复制状态机(RSM)
一个状态机开始于给定的开始状态。每个收到的输入都通过过渡方程和输出方程来产生一个新的状态以及相应的输出。这个新的状态会一直保持到下一个输入到达,产生的输出会传递给相应的接收者。
分布式服务中要求状态机具有确定性:同一状态机的多个副本以“开始”状态开始,并且以相同顺序接收相同输入将到达已生成相同输出的相同状态。这也就是复制状态机的理解,复制状态机。
这里介绍了两种创建复制状态机的方式:
分布式共识算法:利用Paxos、Raft、ZAB等分布式共识算法,保证多副本之间的一致性。
Configuration service + P/B replication(primary backup replication):一个配置服务器(为了可用性可能运行这分布式共识算法)+ 业务服务器(主备复制)
通常采用第二个方式:
- 复制服务在状态state维护的成本较低,一般需要维护的数据量很少
- 主备复制则主要负责大量的数据复制工作
链式复制
链式复制是主备复制的一种实现方案,它由如下特点:
- 读和写都只涉及不同的两个服务器。
- 恢复方案简单。
- 线性一致。
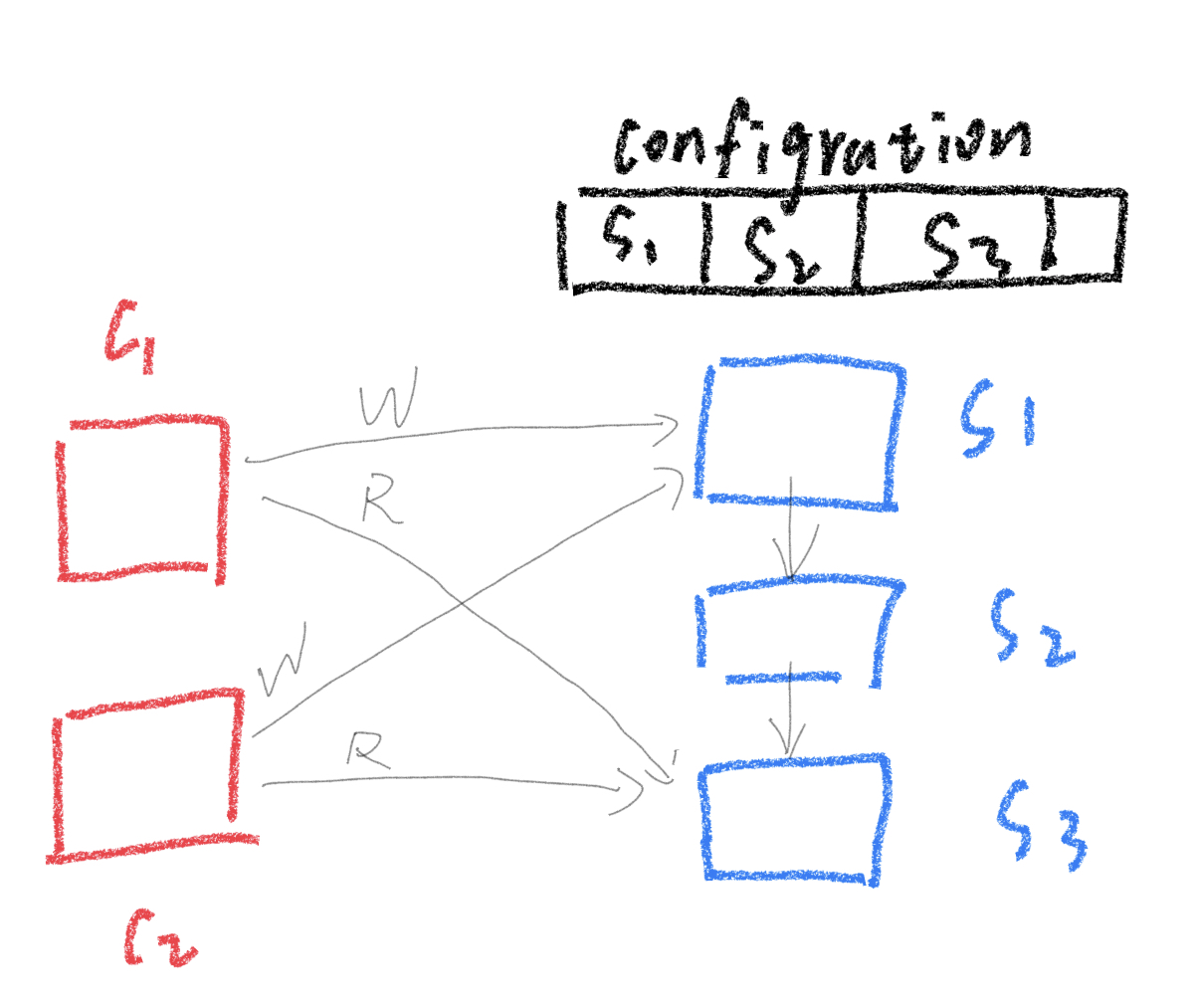
通过一个配置服务(configuration service)记录链式连接的节点信息,记录当前的节点信息,维护节点状态。 如果需要更高的可用性(容错性),可以增加链中的节点数量。
写请求流程:
- client向系统发起write请求,写请求总是会发送到链中的head节点服务器
- head节点生成log等,通过storage稳定存储更新相关state状态,然后传递操作到下一个节点
- 下一个节点同样更新自己storage中的state状态,然后向下一个节点传递操作
- 直到最后一个tail尾节点,修改storage中的状态后,向client回应确认信息。
tail尾节点就是提交点(commit point),后续读取总是从tail尾节点获取。所有的请求只有到达最后一个服务器后才能被读取,而所有的请求都是按照到达顺序从head到tail依次应用(TCP保证),这样就提供了线性一致性。任何client发起读请求,都会请求tail节点,而tail节点会立即响应。
崩溃
节点的三种状态:头节点,尾节点,中间节点。所有的故障恢复都可以归结于三种情况。假设有:S1->S2->s3。
头节点故障(处理最简单)
假设client请求head时,head崩溃了。那么这里S1未向下同步的log记录可以丢弃,因为还没有真正commit。此时,配置服务器得知S1宕机后,会通知S2、S3,宣布S2称为新的head,而S1被抛弃。之后client请求失败后会重试,请求新的head,S2节点。
中间节点故障(处理相对复杂)
类似的,S2故障后,某一时刻配置服务器通知S1和S3需要组成新的链。并且由于S3可能还没有和S1同步到最新状态(因为有些同步log可能还在S2没有下发,或者本身S2也没有完全同步到S1的l信息),所以还需要额外进行同步流程,将S3同步到和S1一致的状态。
尾节点故障(处理相对简单)
S3故障后,配置服务器通知S1、S2组成新链,其中S2成为新的tail。client可以从配置服务器知道S2是新tail。其他的流程基本没变动。
新增
在tail添加新replica最简单,大致流程如下:
