frangipani是一个分布式下的文件系统,它的初衷是运行在共享不太频繁的组织中,例如工程师每个人都专注自己的文档,可能会共享,但是没有那么频繁。它提供了很高的性能(操作在本地内存),以及分布式的崩溃恢复。
简述
Frangipani中没有专门的file server角色,每个client本身就作为file server,因为client本身运行file server code。
这里所有的client共享一个虚拟磁盘(virtual disk),这个虚拟磁盘内部使用Petal实现,由数个机器构成,机器复制磁盘块(disk blocks),内部通过Paxos共识算法保证操作按正确顺序应用等。
虚拟磁盘对外的接口是read块(read block)或write块(write block),看上去就像普通的磁盘。
在Frangipani这种设计下,复杂的设计更多在于client。可以通过增加工作站(workstation)数量来拓展文件系统。通过增加client数量,每个client都可以在自己的文件系统上运行,许多繁重的计算都可以在client机器上完成,根本不涉及任何文件系统服务器。而传统的网络文件系统的性能瓶颈往往出现在文件服务器。
挑战
正如涉及目标所述,Frangipani的涉及面临下面的难点:
假设WS1工作站1执行read f的操作,之后通过本地cache对f通过vi进行操作。这时需要考虑几个可能发生的场景如何处理:
WS2 cat f
工作站2查看f文件,这时需要通过**缓存一致性(cache conference)**确保工作站2能看到正确的内容。
WS1创建d/f,WS2创建d/g
需要保证WS1创建d目录下的f文件,以及WS2创建d目录下的g文件时,双方不会因为创建目录导致对方的文件被覆盖或消失等问题。这里需要**原子性(atomicity)**保证操作之间不会互相影响。
WS1 crash during FS op
工作站1进行复杂的文件操作时发生崩溃crash。需要**崩溃恢复(crash recovery)**机制。
缓存一致性
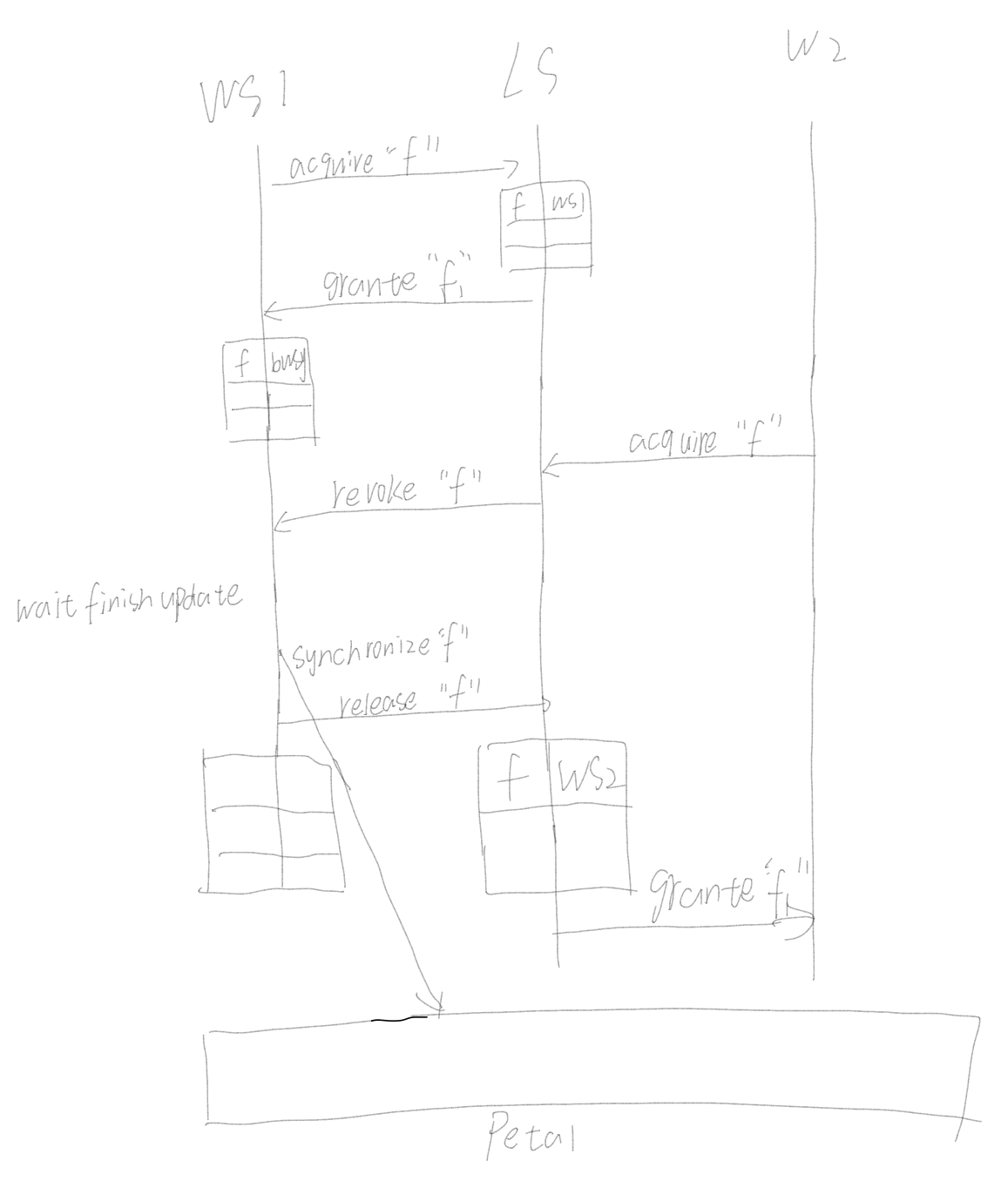
Frangipani主要通过lock锁机制实现缓存一致性。
| file inode | owner |
|---|---|
| f | ws1 |
| g | ws1 |
| h | ws2 |
锁服务器(lock server)维护一张表table,里面维护每个file对应的inode编号,以及锁的owner拥有者对应哪个工作站。这里lock server本身是一个分布式服务,可以想象成类似zookeeepr,其提供加锁/解锁接口,且服务具有容错性。
| file inode | State |
|---|---|
| f | busy |
| g | idle |
同时,工作站自身也需要维护一张table,table维护lock对应的状态,比如f文件锁对应的状态为busy,g文件锁对应的状态为idle,表示g这一时刻没有被修改。这里idle状态的锁被称为粘性锁(sticky lock)。注意本地的锁和服务器的锁是分开的。
缓存文件之前,需要先获取锁,通过锁来保证只有一端能够更改文件内容,自然的就保证了缓存的一致性。
协议
在WS和LS之间通信,会使用4种消息:
- 请求锁,requesting a lock
- 授予锁,granting a lock
