Golang
GMP
- G:Goroutine 的缩写,每次 go func() 都代表一个 G,无限制,但受内存影响。使用 struct runtime.g,包含了当前 goroutine 的状态、堆栈、上下文
- M:工作线程(OS thread)也被称为 Machine,使用 struct runtime.m,所有 M 是有线程栈的。M 的默认数量限制是 10000(来源),可以通过debug.SetMaxThreads修改。
- P:Processor,是一个抽象的概念,并不是真正的物理 CPU,P 表示执行 Go 代码所需的资源,可以通过 GOMAXPROCS 进行修改。
当 M 执行 Go 代码时,会先关联 P。当 M 空闲或者处在系统调用时,就需要 P。

go func()流程

1、我们通过 go func () 来创建一个 goroutine;
2、有两个存储 G 的队列,一个是局部调度器 P 的本地队列、一个是全局 G 队列。新创建的 G 会先保存在 P 的本地队列中,如果 P 的本地队列已经满了就会保存在全局的队列中;
3、G 只能运行在 M 中,一个 M 必须持有一个 P,M 与 P 是 1:1 的关系。M 会从 P 的本地队列弹出一个可执行状态的 G 来执行,如果 P 的本地队列为空,就会想其他的 MP 组合偷取一个可执行的 G 来执行;
4、一个 M 调度 G 执行的过程是一个循环机制;
5、当 M 执行某一个 G 时候如果发生了 syscall 或则其余阻塞操作,M 会阻塞,如果当前有一些 G 在执行,runtime 会把这个线程 M 从 P 中摘除 (detach),然后再创建一个新的操作系统的线程 (如果有空闲的线程可用就复用空闲线程) 来服务于这个 P;
6、当 M 系统调用结束时候,这个 G 会尝试获取一个空闲的 P 执行,并放入到这个 P 的本地队列。如果获取不到 P,那么这个线程 M 变成休眠状态, 加入到空闲线程中,然后这个 G 会被放入全局队列中。
Channel
底层
type hchan struct {
qcount uint // 循环队列元素的数量
dataqsiz uint // 循环队列的大小
buf unsafe.Pointer // 循环队列缓冲区的数据指针
elemsize uint16 // chan中元素的大小
closed uint32 // 是否已close
elemtype *_type // chan 中元素类型
sendx uint // send 发送操作在 buf 中的位置
recvx uint // recv 接收操作在 buf 中的位置
recvq waitq // receiver的等待队列
sendq waitq // senderl的等待队列
lock mutex // 互斥锁,保护所有字段
}
- qcount:代表循环队列 chan 中已经接收但还没被取走的元素的个数。
- datagsiz 循环队列 chan 的大小。选用了一个循环队列来存放元素,类似于队列的生产者 - 消费者场景
- buf:存放元素的循环队列的 buffer。
- elemtype 和 elemsize:循环队列 chan 中元素的类型和 size。chan 一旦声明,它的元素类型是固定的,即普通类型或者指针类型,元素大小自然也就固定了。
- sendx:处理发送数据的指针在 buf 中的位置。一旦接收了新的数据,指针就会加上 elemsize,移向下一个位置。buf 的总大小是 elemsize 的整数倍,而且 buf 是一个循环列表。
- recvx:处理接收请求时的指针在 buf 中的位置。一旦取出数据,指针会移动到下一个位置。
- recvq:chan 是多生产者多消费者的模式,如果消费者因为没有数据可读而被阻塞了,就会被加入到 recvq 队列中。
- sendq:如果生产者因为 buf 满了而阻塞,会被加入到 sendq 队列中。
缓冲
对于无缓冲区channel:
发送的数据如果没有被接收方接收,那么**发送方阻塞;**如果一直接收不到发送方的数据,接收方阻塞;
有缓冲的channel:
发送方在缓冲区满的时候阻塞,接收方不阻塞;接收方在缓冲区为空的时候阻塞,发送方不阻塞。
Closed
向Closed的channel写: panic: send on closed channel
向Closed的channel读:不会阻塞,通过 res,ok <- channel 的ok属性得知是否关闭
Sync.Map
采用读写分离的架构,先操作ReadOnlyMap,若不存在,再操作dirtyMap。操作只读Map是无锁的,操作脏Map是加Mutex的。当dirty miss 的数量多了后,dirty会提升为readonly,适用于读多写少场景。
Java
Java基础
java和c++
跨平台
GC
Java是c++的派生,少了许多东西:运算符重载,多继承(可以实现多个接口)
特性
封装(Encapsulation)是面向对象方法的重要原则,就是把对象的属性和操作(或服务)结合为一个独立的整体,并尽可能隐藏对象的内部实现细节。
继承就是子类继承父类的特征和行为,使得子类对象(实例)具有父类的实例域和方法,或子类从父类继承方法,使得子类具有父类相同的行为。当然,如果在父类中拥有私有属性(private修饰),则子类是不能被继承的。
多态:父类引用指向子类,调用父类方法实际上时子类方法。用于函数入参,参数类型可以设置未父类但是有不同的结果。
引用和指针
引用是变量的别名,指针是地址。
Java中的引用更像是指针有地址,但是有限制,无法进行计算
为什么要重写equals和hashcode
对于引用类型,== 判断的是地址是否相等,重写equals来达到属性相等即对象相等。
而hashcode返回了当前对象的hash值,用于快速判断两个对象是否相等。
所以重写equals的同时必须重写hashcode方法,不然会导致不一致的情况。
判断对象是否相等:
- 比较hashcode,若不等,则一定不相等。
- 若hashcode相等,则使用equals方法验证。
HashSet在插入时就是用的上面的方法。
反射
Class clazz = Class.forName("com.itwanger.s39.Writer");
Constructor constructor = clazz.getConstructor();
Object object = constructor.newInstance();
Method setNameMethod = clazz.getMethod("setName", String.class);
setNameMethod.invoke(object, "沉默王二");
Method getNameMethod = clazz.getMethod("getName");
- 开发通用框架:像 Spring,为了保持通用性,通过配置文件来加载不同的对象,调用不同的方法。
- 动态代理:在面向切面编程中,需要拦截特定的方法,就会选择动态代理的方式,而动态代理的底层技术就是反射。
- 注解:注解本身只是起到一个标记符的作用,它需要利用发射机制,根据标记符去执行特定的行为。
String
- 操作少量的数据: 适用
String - 单线程操作字符串缓冲区下操作大量数据: 适用
StringBuilder - 多线程操作字符串缓冲区下操作大量数据: 适用
StringBuffer
在循环中使用加号拼接字符串,会不断的创建StringBuilder对象,推荐在循环外手动创建StringBuilder对象调用append对象。
String s1 = new String("abc");这句话创建了几个字符串对象?
字符串符串常量池中不存在 "abc":会创建 2 个 字符串对象。一个在字符串常量池中,由 ldc 指令触发创建。一个在堆中,由 new String() 创建,并使用常量池中的 "abc" 进行初始化。
字符串常量池中已存在 "abc":会创建 1 个 字符串对象。该对象在堆中,由 new String() 创建,并使用常量池中的 "abc" 进行初始化。
字符串常量池中的字符串会重复使用,对于String s = "abc"。
注解
注解的解析方法有哪几种?
注解只有被解析之后才会生效,常见的解析方法有两种:
- 编译期直接扫描:编译器在编译 Java 代码的时候扫描对应的注解并处理,比如某个方法使用
@Override注解,编译器在编译的时候就会检测当前的方法是否重写了父类对应的方法。 - 运行期通过反射处理:像框架中自带的注解(比如 Spring 框架的
@Value、@Component)都是通过反射来进行处理的。
Java集合
HashMap的长度为什么是2的幂次方
因为hashCode的范围是-2^31~2^31-1,加起来大概40亿的映射空间,内存存放不下,所以我们需要对长度进行取模处理。并且在n == 2^n的情况下,使用hashCode & (n - 1)是和hashCode % n相等的,加快运算速度。
HashMap的hash方法
hash方法是用来在一个元素加入map时,确定其位置时使用的方法
// JDK1.8:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
如果传入的对象是空,那么直接返回0。否则进行以下计算:
获取对象的hashcode并和hashcode的算术右移十六位进行异或。这两步是进行了扰动计算,在put之前调用此方法,目的是为了将高十六位也加入到特征计算中,防止在hash位置时只有低位的特征,尽可能的减少哈希冲突的概率,同时采用异或是为了尽可能的保证高十六位的特性,避免像与和或运算那样将计算结果靠拢0,1。
HashMap的底层实现
JDK1.7之前是使用拉链法,即数组加链表解决哈希冲突,每当新插入的元素和旧的元素发生哈希冲突时,就插入到对应链表中。
JDK1.8后,在链表插入时,如果个数大于8个元素,会将链表转化为红黑树结构(中间会有一次判断,如果数组的长度小于64,那么会先选择扩容,而不是转换),减少搜索时间。treeifyBin是将链表转换为红黑树的方法 。
HashMap扩容
默认容量16,负载因子0.75,扩容两倍
扩容条件:当HashMap中的元素个数(size)超过临界值(threshold)时,HashMap会自动进行扩容。临界值的计算公式为:
threshold = loadFactor * capacity,其中loadFactor是负载因子,默认值为0.75,capacity是当前HashMap的容量。扩容过程:当达到扩容条件时,HashMap会将容量扩大一倍(即
newCapacity = oldCapacity * 2),然后重新计算每个元素在新数组中的位置。这个过程称为rehash。rehash的巧妙之处:由于每次扩容都是翻倍,与原来计算的
(n-1) & hash的结果相比,只是多了一个bit位。因此,节点要么保持在原来的位置,要么被分配到“原位置 + 旧容量”这个位置。例如,当容量从16扩展到32时,节点的位置要么不变,要么移动到原位置加16的位置。性能影响:扩容是一个耗时的操作,因为它需要重新计算所有元素的hash值并重新分配位置。因此,在编写程序时,应尽量避免频繁的扩容操作。如果能够预知HashMap中元素的个数,可以通过设置初始容量来减少扩容次数,从而提高性能。
总结来说,HashMap的扩容机制是通过翻倍容量并重新分配元素位置来实现的,虽然这个过程会影响性能,但通过合理的初始容量设置可以减少扩容次数。
HashMap的时间复杂度
若无碰撞,则为O(1),若碰撞且为链表则为O(n),若碰撞且为红黑树则为O(logn)
JVM
Java内存区域
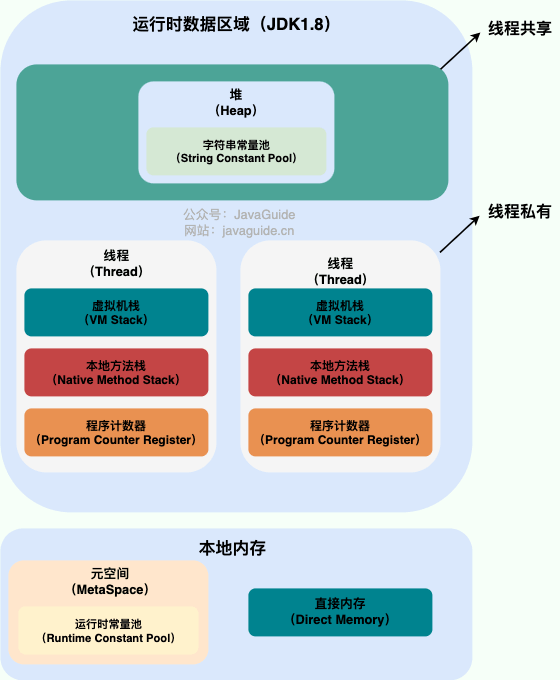
描述一下Java内存区域
运行时数据区:由JVM管理
- 堆:存放对象实例。
- 虚拟机栈:栈由一个个栈帧组成,而每个栈帧中都拥有:局部变量表、操作数栈、动态链接、方法返回地址
- 程序计数器:字节码解释器工作时通过改变这个计数器的值来选取下一条需要执行的字节码指令,分支、循环、跳转、异常处理、线程恢复等功能都需要依赖这个计数器来完成。
- 本地方法栈
- 字符串常量池:存放String,避免重复创建字符串对象。
本地内存:由OS管理
- 直接内存
- 元空间:元空间里面存放的是类的元数据,这样加载多少类的元数据就不由
MaxPermSize控制了, 而由系统的实际可用空间来控制,这样能加载的类就更多了。 - 运行时常量池:存放各种字面量和符号引用。
可能发生哪些异常
堆:OutOfMemoryError
直接内存:OutOfMemoryError
栈:OutOfMemoryError,StackOverFlowError
什么是符号引用和直接引用
符号引用即是适用一些无歧义的符号来描述被引用的目标:包括类符号引用、字段符号引用、方法符号引用、接口方法符号。
直接引用适用和内存布局相关,可以是直接指向目标的指针,也可以是偏移地址。
在类加载的解析阶段,由符号引用转换为直接引用。
JDK 1.7 为什么要将字符串常量池移动到堆中?
