第二节课主要以代码的形式讲解了一下RPC以及golang并发编程,看完之后就可以完成lab1。这里直接开始第三节课。
存储
还记的分布式系统的三大基础架构:存储,计算,通信。通过前两节的MapReduce和RPC,计算和通信已经讲解过了,这一节介绍了存储以及谷歌的解决方案GFS。
设计难点
并发性问题举例: W1写1,W2写2;R1和R2准备读取数据。W1和W2并发写,在不关心谁先谁后的情况下,考虑一致性,则我们希望R1和R2都读取到1或者都读取到2,R1和R2读取的值应该一致。(可通过分布式锁等机制解决)
故障/失败问题举例:
一般为了容错性,会通过复制的方式解决。而不成熟的复制操作,会导致读者在不做修改的情况下读取到两次不同的数据。比如,我们要求所有写者写数据时,需要往S1和S2都写一份。此时W1和W2并发地分别写1和2到S1、S2,而R1和R2即使在W1和W2都完成写数操作后,再从S1或S2读数时结果可能是1也可能是2(因为没有明确的协议指出这里W1和W2的数据在S1、S2上以什么方式存储,可能1被2覆盖,反之亦然)。
GFS
每一个分布式系统都是按照它的应用场景的特点来设计的,GFS就是为MapReduce而设计的。在这里,需要的是高吞吐,高性能,且有容错。
假设有10台机器,而每一台机器的IO极限带宽为30MB/s,GFS就可以达到300MB/s的总带宽。GFS的论文
特征
- big data set
- fast:automatic sharding
- global:for all apps GFS has the same view
- FT:automatic recover
数据读取
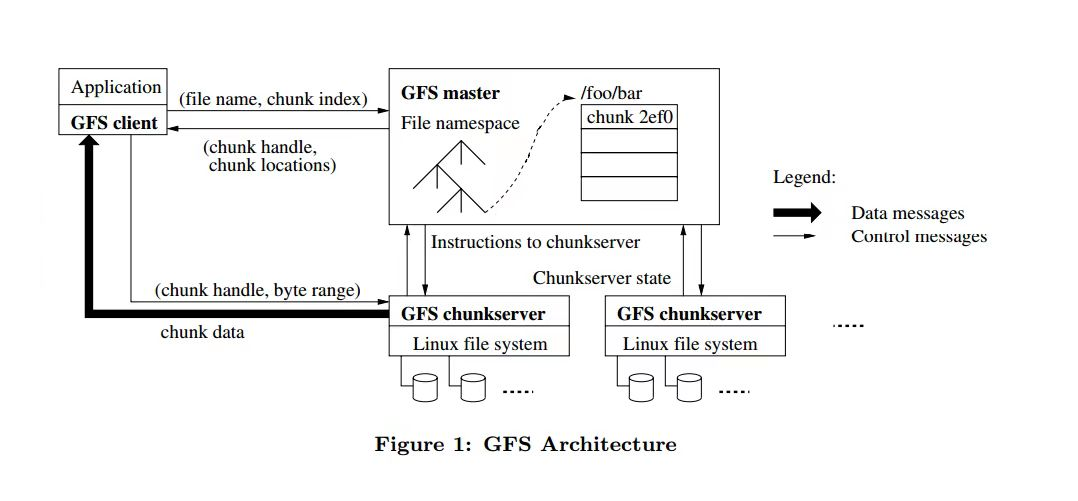
Master
在GFS设计中master是single system,并且为了能够更快的响应,数据存放在内存中。
数据:
filename <---> chunk handle
chunk handle <---> version + List of chunk server
chunk server <---> primary server + some secondaries server
- primary server 还存放着租约事件,在这个事件内primary是有效的
log + checkpoint ,参见ostep-persistence中的崩溃日志一章。
其中,第一条和第二条中的version需要被安全的持久化起来,其他的可以通过和chunk server沟通获取。
读取
以下文字来源于参考笔记。
Client向Master发请求,要求读取X文件的Y偏移量的数据
Master回复Client,X文件Y偏移量相关的块句柄、块服务器列表、版本号(chunk handle, list of chunk servers, version)
Client 缓存cache块服务器列表(list of chunk servers)
Client从最近的服务器请求chunk数据(reads from closest servers)
被Client访问的chunk server检查version,version正确则返回数据
写入
以下文字来源于参考笔记。
Client向Master发出请求,查询应该往哪里写入filename对应的文件。
Master查询filename到chunk handle映射关系的表,找到需要修改的chunk handle后,再查询chunk handle到chunk server数组映射关系的表,以list of chunk servers(primary、secondaries、version信息)作为Client请求的响应结果
接下去有两种情况,已有primary和没有primary(假设这是系统刚启动后不久,还没有primary)
有primary:继续后续流程
无primary
- master在chunk servers中选出一个作为primary,其余的chunk server作为secondaries。(暂时不考虑选出的细节和步骤)
- master会增加version(每次有新的primary时,都需要考虑时进入了一个new epoch,所以需要维护新的version),然后向primary和secondaries发送新的version,并且会发给primary有效期限的租约lease。这里primary和secondaries需要将version存储到磁盘,否则重启后内存数据丢失,无法让master信服自己拥有最新version的数据(同理Master也是将version存储在磁盘中)。
- Client发送数据到想写入的chunk servers(primary和secondaries),有趣的是,这里Client只需访问最近的secondary,而这个被访问的secondary会将数据也转发到列表中的下一个chunk server,此时数据还不会真正被chunk severs存储。(即上图中间黑色粗箭头,secondary收到数据后,马上将数据推送到其他本次需要写的chunk server)
这么做提高了Client的吞吐量,避免Client本身需要消耗大量网络接口资源往primary和多个secondaries都发送数据。
数据传递完毕后,Client向primary发送一个message,表明本次为append操作。primary此时需要做几件事:
- primary此时会检查version,如果version不匹配,那么Client的操作会被拒绝
- primary检查lease是否还有效,如果自己的lease无效了,则不再接受任何mutation operations(因为租约无效时,外部可能已经存在一个新的primary了)
- 如果version、lease都有效,那么primary会选择一个offset用于写入
- primary将前面接收到的数据写入稳定存储中
primary发送消息到secondaries,表示需要将之前接收的数据写入指定的offset
secondaries写入数据到primary指定的offset中,并回应primary已完成数据写入
primary回应Client,你想append追加的数据已完成写入
当然,存在一些情况导致数据append失败,此时primary本身写入成功,但是后续存在某些/某个secondaries写入失败,此时会向Client返回错误error。Client遇到这种错误后,通常会retry整个流程直到数据成功append,这也就是所谓的最少一次语义(do at-least-once)。