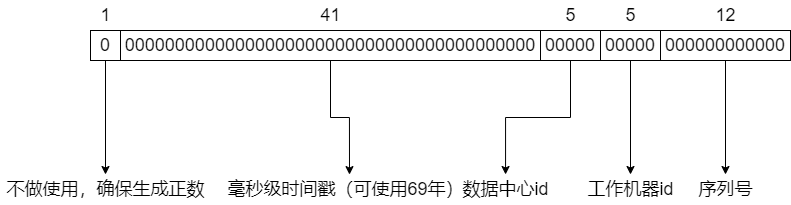
序列号保证了在高并发的情况下可以生成不重复的id。
时间戳保证了雪花算法生成的id是趋势递增的,很大程度上保证了B+树索引插入的性能,适合于做主键。
机器ID分配
首先是如何对数据中心id和工作机器id进行区分。
mp的做法是采用MAC地址以及进程的PID,但是这样也有可能重复,因为对于10位的数字,取余是无法避免哈希冲突的,尽管概率很小。
下面是两种解决方案:
预分配
人工分配,缺点是无法扩容。
动态分配
将id放入中间件中,服务启动时去中间件中请求,通常采用redis+lua的方式。
redis维护hash结构,放入两个key:datacenterId,workId。
local hashKey = 'snowflake_work_id_key'
local dataCenterIdKey = 'dataCenterId'
local workIdKey = 'workId'
-- 如果当前hash不存在,则初始化
if (redis.call('exists', hashKey) == 0) then
redis.call('hincrby', hashKey, dataCenterIdKey, 0)
redis.call('hincrby', hashKey, workIdKey, 0)
return { 0, 0 }
end
-- 获取当前dataCenterId和workId
local dataCenterId = tonumber(redis.call('hget', hashKey, dataCenterIdKey))
local workId = tonumber(redis.call('hget', hashKey, workIdKey))
local max = 31
local resultWorkId = 0
local resultDataCenterId = 0
-- 如果当前dataCenterId和workId都是最大值,则重置为0
if (dataCenterId == max and workId == max) then
redis.call('hset', hashKey, dataCenterIdKey, '0')
redis.call('hset', hashKey, workIdKey, '0')
-- 先去获取workId,如果workId不是最大值,则workId+1,dataCenterId不变
elseif (workId ~= max) then
resultWorkId = redis.call('hincrby', hashKey, workIdKey, 1)
resultDataCenterId = dataCenterId
-- 如果当前dataCenterId不是最大值,workId为最大值,则workId重置为0,dataCenterId+1
elseif (dataCenterId ~= max) then
resultWorkId = 0
resultDataCenterId = redis.call('hincrby', hashKey, dataCenterIdKey, 1)
redis.call('hset', hashKey, workIdKey, '0')
end
return { resultWorkId, resultDataCenterId }
在1024节点下可以保证服务id唯一。
问题
时钟回拨
如果机器的时钟回拨,则生成的id可能会重复(人工调整,NTP调整)。
设置容忍范围,如果大于容忍范围需要直接抛出异常,结束流程。
序列号不够用
序列号是用于解决毫秒级并发的问题,如果lastTimestamp等于当前的timestamp,说明发生了毫秒级并发。我们就需要使用计数器进行自增。
如果并发超过了4096,对于新到的请求,我们就必须停止生成id,等到下一毫秒,注意这里不需要加锁,循环获取当前时间戳即可。
毫秒级并发超过4096,那么单台机器TPS就到达了四百万,对于大部分实际场景都够用了。
机器ID不够用
如果机器ID不够分配,我们只能从ID的划分下手。
一是时间戳,我们如果减少一位,时间戳的可用年数就减少到35年左右,是否要减少时间戳这个需要自己衡量。
二是序列号,如果减少序列号,单台机器的TPS的最大值就会减少。
性能
在实际代码中,Java会涉及到取当前的毫秒时间戳的操作System.currentTimeMillis(),这是极其耗时的。调用的是native方法,会陷入内核态,当多个线程同时请求时还会加大竞争,结果也不稳定。所以在这里引入了单例模式,由于雪花算法的时间戳是毫秒级,所以在同一毫秒内的时间戳相同,就可以将其缓存起来,hutool的SystemClock是一个不错的选择。
高并发下System.currentTimeMillis()竟然有这么大的问题
分库分表
和基因法结合,假设取4位,将最后的序列号去掉四位和基因数字融合,然后再按照最后四位进行分库分表。可以使得相同基因的记录分在相同的库/表中。