主要是因为永久代(方法区实现)的 GC 回收效率太低,只有在整堆收集 (Full GC)的时候才会被执行 GC。Java 程序中通常会有大量的被创建的字符串等待回收,将字符串常量池放到堆中,能够更高效及时地回收字符串内存。
对象的创建过程
类加载机制。
分配内存:
- 指针碰撞:适用于内存边界规整的情况,维护边界指针分配。
- 空闲列表:记录可用内存块,CMS
分配内存可能会出现并发问题,采用CAS+重试的机制。
初始化零值。
设置对象头信息。
执行init方法。
对象的内存布局
- 对象头
- 标记字段:hashcode,GC 年龄,锁状态,偏向线程
- 类型指针:指向类元数据。
- 实例数据:各个类型的字段内容。
- 填充数据:对齐8个字节。
类加载
类加载流程
- 加载:
- 通过全类名获取类的二进制字节流。
- 将二进制字节流转换为方法区的数据结构。
- 创建一个Class对象。
- 验证:用于验证其是否符合Java规范,继承的父类是否重写了方法,访问的方法是否存在,是否继承了不能继承的类(final)。
- 准备:为字段分配内存以及设置零值。
- 解析:将符号引用替换为直接引用。
- 初始化:对
static{}执行。
类加载器
类加载器是一个负责加载类的对象。ClassLoader 是一个抽象类。给定类的二进制名称,类加载器应尝试定位或生成构成类定义的数据。典型的策略是将名称转换为文件名,然后从文件系统中读取该名称的“类文件”。
每个 Java 类都有一个引用指向加载它的 ClassLoader。
BootstrapClassLoader(启动类加载器):最顶层的加载类,由 C++实现,通常表示为 null,并且没有父级,主要用来加载 JDK 内部的核心类库( %JAVA_HOME%/lib目录下的 rt.jar、resources.jar、charsets.jar等 jar 包和类)以及被 -Xbootclasspath参数指定的路径下的所有类。
ExtensionClassLoader(扩展类加载器):主要负责加载 %JRE_HOME%/lib/ext 目录下的 jar 包和类以及被 java.ext.dirs 系统变量所指定的路径下的所有类。
AppClassLoader(应用程序类加载器):面向我们用户的加载器,负责加载当前应用 classpath 下的所有 jar 包和类。
自定义类加载器
可以对我们的class文件加密,自定义类加载器进行解密。
- 重写findClass
- 重写loadClass
双亲委派模型
每当当前的类加载器试图加载类时,会先尝试交由父加载器加载,若父加载器加载失败,则调用自己的findClass方法。这样保证了核心类不会被错误加载,保证了不会重复加载。
打破双亲委派:类是否相同是由全类名和类加载器共同决定的,打破后可做到类的隔离。
垃圾回收
如何判断是否是垃圾
对象:
- 引用计数法:在对象中加入计数器,记录被引用的次数,若为0,则为垃圾。缺点:循环依赖,空间损耗。
- 可达性分析法:通过一系列的称为 “GC Roots” 的对象作为起点,从这些节点开始向下搜索,节点所走过的路径称为引用链,当一个对象到 GC Roots 没有任何引用链相连的话,则证明此对象是不可用的,需要被回收。
GC ROOT: 一组活跃的引用。
- 虚拟机栈中的引用(方法的参数、局部变量等)
- 本地方法栈中 JNI 的引用
- 类静态变量
- 运行时常量池中的常量(String 或 Class 类型)
具体到分两代的分代式GC来说,如果第0代叫做young gen,第1代叫做old gen,那么如果有minor GC/ young GC只收集young gen里的垃圾,则young gen属于“收集部分”,而old gen属于“非收集部分”,那么从old gen指向young gen的引用就必须作为minor GC / young GC的GC roots的一部分。
https://www.zhihu.com/question/53613423/answer/135743258
类,同时满足:
该类所有的实例都已经被回收,也就是 Java 堆中不存在该类的任何实例。
加载该类的
ClassLoader已经被回收。该类对应的
java.lang.Class对象没有在任何地方被引用,无法在任何地方通过反射访问该类的方法。
垃圾收集算法
标记清除
先通过引用计数或者可达性分析法进行标记可达对象,然后再进行垃圾回收。
效率低,会产生内存碎片。
标记整理
先通过引用计数或者可达性分析法进行标记可达对象,然后将存活的对象整理到一起,将剩下的内存回收。
复制算法
将内存区域分成两部分,其中只有一半的区域可用,每次GC时,将存活的对象全部复制到另一半,然后垃圾回收。
JVM分代GC
由于大部分的对象的生命周期都很短,刚创建出来就会变成垃圾(栈上的引用),所以JVM采用分代GC的做法。将对象分为新生代和老年代,并对两种对象采用不同的垃圾收集算法。
在新生代中,每次收集都会有大量对象死去,所以可以选择“复制”算法,只需要付出少量对象的复制成本就可以完成每次垃圾收集。而老年代的对象存活几率是比较高的,而且没有额外的空间对它进行分配担保,所以我们必须选择“标记-清除”或“标记-整理”算法进行垃圾收集。
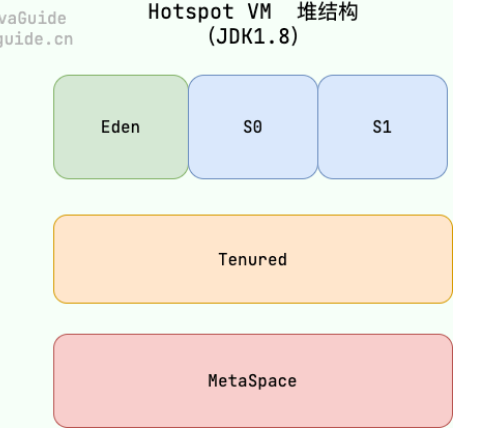
大多数情况下,对象在新生代中 Eden 区分配。当 Eden 区没有足够空间进行分配时,虚拟机将发起一次 Minor GC。如果对象在 Eden 出生并经过第一次 Minor GC 后仍然能够存活,并且能被 Survivor 容纳的话,将被移动到 Survivor 空间(s0 或者 s1)中,并将对象年龄设为 1(Eden 区->Survivor 区后对象的初始年龄变为 1)。
对象在 Survivor 中每熬过一次 MinorGC,年龄就增加 1 岁,当它的年龄增加到一定程度(默认为 15 岁),就会被晋升到老年代中。对象晋升到老年代的年龄阈值,可以通过参数 -XX:MaxTenuringThreshold 来设置。
针对 HotSpot VM 的实现,它里面的 GC 其实准确分类只有两大种:
部分收集 (Partial GC):
- 新生代收集(Minor GC / Young GC):只对新生代进行垃圾收集;
- 老年代收集(Major GC / Old GC):只对老年代进行垃圾收集。需要注意的是 Major GC 在有的语境中也用于指代整堆收集;
整堆收集 (Full GC):收集整个 Java 堆和方法区(也就是元空间)。
为什么要两个S区
如果只有一个S区,在经历一次minor GC并过一段时间后,两个区域都是处于有存活对象的状态,这时Eden区满了,进行minor GC,两个区域都是有碎片的,复制后仍然有碎片。
新生代何时变为老年代
- 在经历16次minor GC后,升级为老年代。
- 大对象直接进入老年代。
空间分配担保
在发生Minor GC之前,虚拟机会检查老年代最大可用的连续空间是否大于新生代所有对象的总空间。
如果大于,则此次Minor GC是安全的
如果小于,则虚拟机会查看HandlePromotionFailure设置值是否允许担保失败。如果HandlePromotionFailure=true,那么会继续检查老年代最大可用连续空间是否大于历次晋升到老年代的对象的平均大小,如果大于,则尝试进行一次Minor GC,但这次Minor GC依然是有风险的;如果小于或者HandlePromotionFailure=false,则改为进行一次Full GC。
因为新生代采用复制收集算法,假如大量对象在Minor GC后仍然存活(最极端情况为内存回收后新生代中所有对象均存活),而Survivor空间是比较小的,这时就需要老年代进行分配担保,把Survivor无法容纳的对象放到老年代。老年代要进行空间分配担保,前提是老年代得有足够空间来容纳这些对象,但一共有多少对象在内存回收后存活下来是不可预知的,因此只好取之前每次垃圾回收后晋升到老年代的对象大小的平均值作为参考。使用这个平均值与老年代剩余空间进行比较,来决定是否进行Full GC来让老年代腾出更多空间。
垃圾收集器
- JDK 8: Parallel Scavenge(新生代)+ Parallel Old(老年代)
- JDK 9 ~ JDK22: G1
Parallel Scavenge+ Parallel Old
并发进行GC,关注吞吐量,但是有STW。
新生代使用复制,老年代使用标记整理。
cms
以获取最短回收停顿时间为目标,采用“标记-清除”算法,分 4 大步进行垃圾收集,其中初始标记和重新标记会 STW。
初始标记: 短暂停顿,标记直接与 root 相连的对象(根对象);
并发标记: 同时开启 GC 和用户线程,用一个闭包结构去记录可达对象。但在这个阶段结束,这个闭包结构并不能保证包含当前所有的可达对象。因为用户线程可能会不断的更新引用域,所以 GC 线程无法保证可达性分析的实时性。所以这个算法里会跟踪记录这些发生引用更新的地方。
重新标记: 重新标记阶段就是为了修正并发标记期间因为用户程序继续运行而导致标记产生变动的那一部分对象的标记记录,这个阶段的停顿时间一般会比初始标记阶段的时间稍长,远远比并发标记阶段时间短
并发清除: 开启用户线程,同时 GC 线程开始对未标记的区域做清扫。
缺点:
- 对 CPU 资源敏感;
- 无法处理浮动垃圾;
- 它使用的回收算法-“标记-清除”算法会导致收集结束时会有大量空间碎片产生。
G1
采用标记整理,分区域增量回收。
- 分代:它将堆内存分为多个大小相等的区域(Region),每个区域都可以是 Eden 区、Survivor 区或者 Old 区。
- 增量:G1 可以以增量方式执行垃圾回收,这意味着它不需要一次性回收整个堆空间,而是可以逐步、增量地清理。有助于控制停顿时间,尤其是在处理大型堆时。
- 并行:G1 垃圾回收器可以并行回收垃圾,这意味着它可以利用多个 CPU 来加速垃圾回收的速度,这一特性在年轻代的垃圾回收(Minor GC)中特别明显,因为年轻代的回收通常涉及较多的对象和较高的回收速率。
- 标记整理:在进行老年代的垃圾回收时,G1 使用标记-整理算法。这个过程分为两个阶段:标记存活的对象和整理(压缩)堆空间。通过整理,G1 能够避免内存碎片化,提高内存利用率。
当 Eden 区的内存空间无法支持新对象的内存分配时,G1 会触发 Young GC。当大对象过多时,G1 会触发一次 concurrent marking,计算老年代中有多少空间需要被回收,当达到阈值时,在下次 Young GC 后会触发一次 Mixed GC。
Mixed GC 是指回收年轻代的 Region 以及一部分老年代中的 Region。Mixed GC 和 Young GC 一样,采用的也是复制算法。
在 Mixed GC 过程中,如果发现老年代空间还是不足,此时如果 G1HeapWastePercent 设定过低,可能引发 Full GC。
JVM常见参数
-Xms:1G; // 初始堆大小
-Xmx:2G; // 最大堆大小
-Xmn:500M;// 新生代大小 s + s0 + s1
-XX:+UseConcMarkSweepGC;// 适用cms GC
-XX:SurvivorRatio=3;// s的占比 -> s : s0 : s1 = 3: 1 : 1
-XX:NewRatio=1 // 老年代与新生代内存的比值为 1
-XX:+UseSerialGC
-XX:+UseParallelGC
-XX:+UseConcMarkSweepGC
-XX:+UseG1GC
JUC
线程池
为什么使用线程池
降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行。
提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
线程池参数
ThreadPoolExecutor 3 个最重要的参数:
corePoolSize: 任务队列未达到队列容量时,最大可以同时运行的线程数量。maximumPoolSize: 任务队列中存放的任务达到队列容量的时候,当前可以同时运行的线程数量变为最大线程数。workQueue: 新任务来的时候会先判断当前运行的线程数量是否达到核心线程数,如果达到的话,新任务就会被存放在队列中。