- 假设原tail节点S2下新增S3节点,此时client依旧和原tail节点S2交互
- S2会持续将同步信息传递给S3(全量),并且记录哪些log已经同步到S3
- 由于全量更新需要很长的时间,所以S2会记录一个更新列表。
- 当S3全量更新完成后,向S2发出请求,S2响应并且将更新列表一同传给S3。
- 配置服务设置S3为新tail
- 后续client改成请求tail节点获取读写响应(client可以通过配置服务知道谁是head、tail)
并行读优化
由于链式复制中,只需要tail响应read请求,这里可以做一些优化的工作,进一步提高read吞吐量。
思路是进行拆分(split)对象,论文中称之为volume,将对象拆分到多个链中(splits object across many chain)。
例如,现在有3个节点S1~S3,我们可以构造3个Chain链:
- Chain1:S1、S2、S3 (tail)
- Chain2:S2、S3、S1 (tail)
- Chian3:S3、S1、S2 (tail)
注意这里一共只有三个服务器,并不是九个。
这里可以通过配置服务进行一些数据分片shard操作。如果数据被均匀write到Chain1~Chain3,那么读操作可以并行地命中不同的shards,均匀分布下,读吞吐量(read throughput)会线性增加,理想情况下这里能得到3倍的吞吐量。
拆分(split)的好处:
- 得到扩展(scale),read吞吐量提高(shard越多,chain越多,read吞吐量理论上越高)
- 保持线性一致性(linearizability)
和Raft相比
从复制的角度出发,比较一下链式复制CR(Chain Replication)和Raft。
CR比起Raft的优势:
CR拆分请求RPC负载到head和tail
前面说过CR的head负责接收write请求,而tail节点负责响应wrtie请求和接收并响应read请求。不必像Raft还需要通过leader完成write、read请求
head头节点仅发送update一次
不同于Raft的leader需要向其他所有followers都发送update,CR的head节点只需要向链中的下一个节点发送update。
读操作只涉及tail节点(read ops involve only tail)
尽管Raft做了read优化,follower就算要处理read请求,还是得向其他leader、followers发送同步log,确定自己是否能够响应read(因为follower可能正好没有最新的数据)。而CR中,只需要tail负责read请求,并且tail一定能同步到最新的write数据(因为write的commit point就是tail节点)。
简单的崩溃恢复机制(simple crash recovery)
与Raft相比,CR的崩溃处理更简单。
CR比起Raft的劣势:
一个节点故障就需要重新配置(one failure requires reconfiguration)
因为写入操作需要同步到整个链,写入操作无法确认链中每台机器是否都执行,所以一有fail,就需要重新配置,这意味着中间会有一小段时间的停机。而Raft中只需要majority满足write持久化,就可以继续工作。