- 撤销锁,revoking a lock
- 释放锁,releasing a lock
原子性
acquire("d") // 获取目录d的锁
create("f" ,....) // 创建文件f
acquire("f") // 获取文件f的inode锁
allocate inode // 分配f文件对应的inode
write inode // 写inode信息
update directory ("f", ...) // 关联f对应的inode到d目录下
release("f") // 释放f对应的inode锁
release("d") // 释放目录d对应的锁
崩溃恢复
Frangipani的崩溃恢复的本质是使用了WAL技术,通过预先写入日志,保证在更新时宕机可以被恢复。
当复制发生时(即LS向WS发送revoke撤销锁后,WS需要将文件变更同步到Petal),经过以下流程:
- 将本地的log发送到Petal。
- 发送更新块到Petal。
- 释放锁。
每台Frangipani服务器都有log日志,log中的log entry拥有序列号(sequence number)。log entry中存放更新数组(array of updates),用于描述文件系统操作,包含以下内容:
- 需要更新的块号(block number that needs to be updated),对应inode编号
- 版本号(version number),
- 块编号对应的新字节数据(new bytes)
实际上,文件数据(file data)写入不会通过日志,而是直接传递给Petal。通过日志的更新是元数据(meta data)更改。元数据的含义是关于file文件的信息,比如inode、目录等,这些会通过log。应用级数据,实际构成文件的文件块直接写入到Petal,而不需要通过log。
Unix设计: 对于需要原子写文件的场景,通常人们通过先将所有数据写入一个临时文件,然后做一个原子重命名(atomic rename),使得临时文件编程最终需要的文件
崩溃场景分析
写入日志前
数据丢失
写入日志后
假设写log到Petal后WS1崩溃,此时WS1占有log,如果WS2想要获取同一个文件inode的lock,LS会等待WS1的lock租约过期后,要求剩余的WS的recovery damon读取WS1的log,并应用log中记录的操作。等待damon工作完成后,LS重新分配锁,即授予WS2锁。
写入日志中
文件中包括前缀,如果写log中崩溃,那么文件的校验和检验就不会通过,recovery demon会停止在检验和不通过的记录之前。
版本号
在写入后,未写入日志前的崩溃,在recovery damon的恢复中,可能会出现操作被覆盖的情况,所以对每一个inode引入了version属性:
- WS1在log中记录
delete ('d/f'),删除d目录下的f文件。log的版本号假设为10 - WS2在log中记录
create('d/f'),log的版本号为11(因为锁保证了log的版本号是完全有序的) - WS1崩溃
- WS3观察到WS1崩溃,为WS1启动一个recovery demon,准备执行WS1的log记录
delete('d/f'),但是发现Petal中已应用的log对应的version版本号为11,高于log或inode的version,准备重放的log的version为10,小于等于11,所以demon会放弃重放这个log。