ThreadPoolExecutor其他常见参数 :
keepAliveTime:当线程池中的线程数量大于corePoolSize,即有非核心线程(线程池中核心线程以外的线程)时,这些非核心线程空闲后不会立即销毁,而是会等待,直到等待的时间超过了keepAliveTime才会被回收销毁。unit:keepAliveTime参数的时间单位。threadFactory:executor 创建新线程的时候会用到的工厂模式。handler:拒绝策略
注意一点,当队列满时,队头为B,如果新来一个任务A,会创建非核心线程执行A,而非B。从这可以看出,先提交的任务不一定先执行。
拒绝策略
ThreadPoolExecutor.AbortPolicy:抛出RejectedExecutionException来拒绝新任务的处理。ThreadPoolExecutor.CallerRunsPolicy:调用执行者自己的线程运行任务,也就是直接在调用execute方法的线程中运行(run)被拒绝的任务,如果执行程序已关闭,则会丢弃该任务。因此这种策略会降低对于新任务提交速度,影响程序的整体性能。如果你的应用程序可以承受此延迟并且你要求任何一个任务请求都要被执行的话,你可以选择这个策略。ThreadPoolExecutor.DiscardPolicy:不处理新任务,直接丢弃掉。ThreadPoolExecutor.DiscardOldestPolicy:此策略将丢弃最早的未处理的任务请求。
并发编程三个问题
- 原子性:一次操作或者多次操作,要么所有的操作全部都得到执行并且不会受到任何因素的干扰而中断,要么都不执行。
- 可见性:当一个线程对共享变量进行了修改,那么另外的线程都是立即可以看到修改后的最新值。
- 有序性:保证指令按序执行,不进行指令重排。
volatile
保证了可见性(每次都从内存中读取,插入内存屏障),有序性(禁止指令重排序)。
读/写内存屏障,保证屏障之前的读/写操作对之后的指令是可见的。
ThreadLocal
synchronized
偏向锁:大多数情况是一个线程自己竞争,故只需在锁的markword记录线程id,如果发现锁的markword不是自己的线程id,锁升级为轻量级锁。
轻量级锁:使用cas把栈帧中的锁记录交换到锁的markword中,通过自旋等待,多次自旋后升级为重量级锁。
重量级锁:在锁的monitor对象中发现锁已被占用,加入阻塞队列,陷入阻塞态,等待唤醒。
CAS
乐观锁的实现方式之一(另一个是版本号):
@HotSpotIntrinsicCandidate
public final int getAndAddInt(Object o, long offset, int delta) {
int v;
do {
v = getIntVolatile(o, offset);
} while (!weakCompareAndSetInt(o, offset, v, v + delta));
return v;
}
// 每次的v都是用volatile获取到最新的值
// o 是要操作的对象,offset是字段偏移量,v是预期原来的值,v+delta是更新后的值
// 如果更新失败就不断的更新
存在ABA问题,在变量前面追加上版本号或者时间戳,首先检查当前引用是否等于预期引用,并且检查当前标志是否等于预期标志,如果二者都相等,才使用 CAS 设置为新的值和标志。
AQS
抽象队列同步器,用state表示锁的状态,采用虚拟队列CLH记录阻塞队列,子类若需使用需要重写相应方法:
import java.util.concurrent.locks.AbstractQueuedSynchronizer;
public class Mutex {
private static class Sync extends AbstractQueuedSynchronizer {
@Override
protected boolean tryAcquire(int arg) {
if (compareAndSetState(0, 1)) {
setExclusiveOwnerThread(Thread.currentThread());
return true;
}
return false;
}
@Override
protected boolean tryRelease(int arg) {
if (getState() == 0) {
throw new IllegalMonitorStateException();
}
setExclusiveOwnerThread(null);
setState(0);
return true;
}
@Override
protected boolean isHeldExclusively() {
return getState() == 1;
}
}
private final Sync sync = new Sync();
public void lock() {
sync.acquire(1);
}
public void unlock() {
sync.release(1);
}
public boolean isLocked() {
return sync.isHeldExclusively();
}
}
concurrentHashMap
Java7 中 ConcurrentHashMap 使用的分段锁,也就是每一个 Segment 上同时只有一个线程可以操作,每一个 Segment 都是一个类似 HashMap 数组的结构,它可以扩容,它的冲突会转化为链表。但是 Segment 的个数一但初始化就不能改变。
Java8 中的 ConcurrentHashMap 使用的 Synchronized 锁加 CAS 的机制。结构也由 Java7 中的 Segment 数组 + HashEntry 数组 + 链表 进化成了 Node 数组 + 链表 / 红黑树,Node 是类似于一个 HashEntry 的结构。它的冲突再达到一定大小时会转化成红黑树,在冲突小于一定数量时又退回链表。
并发编程题
双重判定锁
public class Singleton {
// 解释四:volatile 保证了在 uniqueInstance = new Singleton();
// 1: 分配空间 2: 初始化 3: 将引用指向内存
// 乱序执行: 1 3 2 时
// 避免并发执行的线程B在线程A只执行到3时就返回引用,导致空指针。
private volatile static Singleton uniqueInstance;
// 防止被初始化
private Singleton() {
}
public static Singleton getUniqueInstance() {
// 解释一:先判断对象是否已经实例过,没有实例化过才进入加锁代码
if (uniqueInstance == null) {
//解释二:类对象加锁
synchronized (Singleton.class) {
// 解释三:双重判定
if (uniqueInstance == null) {
uniqueInstance = new Singleton();
}
}
}
return uniqueInstance;
}
}
两个线程交替打印0-100
// 使用 reentrantLock
public class Test {
private static volatile int i = 1;
private static final ReentrantLock lock = new ReentrantLock();
public static void main(String[] args) {
Thread t1 = new Thread(() -> {
while(i < 100) {
lock.lock();
try {
if (i % 2 != 0) System.out.println(Thread.currentThread().getName() + ":" +i++);
} catch (Exception e) {
e.printStackTrace();
throw e;
} finally {
lock.unlock();
}
}
});
Thread t2 = new Thread(() -> {
while(i < 100) {
lock.lock();
try {
if (i % 2 == 0) System.out.println(Thread.currentThread().getName() + ":" +i++);
} catch (Exception e) {
e.printStackTrace();
throw e;
} finally {
lock.unlock();
}
}
});
t1.start();
t2.start();
}
}
// 使用synchronized
public class Test {
private static volatile int i = 1;
private static final Object lock = new Object();
public static void main(String[] args) {
Thread t1 = new Thread(() -> {
while(i < 100) {
synchronized (lock) {
System.out.println(Thread.currentThread().getName() + ":" +i++);
try {
lock.notifyAll();
lock.wait();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
});
Thread t2 = new Thread(() -> {
while(i < 100) {
synchronized (lock) {
System.out.println(Thread.currentThread().getName() + ":" +i++);
try {
lock.notifyAll();
lock.wait();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
});
t1.start();
t2.start();
}
}
三个线程交替打印自己名字
public class Test {
private static final ReentrantLock lock = new ReentrantLock();
private static final Condition c1 = lock.newCondition();
private static final Condition c2 = lock.newCondition();
private static final Condition c3 = lock.newCondition();
public static void main(String[] args) {
Thread t1 = new Thread(() -> {
int i = 0;
while(i < 5) {
lock.lock();
try {
System.out.println(Thread.currentThread().getName());
c2.signal();
c1.await();
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
lock.unlock();
}
i ++;
}
},"A");
Thread t2 = new Thread(() -> {
int i = 0;
while(i < 5) {
lock.lock();
try {
System.out.println(Thread.currentThread().getName());
c3.signal();
c2.await();
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
lock.unlock();
}
i ++;
}
},"B");
