链表创建有两种方式,一种是:
struct Node
{
int num;
Node* next;
}
这种动态创建链表在new新节点的方式很慢
另一种就是用数组模拟链表
单链表
在单链表中,用的最多的时邻接表,常常用它来存储树和图
一般使用e数组存储节点的值,ne数组存储下一个位置的指针
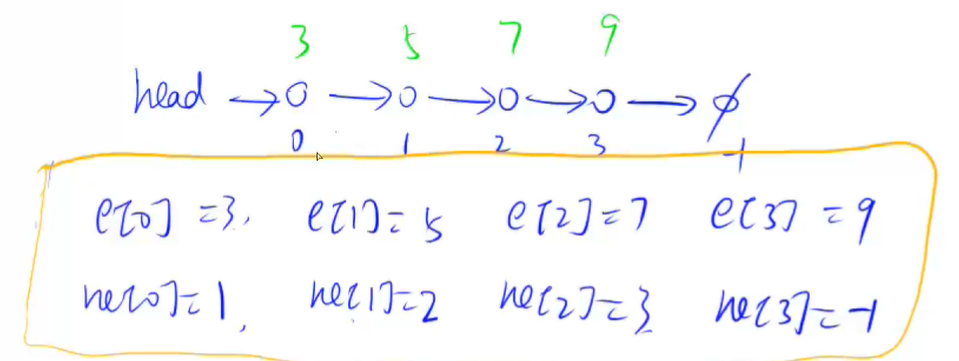
实现
#include<bits/stdc++.h>
using namespace std;
const int N=1e5+10;
// head中存的是头节点的下标,idx中存的是当前可以用哪个点
int head=-1,idx=0;
int e[N],ne[N];//ne是指向下一个节点
void add_head(int x){ //一般用的都是头插法
e[idx]=x;
ne[idx]=head;
head=idx++;
}
void move(int k){
ne[k]=ne[ne[k]];
}
void insert(int k,int x){
e[idx]=x;
ne[idx]=ne[k];
ne[k]=idx++;
}
int main(){
int m;
cin>>m;
while(m--){
char a;
int x,p;
cin>>a;
if(a=='H'){
cin>>x;
add_head(x);
}
else if(a=='D'){
cin>>x;
if (!x) head = ne[head];
move(x-1);
}
else{
cin>>x>>p;
insert(x-1,p);
}
}
for(int i=head;i!=-1;i=ne[i]){
cout<<e[i]<<" ";
}
return 0;
}
双链表
用于优化某些问题,双链表即引入了左指针,基本原理和单链表一样
实现
#include <bits/stdc++.h>
using namespace std;
const int N=1e6+10;
int idx,m;
int l[N],r[N],e[N];
void add(int k,int x){//函数本身是在k点右边插入一个数
e[idx]=x;//先将数值存入
l[idx]=k;//四条边模拟链接,顺序不能变
r[idx]=r[k];
l[r[k]]=idx;
r[k]=idx++;
}
void move(int k){//删除就是使当前点的两边跳过这个点直接产生联系
l[r[k]]=l[k];
r[l[k]]=r[k];
}
int main(){
cin>>m;
r[0]=1;//e【0】为头节点,e【1】为尾节点,l是指向左边元素的指针,r指向右边,idx是目前用到的下标。初始化为空表
l[1]=0;
idx=2;
while(m--){
string a;
cin>>a;
if(a=="L"){
int x;
cin>>x;
add(0,x);
}
else if(a=="R"){
int x;
cin>>x;
add(l[1],x);//倒数第二个点的右边
}
else if(a=="D"){
int k;
cin>>k;
move(k+1);
}
else if(a=="IL"){
int k,x;
cin>>k>>x;
add(l[k+1],x);//在该点左边的点向右边插入一个点
}
else{
int k,x;
cin>>k>>x;
add(k+1,x);//因为我们是从0开始计数所以减一但是有两个结点被占用所以加二,则为加一
}
}
for(int i=r[0];i!=1;i=r[i]) cout<<e[i]<<" ";
return 0;
}