Thread t3 = new Thread(() -> {
int i = 0;
while(i < 5) {
lock.lock();
try {
System.out.println(Thread.currentThread().getName());
c1.signal();
c3.await();
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
lock.unlock();
}
i ++;
}
},"C");
t1.start();
t2.start();
t3.start();
}
}
编写10个线程,第一个线程从1加到10,第二个线程从11加20…第十个线程从91加到100,最后再把10个线程结果相加。
public class Test {
private static final int THREAD_COUNT = 10;
private static final int[] results = new int[THREAD_COUNT];
public static void main(String[] args) throws InterruptedException {
Thread[] threads = new Thread[THREAD_COUNT];
for (int i = 0; i < THREAD_COUNT; i++) {
final int threadIndex = i;
threads[i] = new Thread(() -> {
int start = threadIndex * 10 + 1;
int end = (threadIndex + 1) * 10;
results[threadIndex] = calculateRangeSum(start, end);
});
threads[i].start();
}
for (Thread t : threads) t.join();
int total = 0;
for (int sum : results) total += sum;
System.out.println("总和结果:" + total);
}
private static int calculateRangeSum(int start, int end) {
int sum = 0;
for (int i = start; i <= end; i++) sum += i;
return sum;
}
}
Spring
IOC
IOC容器,里面存放着要使用的bean,同时我们还可能需要一些高级功能,比如bean的处理器,事件发布相关的的,所以一个高级的IOC容器中,应该将低级容器抽取出来,依赖于低级容器,而高级IOC容器只需要关心高级功能,同时可以随时更换低级容器。
IOC容器的初始化步骤
Spring详解(五)——Spring IOC容器的初始化过程
在ApplicationContext这些高级容器中,实际上是依赖于底层容器(BeanFactory)做Bean的装载。而高级容器实现了一些拓展功能,例如接口回调,监听器,自动实例化单例,发布事件等。
所以IOC容器初始化大致分为两个步骤:
- 低级容器加载配置文件(从 XML,数据库,Applet),并解析成 BeanDefinition 到低级容器中。
- 加载成功后,高级容器启动高级功能,例如接口回调,监听器,自动实例化单例,发布事件等等功能。
以ClassPathXmlApplicationContext的初始化为例,它会调用AbstractApplicationContext中的refresh方法,这个是IOC容器最核心的代码,包含了上面的两个步骤。
refresh方法首先通过obtainFreshBeanFactory获取到一个Bean工厂(低级容器),实现了对底层容器的刷新。如果当前已经存在了容器,它会将旧容器删除,重新创建新容器。然后重新执行对Resource的定位,Bean的载入以及注册。然后调用prepareBeanFactory对工厂进行属性填充。
之后就是一些扩展接口和高级功能,依次包括
- postProcessBeanFactory:SPI
- invokeBeanFactoryPostProcessors:调用工厂后置处理器
- registerBeanPostProcessors:注册bean后置处理器
- initMessageSource:初始化国际化资源
- initApplicationEventMulticaster:初始化事件派发器
- onRefresh:SPI,可以自定义逻辑,spring boot在这里启动了Tomcat
- registerListeners:注册所有应用监听器,所有实现了ApplicationListener的bean
- finishBeanFactoryInitialization:初始化所有懒加载的bean
Bean
生命周期
实例化、属性赋值、初始化、销毁
带你彻底掌握Bean的生命周期 - 知乎 (zhihu.com)
java - Spring Bean生命周期详解 - Spring注解全面解析 - SegmentFault 思否
SpringBoot和Spring区别
spb是对sp的拓展,首先是消除了XML配置,将常见的依赖进行整合。提供了自动装配机制。将应用服务器内嵌入应用中,只需要打jar包即可运行服务。
Spring循环依赖
MySQL
存储过程&存储函数
存储过程是事先编好的、存储在数据库中的一组被编译了的SQL命令集合,这些命令用来完成对数据库的指定操作。
- 在第一次运行时只编译一次。
- 可重复性。
存储过程和存储函数的区别:
- 函数可以嵌入在SQL查询中,作为表达式的一部分调用。例如,
SELECT func_name(参数) FROM table。 - 存储过程需通过
CALL或EXECUTE语句独立执行,不能直接嵌套在查询中。例如,MySQL中使用CALL proc_name(参数)调用存储过程。 - 存储过程允许执行数据修改操作(如INSERT、UPDATE、DELETE),支持事务控制,适用于复杂业务逻辑。例如,存储过程可更新员工工资并提交事务。
- 函数通常为只读操作,不能直接修改数据库状态。但某些数据库(如PostgreSQL)允许函数包含DML语句
禁止使用存储过程,存储过程难以调试和扩展,更没有移植性。
innodb特点
- 事务
- 外键
- 行级锁
执行一条select语句发生了什么(MySQL的架构)
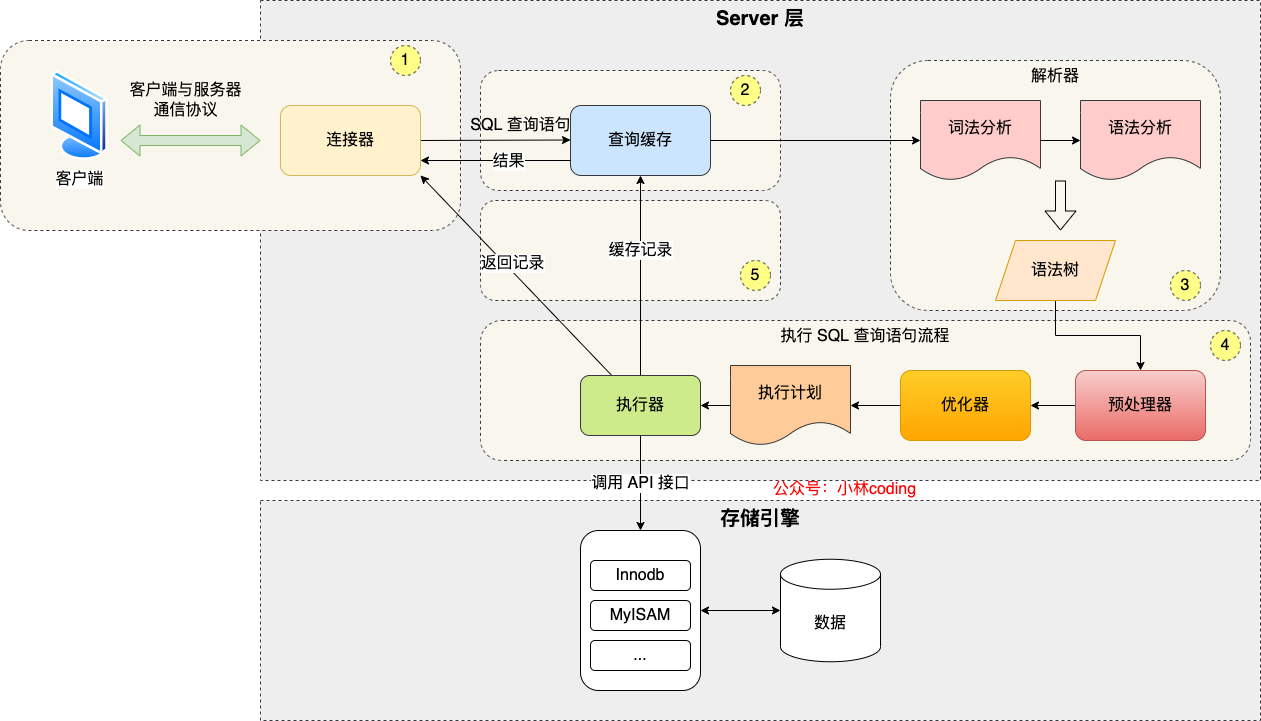
分为Server层和存储引擎层
- 连接器:负责和客户端连接,基于TCP/IP实现了自己的通信协议。有长短协议之分
- 缓存器:以K-V形式存储(SQL-Value),但是只要有一个修改操作就需要清空这个表的缓存,于8.0删除。
- 解析器:进行词法分析将SQL转化为一组Token,找出关键字分出类型。然后进行语法分析,根据Token构建AST抽象语法树,如果语法有问题,在这里就会报错。
- 预处理器:首先进行预处理,判断表和字段是否存在。
- 优化器:然后进行优化,负责将SQL查询的执行方案确定下来,比如使用什么索引。生成一个执行计划。
- 执行器:假设全盘扫描,Server会调用引擎的read_first_record全扫描函数,让存储引擎读取表中的第一条记录。执行器会判断读到的这条记录的是否满足where条件,如果不是则跳过;如果是则将记录发给客户的,客户端是等查询语句查询完成后,才会显示出所有的记录。不断的循环执行直到引擎层报告查询完毕。
SQL
create table tb_1(
id int primary key,
name varchar(32) unique,
age int not null,
key
)
update tb_1 set name='zy',age=age+1 ... where id = 1;
insert into tb_1 (name,age) values('zy',1);
delete from tb_1 where age = 1;
SELECT <字段名>
FROM <表名>
JOIN <表名>
ON <连接条件>
WHERE <筛选条件>
GROUP BY <字段名>
HAVING <筛选条件>
UNION
ORDER BY <字段名>
LIMIT <限制行数>;
select * from tb_1 where age BETWEEN 10 AND 30;
select * from tb_1 order by age DESC; # 降序
索引
索引的分类
- 从物理存储的角度,分为聚簇(主键)索引,非聚簇索引。
- 从字段特性的角度来看,索引分为主键索引、唯一索引、普通索引、前缀索引。
- 从字段个数的角度来看,索引分为单列索引、联合索引(复合索引)。
索引的结构
为什么使用B+树
谈起搜索树,首先会从二叉搜索树看起:通俗易懂讲解 二叉搜索树,但是二叉搜索树会有两个缺点:
- 当顺序插入时,二叉搜索树会退化为一个链表,搜索时间复杂度退化为
- 对于大量数据,树的层级加深,检索速度慢
为了解决这些缺点,这里引入了B-树(多路平衡查找树)。
B-树是专门为外部存储器设计的,具有磁盘友好性,它对于读取和写入大块数据有良好的性能,所以一般被用在文件系统及数据库中。
而B+树是B-树的变体,不同之处在于
- 所有关键字存储在叶子节点出现,内部节点(非叶子节点并不存储真正的 data),数据都集中在一个页中,减少了随机IO。同时非叶子节点扇出更多,树的高度降低,随机IO减少。
- 为所有叶子结点增加了一个链指针
同时为了增加区间访问性,一般会对B+树进行优化:将叶子节点的单项指针变为双向指针,也就是将单链表转化为了双向链表。
为什么不用AVL或红黑树?
AVL树和红黑树基本都是存储在内存中才会使用的数据结构。而数据库中的数据的索引会非常大,所以为了减少内存的占用,索引会被存储到磁盘文件中,此时影响数据库查询效率的主要因素就是磁盘的IO次数。AVL树和红黑树由于一个父节点只能存储两个子节点。所以使用AVL树或红黑树存储大规模数据时,树的深度就会很深,此时磁盘的IO次数也会大幅度增加。B+树中一个父节点有多个子节点,减少了树的深度,磁盘IO次数也相应的减少。
MySQL的索引是由B+树构成的
B+Tree 是一种多叉树,叶子节点才存放数据,非叶子节点只存放索引,而且每个节点里的数据是按主键顺序存放的。每一层父节点的索引值都会出现在下层子节点的索引值中,因此在叶子节点中,包括了所有的索引值信息,并且每一个叶子节点都有两个指针,分别指向下一个叶子节点和上一个叶子节点,形成一个双向链表。
主键索引的 B+Tree 和二级索引的 B+Tree 区别
主键索引的 B+Tree 的叶子节点存放的是实际数据,所有完整的用户记录都存放在主键索引的 B+Tree 的叶子节点里; 二级索引的 B+Tree 的叶子节点存放的是主键值,而不是实际数据。
需要在耳机索引中找到对应的叶子节点,然后获取主键值,然后再通过主键索引中的 B+Tree 树查询到对应的叶子节点,然后获取整行数据。这个过程叫「回表」,也就是说要查两个 B+Tree 才能查到数据。
索引的优化
覆盖索引
目的:避免回表查询。
手段:在二级索引上构建覆盖select查询字段的索引,这是无需回到主键索引上查询。
最左匹配
在使用联合索引时,会按照最左优先的顺序进行索引的匹配。联合索引对于第一个索引是全局有序的,但是对后面的索引都是相对于上一个索引局部有序的,所以不按序的索引无法使用。
比如,如果创建了一个 (a, b, c) 联合索引,如果查询条件是以下这几种,就可以匹配上联合索引:
where a=1; where a=1 and b=2 and c=3; where a=1 and b=2;
需要注意的是,因为有查询优化器,所以 a 字段在 where 子句的顺序并不重要。
但是,如果查询条件是以下这几种,因为不符合最左匹配原则,所以就无法匹配上联合索引,联合索引就会失效:
where b=2; where c=3; where b=2 and c=3;
- select * from t_table where a > 1 and b = 2,联合索引(a, b)哪一个字段用到了联合索引的 B+Tree?
- select * from t_table where a >= 1 and b = 2,联合索引(a, b)哪一个字段用到了联合索引的 B+Tree?
- SELECT * FROM t_table WHERE a BETWEEN 2 AND 8 AND b = 2,联合索引(a, b)哪一个字段用到了联合索引的 B+Tree?
- SELECT * FROM t_user WHERE name like 'j%' and age = 22,联合索引(name, age)哪一个字段用到了联合索引的 B+Tree?
索引下推
select * from t_table where a > 1 and b = 2
MySQL 5.6 引入的索引下推优化(index condition pushdown), 可以在联合索引遍历过程中,对联合索引中包含的字段先做判断,直接过滤掉不满足条件的记录,减少回表次数。
在联合索引判断a>1后,会紧接着判断b是否等于2,而不需要回表判断。对于符合b=2的记录,最后再回表查询。
排序
经常用于 GROUP BY 和 ORDER BY 的字段,这样在查询的时候就不需要再去做一次排序了,因为我们都已经知道了建立索引之后在 B+Tree 中的记录都是排序好的。
不需要索引
- 字段区分度低。
- 经常更新。
- 表数据量较小。
索引失效
- 当我们使用左或者左右模糊匹配的时候,也就是 like %xx 或者 like %xx%这两种方式都会造成索引失效;
- 当我们在查询条件中对索引列做了计算、函数、类型转换操作,这些情况下都会造成索引失效;
- 联合索引要能正确使用需要遵循最左匹配原则,也就是按照最左优先的方式进行索引的匹配,否则就会导致索引失效。
- 在 WHERE 子句中,如果在 OR 前的条件列是索引列,而在 OR 后的条件列不是索引列,那么索引会失效。
锁
全局锁
加上全局锁后,数据库就进入只读的状态。
flush tables with read lock;
表级锁
对整个表加锁,表锁除了会限制别的线程的读写外,也会限制本线程接下来的读写操作,加锁后,本会话不能访问其他的表。
lock tables t_student read;
lock tables t_student write;
元数据锁
对一张表进行 CRUD 操作时,加的是 MDL 读锁; 对一张表做结构变更操作的时候,加的是 MDL 写锁;
保证当用户对表执行 CRUD 操作时,防止其他线程对这个表结构做了变更。
在事务提交后才会释放,这意味着事务执行期间,MDL 是一直持有的。
意向锁
在使用 InnoDB 引擎的表里对某些记录加上「共享锁」之前,需要先在表级别加上一个「意向共享锁」;
在使用 InnoDB 引擎的表里对某些纪录加上「独占锁」之前,需要先在表级别加上一个「意向独占锁」;
意向共享锁和意向独占锁是表级锁,不会和行级的共享锁和独占锁发生冲突,而且意向锁之间也不会发生冲突,只会和共享表锁(lock tables ... read)和独占表锁(lock tables ... write)发生冲突。意向锁的目的是为了快速判断表里是否有记录被加锁。
行级锁
// 当前读,无锁
select ...
// 对记录加共享锁
select ... lock in share mode;
// 对记录加独占锁
select ... for update;
//对操作的记录加独占锁(X型锁)
update table .... where id = 1;
//对操作的记录加独占锁(X型锁)
delete from table where id = 1;
行级锁又分为:
Record Lock,记录锁,也就是仅仅把一条记录锁上;
Gap Lock,间隙锁,锁定一个范围,但是不包含记录本身,用于防止插入造成的幻读;
Next-Key Lock:Record Lock + Gap Lock 的组合,锁定一个范围,并且锁定记录本身,前开后闭。
加锁原则,对于可能造成不一致的地方加锁,由Next-Key Lock -> Gap Lock -> Record Lock 退化。
事务
事务特性由什么保证
- 原子性:undo log
- 持久性:redo log
- 一致性:由其他三个组成。
- 隔离性:MVCC或锁
并行事务问题
如果一个事务「读到」了另一个「未提交事务修改过的数据」,就意味着发生了「脏读」现象。重点在修改。
在一个事务内多次读取同一个数据,如果出现前后两次读到的数据不一样的情况,读到了其他事务提交过的数据,就意味着发生了「不可重复读」现象。重点在修改。
在一个事务内多次查询某个符合查询条件的「记录数量」,如果出现前后两次查询到的记录数量不一样的情况,就意味着发生了「幻读」现象。重点在插入。
隔离级别
- 读未提交(read uncommitted),指一个事务还没提交时,它做的变更就能被其他事务看到;
- 读提交(read committed),指一个事务提交之后,它做的变更才能被其他事务看到;
- 可重复读(repeatable read),指一个事务执行过程中看到的数据,一直跟这个事务启动时看到的数据是一致的,MySQL InnoDB 引擎的默认隔离级别;
- 串行化(serializable ),会对记录加上读写锁,在多个事务对这条记录进行读写操作时,如果发生了读写冲突的时候,后访问的事务必须等前一个事务执行完成,才能继续执行;
MVCC
通过MVCC来实现当前读的读提交和可重复读的隔离,实现了无锁并发。
具体是通过 Read View 来实现的,它们的区别在于创建 Read View 的时机不同,可以把 Read View 理解成一个数据快照,就像相机拍照那样,定格某一时刻的风景。
「读提交」隔离级别是在「每个语句执行前」都会重新生成一个 Read View。
「可重复读」隔离级别是「启动事务时」生成一个 Read View,然后整个事务期间都在用这个 Read View。
ReadView格式:
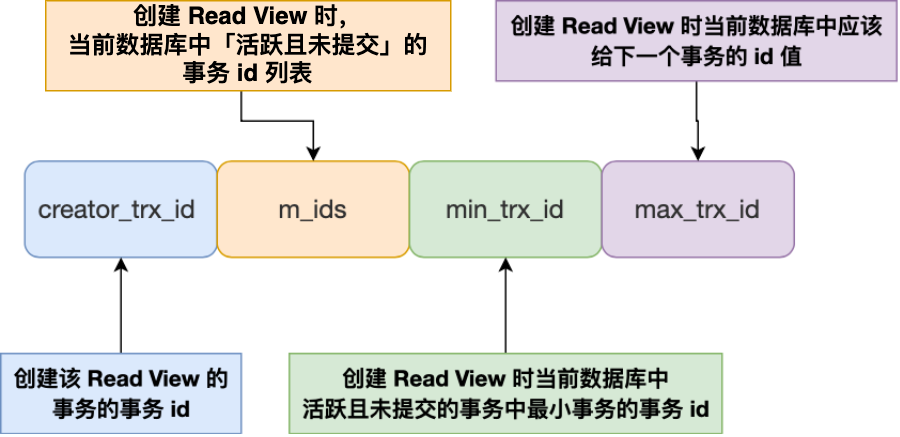
这里还需要引入两个位于聚簇索引的隐藏列:
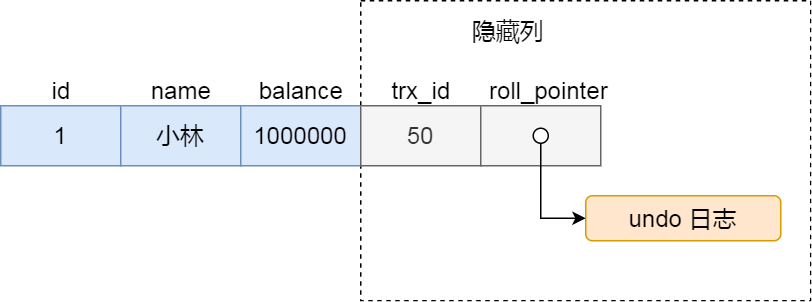
trx_id,当一个事务对某条聚簇索引记录进行改动时,就会把该事务的事务 id 记录在 trx_id 隐藏列里;
roll_pointer,每次对某条聚簇索引记录进行改动时,都会把旧版本的记录写入到 undo 日志中,然后这个隐藏列是个指针,指向每一个旧版本记录,于是就可以通过它找到修改前的记录。
每当要访问记录时,我们都需要使用记录中的trx_id和当前的readview比较来确定那个版本对我们是可见的,具体如下:
一个事务去访问记录的时候,除了自己的更新记录总是可见之外,还有这几种情况:
- 如果记录的 trx_id 值小于 Read View 中的 min_trx_id 值,表示这个版本的记录是在创建 Read View 前已经提交的事务生成的,所以该版本的记录对当前事务可见。
- 如果记录的 trx_id 值大于等于 Read View 中的 max_trx_id 值,表示这个版本的记录是在创建 Read View 后才启动的事务生成的,所以该版本的记录对当前事务不可见。
- 如果记录的 trx_id 值在 Read View 的 min_trx_id 和 max_trx_id 之间,需要判断 trx_id 是否在 m_ids 列表中:
- 如果记录的 trx_id 在 m_ids 列表中,表示生成该版本记录的活跃事务依然活跃着(还没提交事务),所以该版本的记录对当前事务不可见。
- 如果记录的 trx_id 不在 m_ids列表中,表示生成该版本记录的活跃事务已经被提交,所以该版本的记录对当前事务可见。
日志
undo log
undo log用于保证原子性,每当进行一次增删改操作时,都会记录undo log,同时实现了MVCC。
- 在插入一条记录时,要把这条记录的主键值记下来,这样之后回滚时只需要把这个主键值对应的记录删掉就好了;
- 在删除一条记录时,要把这条记录中的内容都记下来,这样之后回滚时再把由这些内容组成的记录插入到表中就好了;
- 在更新一条记录时,要把被更新的列的旧值记下来,这样之后回滚时再把这些列更新为旧值就好了。
Buffer Pool
有了 Buffer Poo 后:
- 当读取数据时,如果数据存在于 Buffer Pool 中,客户端就会直接读取 Buffer Pool 中的数据,否则再去磁盘中读取。
- 当修改数据时,如果数据存在于 Buffer Pool 中,那直接修改 Buffer Pool 中数据所在的页,然后将其页设置为脏页(该页的内存数据和磁盘上的数据已经不一致),为了减少磁盘I/O,不会立即将脏页写入磁盘,后续由后台线程选择一个合适的时机将脏页写入到磁盘。
Buffer Pool 缓存什么?

每次查询一行记录,会把整个数据页加载入Buffer Pool。
redo log
redo log用于当修改一个记录时,更新Buffer Poll,记录脏页的同时写入redo log,保证持久性。如果掉电可以根据redolog重新执行一边。后续,InnoDB 引擎会在适当的时候,由后台线程将缓存在 Buffer Pool 的脏页刷新到磁盘里。
这种技术被称为WAL(Write-Ahead Logging)技术,WAL 技术指的是, MySQL 的写操作并不是立刻写到磁盘上,而是先写日志,然后在合适的时间再写到磁盘上。
写入 redo log 的方式使用了追加操作, 所以磁盘操作是顺序写,而写入数据需要先找到写入位置,然后才写到磁盘,所以磁盘操作是随机写。 磁盘的「顺序写 」比「随机写」 高效的多,因此 redo log 写入磁盘的开销更小。
同时,redo log有自己的redo log buffer,我们需要控制其刷盘时机。
redo log是有时效的,对于已经脏页已经刷盘的redo log,我们无需保留,所以将两个redo log构成了一个环形区域,如果写满了,MySQL就会被阻塞。
bin log
前面介绍的 undo log 和 redo log 这两个日志都是 Innodb 存储引擎生成的。
MySQL 在完成一条更新操作后,Server 层还会生成一条 binlog,等之后事务提交的时候,会将该事物执行过程中产生的所有 binlog 统一写 入 binlog 文件。
binlog 文件是记录了所有数据库表结构变更和表数据修改的日志,不会记录查询类的操作,比如 SELECT 和 SHOW 操作。
bin log格式:
- STATEMENT:每一条修改数据的 SQL 都会被记录到 binlog 中,会变的函数可能导致不一致。
- ROW:记录行数据最终被修改成什么样了。
- MIXED:在合适的地方自动选择。
bin log和redo log的区别:
- 适用对象不同: binlog 是 MySQL 的 Server 层实现的日志,所有存储引擎都可以使用; redo log 是 Innodb 存储引擎实现的日志;
- 写入方式不同: binlog 是追加写,写满一个文件,就创建一个新的文件继续写,不会覆盖以前的日志,保存的是全量的日志。 redo log 是循环写,日志空间大小是固定,全部写满就从头开始,保存未被刷入磁盘的脏页日志。
- 用途不同: binlog 用于备份恢复、主从复制; redo log 用于掉电等故障恢复。
Redis
数据类型
String
redis的string是由SDS构成的,和C语言的区别:
- 可以存放二进制数据
- 获取长度O(1)
- API安全,不会发生缓冲区溢出
SET key value NX PX 10000
# 设置 key-value 如果不存在,并设置过期时间为10000ms
List Set Hash
Zset
Zset 类型(有序集合类型)相比于 Set 类型多了一个排序属性 score(分值),对于有序集合 ZSet 来说,每个存储元素相当于有两个值组成的,一个是有序集合的元素值,一个是排序值。 有序集合保留了集合不能有重复成员的特性(分值可以重复),但不同的是,有序集合中的元素可以排序。
跳表
跳表是在链表的基础上修改变为多层有序链表的,多层指的是链表节点的forward指针有多个,在源代码中表现为level[],如果是level[2]则是第二层的forward指针。下面是跳表的查找过程。

如果要查找「元素:abcd,权重:4」的节点,查找的过程是这样的:
- 先从头节点的最高层开始,L2 指向了「元素:abc,权重:3」节点,这个节点的权重比要查找节点的小,所以要访问该层上的下一个节点;
- 但是该层的下一个节点是空节点( leve[2]指向的是空节点),于是就会跳到「元素:abc,权重:3」节点的下一层去找,也就是 leve[1];
- 「元素:abc,权重:3」节点的 leve[1] 的下一个指针指向了「元素:abcde,权重:4」的节点,然后将其和要查找的节点比较。
- 虽然「元素:abcde,权重:4」的节点的权重和要查找的权重相同,但是当前节点的 SDS 类型数据「大于」要查找的数据,所以会继续跳到「元素:abc,权重:3」节点的下一层去找,也就是 leve[0];
- 「元素:abc,权重:3」节点的 leve[0] 的下一个指针指向了「元素:abcd,权重:4」的节点,该节点正是要查找的节点,查询结束。
跳表在插入是要尽可能保证上下层的比例是1:2,这样查询的时间复杂度才能维持在O(logn),在创建节点时,会生成一个0-1的随机数,如果随机数小于0.25即向上增加一层指针。
线程模型
Redis 单线程指的是「接收客户端请求->解析请求 ->进行数据读写等操作->发送数据给客户端」这个过程是由一个线程(主线程)来完成的。
Redis 为「关闭文件、AOF 刷盘、释放内存」这些任务会创建单独的线程来处理,是因为这些任务的操作都是很耗时的,如果把这些任务都放在主线程来处理,那么 Redis 主线程就很容易发生阻塞,这样就无法处理后续的请求了。
- Redis 的大部分操作都在内存中完成,并且采用了高效的数据结构,因此 Redis 瓶颈可能是机器的内存或者网络带宽,而并非 CPU,既然 CPU 不是瓶颈,那么自然就采用单线程的解决方案了。
- Redis 采用单线程模型可以避免了多线程之间的竞争,省去了多线程切换带来的时间和性能上的开销,而且也不会导致死锁问题。
- Redis 采用了 I/O 多路复用机制处理大量的客户端 Socket 请求,IO 多路复用机制是指一个线程处理多个 IO 流,就是我们经常听到的 select/epoll 机制。
在 Redis 6.0 版本之后,也采用了多个 I/O 线程来处理网络请求,这是因为随着网络硬件的性能提升,Redis 的性能瓶颈有时会出现在网络 I/O 的处理上。
持久化
AOF日志
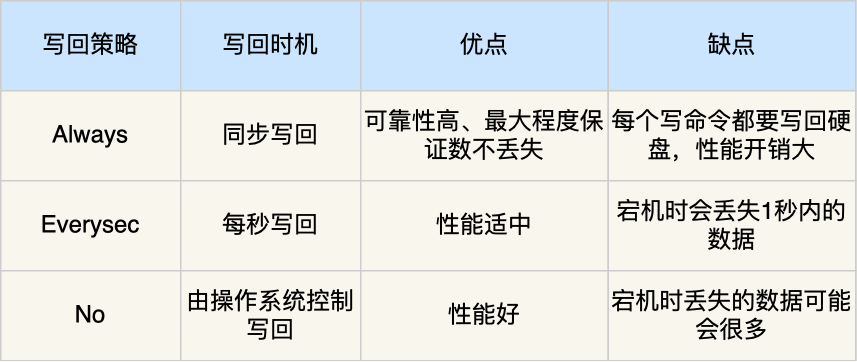
Redis 在执行完一条写操作命令后,就会把该命令以追加的方式写入到一个文件里,然后 Redis 重启时,会读取该文件记录的命令,然后逐一执行命令的方式来进行数据恢复。Redis 存在一个叫做AOF缓冲区的内存区域,我们会先把AOF日志写到缓冲区中,然后找时机写回。
AOF写回策略
AOF重写
AOF 重写机制是在重写时,读取当前数据库中的所有键值对,然后将每一个键值对用一条命令记录到「新的 AOF 文件」,等到全部记录完后,就将新的 AOF 文件替换掉现有的 AOF 文件。
Redis 的重写 AOF 过程是由后台子进程 bgrewriteaof 来完成的:
- 子进程进行 AOF 重写期间,主进程可以继续处理命令请求,从而避免阻塞主进程。
- 子进程带有主进程的数据副本,这里使用子进程而不是线程,因为如果是使用线程,多线程之间会共享内存,那么在修改共享内存数据的时候,需要通过加锁来保证数据的安全,而这样就会降低性能。而使用子进程,创建子进程时,父子进程是共享内存数据的,不过这个共享的内存只能以只读的方式,而当父子进程任意一方修改了该共享内存,就会发生「写时复制」(复制一份父进程的页表给子进程),于是父子进程就有了独立的数据副本,就不用加锁来保证数据安全。
为了解决子进程处理重写时,主进程还在处理请求导致的数据不一致问题,Redis设置了AOF重写缓冲区,执行一条写命令不仅写入AOF缓冲区,还要写入AOF重写缓冲区,当重写完成后,再将AOF重写缓冲区的命令加入新的AOF文件,最后进行替换。
为什么要同时写两个缓冲区呢?
如果只写AOF缓冲区,它有可能被刷盘导致数据不全。
如果只写AOF重写缓冲区,如果重写失败,我们还需要继续按照原来的流程进行,这样也会导致数据不全。
RDB
RDB 快照就是记录某一个瞬间的内存数据,记录的是实际数据,而 AOF 文件记录的是命令操作的日志,而不是实际的数据。
Redis 提供了两个命令来生成 RDB 文件,分别是 save 和 bgsave,他们的区别就在于是否在「主线程」里执行:
- 执行了 save 命令,就会在主线程生成 RDB 文件,由于和执行操作命令在同一个线程,所以如果写入 RDB 文件的时间太长,会阻塞主线程;
- 执行了 bgsave 命令,会创建一个子进程来生成 RDB 文件,这样可以避免主线程的阻塞;
还可以自动bgsave:
save 300 10
# 在300秒内执行了10次操作
执行bgsave时和AOF一样,都是使用的子进程写时复制,如果在RDB过程中数据被修改,则会失去该操作。
混合持久
当开启了混合持久化时,在 AOF 重写日志时,fork 出来的重写子进程会先将与主线程共享的内存数据以 RDB 方式写入到 AOF 文件,然后主线程处理的操作命令会被记录在重写缓冲区里,重写缓冲区里的增量命令会以 AOF 方式写入到 AOF 文件,写入完成后通知主进程将新的含有 RDB 格式和 AOF 格式的 AOF 文件替换旧的的 AOF 文件。
过期删除策略
- 定时删除:注册定时任务,大量同一时间到期可能会打满cpu,内存友好。
- 惰性删除:每次访问该key时检查是否过期,内存不友好,cpu友好。
- 定期删除:每隔一段时间「随机」从数据库中取出一定数量的 key 进行检查,并删除其中的过期key。
Redis 选择「惰性删除+定期删除」这两种策略配和使用,定期删除配置如下:
- 从过期字典中随机抽取 20 个 key; 检查这 20 个 key 是否过期,并删除已过期的 key;
- 如果本轮检查的已过期 key 的数量,超过 5 个(20/4),也就是「已过期 key 的数量」占比「随机抽取 key 的数量」大于 25%,则继续重复步骤 1;
- 如果已过期的 key 比例小于 25%,则停止继续删除过期 key,然后等待下一轮再检查。
总耗时限制在25ms内。
内存淘汰策略
当 Redis 的运行内存已经超过 Redis 设置的最大内存之后,则会使用内存淘汰策略删除符合条件的 key,以此来保障 Redis 高效的运行。
1、不进行数据淘汰的策略 noeviction(Redis3.0之后,默认的内存淘汰策略) :它表示当运行内存超过最大设置内存时,不淘汰任何数据,这时如果有新的数据写入,会报错通知禁止写入,不淘汰任何数据,但是如果没用数据写入的话,只是单纯的查询或者删除操作的话,还是可以正常工作。
2、进行数据淘汰的策略 针对「进行数据淘汰」这一类策略,又可以细分为「在设置了过期时间的数据中进行淘汰」和「在所有数据范围内进行淘汰」这两类策略。
在设置了过期时间的数据中进行淘汰:
volatile-random:随机淘汰设置了过期时间的任意键值;
volatile-ttl:优先淘汰更早过期的键值。
volatile-lru:淘汰所有设置了过期时间的键值中,最久未使用的键值;
volatile-lfu:淘汰所有设置了过期时间的键值中,最少使用的键值;
在所有数据范围内进行淘汰:
allkeys-random:随机淘汰任意键值;
allkeys-lru:淘汰整个键值中最久未使用的键值;
allkeys-lfu(Redis 4.0 后新增的内存淘汰策略):淘汰整个键值中最少使用的键值。
RocketMQ
消息模型
发布订阅模型。
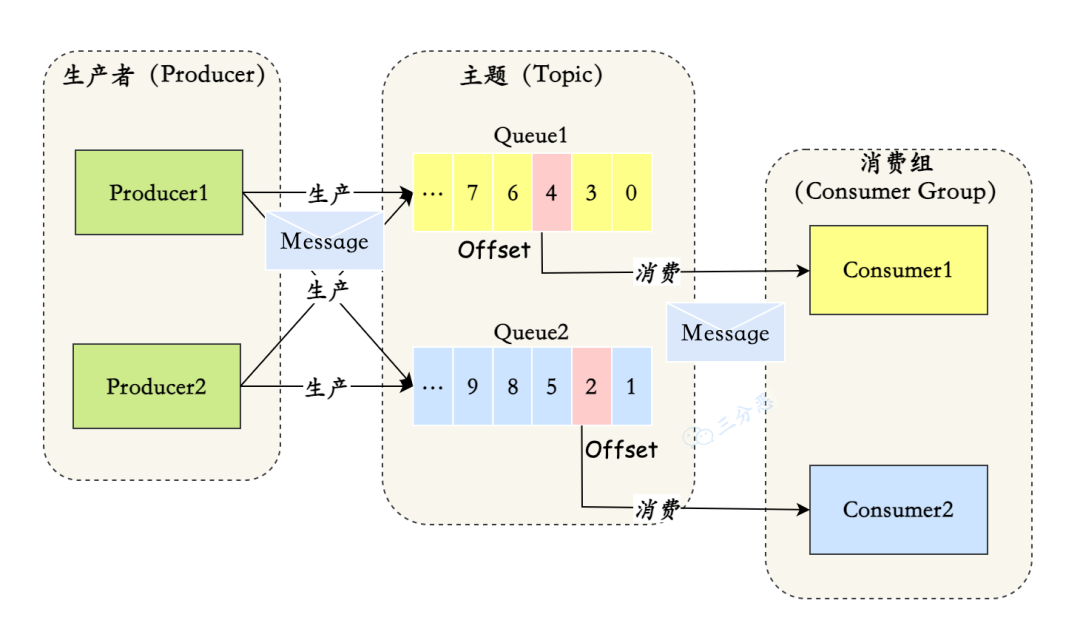
- Message(消息)就是要传输的信息。一条消息必须有一个主题(Topic),主题可以看做是你的信件要邮寄的地址。一条消息也可以拥有一个可选的标签(Tag)和额处的键值对,它们可以用于设置一个业务 Key 并在 Broker 上查找此消息以便在开发期间查找问题。
- Topic(主题)可以看做消息的归类,它是消息的第一级类型。和k个生产者消费者订阅。
- Tag(标签)可以看作子主题,它是消息的第二级类型,用于为用户提供额外的灵活性。使用标签,同一业务模块不同目的的消息就可以用相同 Topic 而不同的 Tag 来标识。
- RocketMQ 中,订阅者的概念是通过消费组(Consumer Group)来体现的。一条数据组内竞争,组间共享。
- Message Queue(消息队列),一个 Topic 下可以设置多个消息队列,Topic 包括多个 Message Queue ,如果一个 Consumer 需要获取 Topic 下所有的消息,就要遍历所有的 Message Queue。
- RocketMQ 为每个消费组在每个队列上维护一个消费位置(Consumer Offset),
Queue是一个长度无限的数组,Offset 就是下标。
消息积压
- 消费者扩容:如果当前 Topic 的 Message Queue 的数量大于消费者数量,就可以对消费者进行扩容,增加消费者,来提高消费能力,尽快把积压的消息消费玩。
- 消息迁移 Queue 扩容:如果当前 Topic 的 Message Queue 的数量小于或者等于消费者数量,这种情况,再扩容消费者就没什么用,就得考虑扩容 Message Queue。可以新建一个临时的 Topic,临时的 Topic 多设置一些 Message Queue,然后先用一些消费者把消费的数据丢到临时的 Topic,因为不用业务处理,只是转发一下消息,还是很快的。接下来用扩容的消费者去消费新的 Topic 里的数据,消费完了之后,恢复原状。
如何保证消息的不丢失
在生产阶段,主要通过请求确认机制,来保证消息的可靠传递。
- 1、同步发送的时候,要注意处理响应结果和异常。如果返回响应 OK,表示消息成功发送到了 Broker,如果响应失败,或者发生其它异常,都应该重试。
- 2、异步发送的时候,应该在回调方法里检查,如果发送失败或者异常,都应该进行重试。
- 3、如果发生超时的情况,也可以通过查询日志的 API,来检查是否在 Broker 存储成功
存储阶段,可以通过配置可靠性优先的 Broker 参数来避免因为宕机丢消息,简单说就是可靠性优先的场景都应该使用同步。同时启用Brocker的主从集群。
Consumer 保证消息成功消费的关键在于确认的时机,在执行完所有消费业务逻辑之后,再发送消费确认。因为消息队列维护了消费的位置,逻辑执行失败了,没有确认,再去队列拉取消息,就还是之前的一条。
处理消息重复
做好幂等,RocketMQ无法保证不重复。幂等:
- 去重表
- 状态机
- version乐观锁
顺序消息
如果是局部顺序,也就是一个订单的订单生成,订单消费顺序,而多个订单之间无序,我们只需要将同一个订单的消息放入同一个队列中即可。
如果是全局有序,我们只能采用只设置一个队列的做法。
但是,以上只能保证消息顺序收到,但不能保证消息顺序消费,这里采用分布式锁,当订单生成消息被取到后,锁住队列,消费后再解锁。
延迟消息
RocketMQ不支持任意时间的延时,只支持以下几个固定的延时等级 private String messageDelayLevel = "1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h";
Broker 收到延时消息了,会先发送到主题(SCHEDULE_TOPIC_XXXX)的相应时间段的 Message Queue 中,然后通过一个定时任务轮询这些队列,到期后,把消息投递到目标 Topic 的队列中,然后消费者就可以正常消费这些消息。
Canal
Canal 主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费,工作原理如下:
- Canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送 dump 协议
- MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 Canal )
- Canal 解析 binary log 对象(原始为 byte 流)
Linux
Linux常用命令
查看进程状态
ps -auxf | grep {}
查看网络状态
netstat -naptu
# t:tcp u:udp p:pid a:all n:not 禁用反向域名解析,加快查询速度
分布式 云原生
CAP
- 一致性(Consistency):一致性就是所有节点在同一时间具有相同的数据。也就是说,当一个节点更新了数据后,其他节点能够立即感知到这一变化,并保持数据的一致性。
- 可用性(Availability):可用性是指每个请求都能收到一个(无论成功或失败的)响应,不会出现超时等情况。即系统能够持续不断地提供服务,不会因为某些节点的故障而导致服务中断。
- 分区容忍性(Partition tolerance):分区容忍性就是系统在出现网络分区这种故障时,还能正常运行。
CA:Raft集群。
CP:MySQL、redis集群。
分布式锁
MySQL
基于MySQL我们可以创建悲观锁和乐观锁。
悲观锁:创建一个锁表,对其ID加上唯一索引,插入时并发会报唯一错误。不可重入,无锁失效。
乐观锁:对要共享的表加入version字段,在获取资源时同时获取version,更新时判断where version == oldversion
Redis
SET mykey "myvalue" NX EX 10
// EX 10s PX 10ms
docker
docker常用命令
docker build -f /path/to/dockerfile .
docker inspect [ID]
docker ps start stop rm rmi pull run exec
为什么docker这么小?
基本生所有的Linux的发行版都公用一个bootfs(用于加载内核),故base镜像只需要包含rootfs,而对于一个精简的OS,只需要包含特定的库和命令,所以base镜像可以做到很小,而base镜像也就值docker最底层,base 镜像提供的是最小安装的 Linux 发行版。
docker镜像分层
docker镜像都是通过在base层的基础上,一层一层软件叠加而成的。
在镜像层的上面有一层容器层,只有容器层是可写的,镜像层是只读的。
采用这种分层结构的好处是可以共享资源,采用copy-on-write技术,只有当修改时,才将数据从镜像层复制过来。可见,容器层保存的是镜像变化的部分,不会对镜像本身进行任何修改。
- 新数据会直接存放在最上面的容器层。
- 修改现有数据会先从镜像层将数据复制到容器层,修改后的数据直接保存在容器层中,镜像层保持不变。
- 如果多个层中有命名相同的文件,用户只能看到最上面那层中的文件。
docker为什么比虚拟机快
docker用于隔离软件,虚拟机用于隔离环境。
运行时:docker有着比虚拟机更少的抽象层。由于docker不需要Hypervisor实现硬件资源虚拟化,运行在docker容器上的程序直接使用的都是实际物理机的硬件资源。因此在CPU、内存利用率上docker将会在效率上有明显优势。
创建时:docker利用的是宿主机的内核,而不需要Guest OS。因此,当新建一个容器时,docker不需要和虚拟机一样重新加载一个操作系统内核。仍而避免引寻、加载操作系统内核返个比较费时费资源的过程,当新建一个虚拟机时,虚拟机软件需要加载Guest OS,返个新建过程是分钟级别的。而docker由于直接利用宿主机的操作系统,则省略了返个过程,因此新建一个docker容器只需要几秒钟
docker原理
namespace用于隔离进程组之间的资源,而cgroup用于控制一个进程组的资源。
**namespace 是 Linux 内核用来隔离内核资源的方式。**通过 namespace 可以让一些进程只能看到与自己相关的一部分资源,而另外一些进程也只能看到与它们自己相关的资源,这两拨进程根本就感觉不到对方的存在。具体的实现方式是把一个或多个进程的相关资源指定在同一个 namespace 中。
Linux namespaces 是对全局系统资源的一种封装隔离,使得处于不同 namespace 的进程拥有独立的全局系统资源,改变一个 namespace 中的系统资源只会影响当前 namespace 里的进程,对其他 namespace 中的进程没有影响。
Linux Cgroup 可让您为系统中所运行任务(进程)的用户定义组群分配资源 — 比如 CPU 时间、系统内存、网络带宽或者这些资源的组合。您可以监控您配置的 cgroup,拒绝 cgroup 访问某些资源,甚至在运行的系统中动态配置您的 cgroup。所以,可以将 controll groups 理解为 controller (system resource) (for) (process)groups,也就是是说它以一组进程为目标进行系统资源分配和控制。
Raft
- 角色划分
- Leader:唯一处理客户端请求的节点,负责日志复制和心跳广播。
- Follower:被动接收Leader的指令,响应选举请求。
- Candidate:选举过程中临时状态,发起投票请求。
- 任期(Term)
- 时间被划分为递增的任期(Term),每个任期最多一个Leader。
- Term用于标识选举轮次和日志的时序性,避免脑裂(Split Brain)问题。
- 日志结构
- 日志条目包含Term、Index和操作命令,必须顺序提交且不允许空洞。
- 所有节点通过日志复制达成一致状态,形成复制状态机。
核心流程
1. Leader选举
- 触发条件:Follower在选举超时(Election Timeout,随机值)内未收到心跳,转为Candidate并发起投票。
- 投票规则
- Candidate需获得 多数派(N/2+1) 节点的投票才能成为Leader,也就意味着新Leader的日志一定是最新的。
- 节点仅投票给日志比自己新的Candidate(通过LastLogIndex和LastLogTerm判断)。
- 避免活锁:随机化选举超时时间,减少多个Candidate同时竞争。
2. 日志复制
- 写入流程
- Leader接收客户端请求,追加日志到本地。
- 通过AppendEntries RPC将日志广播给Followers。
- 当多数派确认后,Leader提交日志并通知Followers提交。
- 日志匹配原则
- 强制Followers的日志与Leader保持一致,通过一致性检查(PrevLogIndex和PrevLogTerm)修复不一致。
- 已提交的日志必须持久化,且不会被覆盖。
- 一致性检查(Consistency Check)
- 旧Leader收到请求后,会检查本地日志是否在
prevLogIndex处与prevLogTerm匹配。- 匹配失败:旧Leader拒绝请求,返回冲突的日志位置,新Leader逐步回退索引(log backtracking),直到找到一致点,强制覆盖旧Leader的后续日志。
- 匹配成功:旧Leader接受新日志,覆盖或追加到本地日志。
leader崩溃后重新加入如何保证日志一致
Raft通过以下机制保证旧Leader重新加入后的日志一致性:
- 强制降级为Follower:旧Leader服从新Leader的日志同步。
- 日志强制覆盖:通过一致性检查和逐步回退,修正不一致的日志。
- 选举安全性:新Leader的日志一定比旧Leader更新。
- 提交规则:已提交日志必然被保留,未提交日志被丢弃。
最终,所有节点(包括重新加入的旧Leader)的日志和状态机完全一致,满足强一致性要求。
快照
- 日志压缩
- 删除已提交且应用到状态机的旧日志,避免日志文件无限增长。
- 例如:若日志索引【1,1000】已提交并应用到状态机,可通过快照保存索引1000的状态,删除1~1000的日志。
- 加速节点恢复
- 新节点加入或故障节点重启时,直接加载快照+增量日志,避免全量日志传输。
- 适用于落后较多(如网络分区后)的节点快速追上新状态。
- 降低同步开销
- 当Leader发现某个Follower的日志落后太多(例如缺失早期日志),直接发送快照而非逐个传输历史日志条目。
Raft如何防止脑裂
1. 多数派选举(Majority Vote)
- 规则:只有获得 多数派(N/2+1) 节点投票的Candidate才能成为Leader。
- 作用
- 网络分区时,仅多数派分区能选出新Leader,少数派分区无法满足多数条件,无法产生合法Leader。
- 示例:5节点集群分为3节点和2节点两个分区,只有3节点分区可选出Leader。
2. 任期递增(Term Increment)
- 规则:每个节点维护当前任期号(Term),且任期严格递增。
- 作用
- 旧Leader(低Term)收到新Leader(高Term)的消息时,自动降级为Follower,终止脑裂状态。
- 示例:旧Leader(Term=2)所在分区恢复后,收到新Leader(Term=3)的心跳,立即放弃Leader身份。
3. 日志提交规则(Commitment Rules)
- 规则:Leader只能提交当前Term的日志,且提交时必须复制到多数派节点。
- 作用
- 即使旧Leader在网络分区期间写入日志,由于无法获得多数派确认,这些日志无法提交,最终会被新Leader覆盖。
- 示例:旧Leader在少数派分区写入日志(Term=2, Index=5),但无法提交;新Leader在多数派分区写入日志(Term=3, Index=5),覆盖旧日志。
编译原理
编译过程
- 预处理阶段主要处理一些预处理指令,比如引入所有include、替换所有宏定义、处理所有条件编译。
- 编译阶段进行语法分析、词法分析和语义分析,并且将代码优化后产生相应的汇编代码文件。
- 将汇编代码翻译成机器码,即生成二进制可重定向文件,但这时函数和变量还都是符号,没有分配地址。
- 链接
- 首先将多个.o 文件相应的段进行合并,建立映射关系并且去合并符号表。进行符号解析,符号解析完成后就是给符号分配虚拟地址。
- 将分配好的虚拟地址与符号表中的定义的符号一一对应起来,使其成为正确的地址。
杂项
什么是栈溢出
- 程序逻辑错误:如递归过深或局部变量过大,导致栈空间耗尽。
- 缓冲区溢出漏洞:向栈中写入的数据超过变量申请的空间,覆盖相邻数据(如返回地址或寄存器),从而被攻击者利用
解决:
- 优化程序逻辑:用迭代替代递归以减少栈深度。减少局部变量大小,或改用堆内存(通过
malloc/new动态分配)。 - 调整栈空间配置:增大栈容量(如通过编译器选项或运行时设置),但需权衡资源消耗。
什么是闭包
假设存在函数 A,其内部定义了函数 B。若 B 引用了 A 的变量,且 B 被传递到 A 的外部(例如作为返回值或被其他变量引用),则 B 与其引用的 A 的变量共同构成闭包。此时:
A的执行环境不会销毁,其变量被B的闭包维持。- 后续执行
B时,仍能操作A中的变量,尽管A已结束执行。
最主要的场景就是回调函数,在某一时间发生时,要求执行某一段逻辑(传入一个匿名函数),这时就构成了闭包。
什么是尾递归
当递归调用是函数体中的最后一个操作时,就构成了尾递归:
- 编译器:在编译型语言(如 C、C++、Rust、Haskell)中,编译器在代码生成阶段对尾递归进行识别和优化,将其转换为等效的循环结构,从而避免创建新栈帧。
- 解释器:在解释型语言(如 Python、JavaScript 的某些引擎)中,解释器在运行时动态分析代码结构,若检测到尾递归调用,直接复用当前栈帧。
408
系统
虚拟内存
为什么要做虚拟内存
- 隔离:防止进程直接访问其他进程的数据。
- 局部性原理:启动时,运行时。
Linux内存布局
分段:外部碎片,利于理解。分页:内部碎片,便于管理。
Linux采用将所有段都从0开始以屏蔽段的影响,采用页布局,共有四级页表(节省内存)。
每个进程的虚拟地址中,内核空间是共享的。
TLB是位于CPU,专门用于缓存页表的cache。
32位如下:3G+1G。64位:128T + 128T
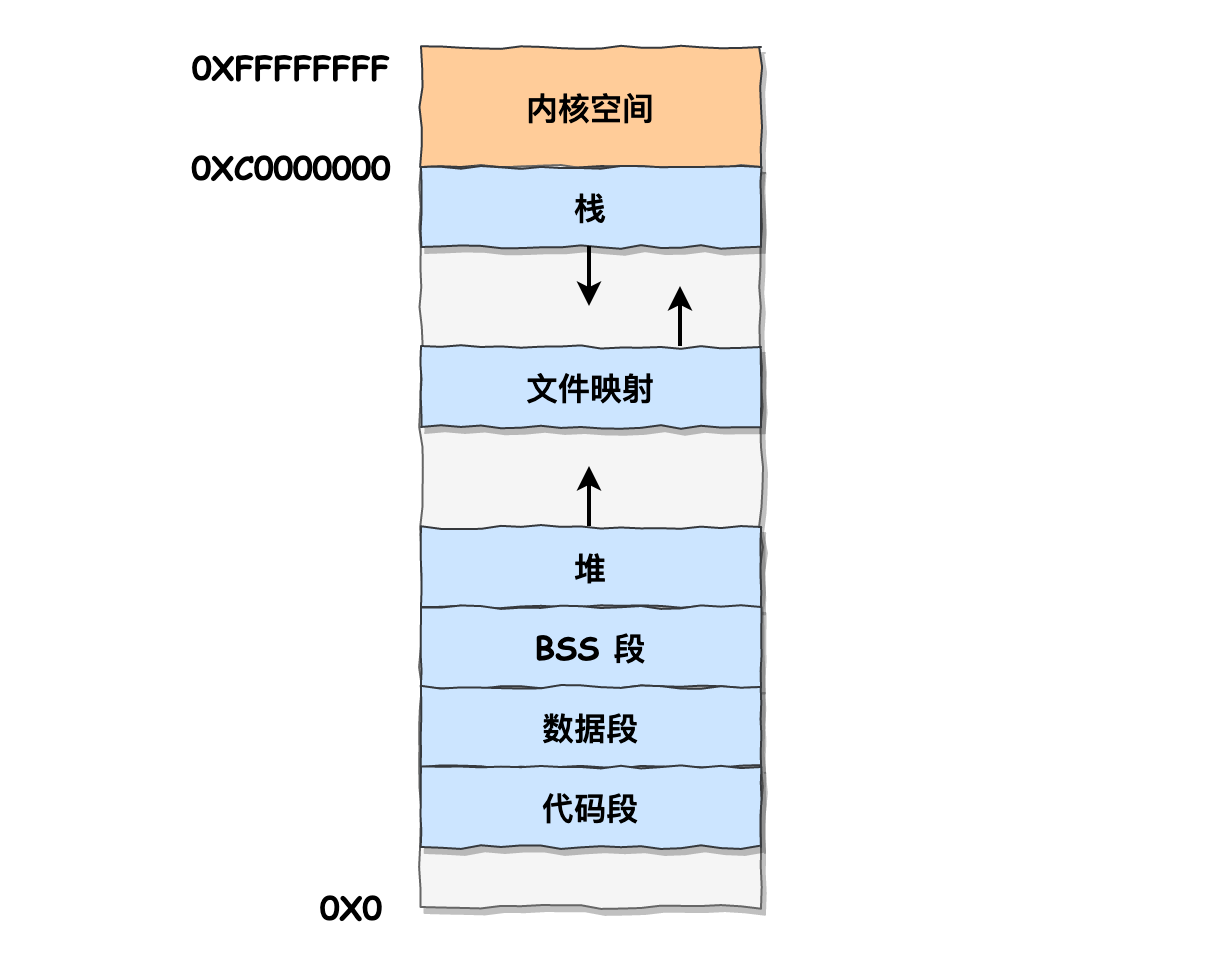
Data:存储所有初始化的全局变量和静态变量。
BSS:存储所有未初始化的全局变量和静态变量,内核初始化为零。
文件映射段:包括动态库、共享内存等
为什么栈比堆快
分配和释放:栈只需要移动
ESP栈指针即可,而堆需要通过动态内存池分配,碎片整理,释放后内存合并等。访问:栈只需要访问
mov eax [ESP + 4]即可,而堆则需要两次访存:mov ecx [ptr] mov eax [eax]
进程、线程管理
PCB
存放进程标识符,用户标识符,进程状态,进程优先级,资源分配,CPU相关寄存器。
以链表的形式连接在一起,组成不同的队列:阻塞队列,就绪队列等
进程间通信
管道,消息队列,共享内存,信号量,信号,socket
多线程信号
信号处理函数必须在多线程进程的所有线程之间共享, 但是每个线程要有自己的挂起信号集合和阻塞信号掩码。
POSIX函数kill/sigqueue必须面向进程, 而不是进程下的某个特定的线程。
每个发给多线程应用的信号仅递送给一个线程, 这个线程是由内核从不会阻塞该信号的线程中随意选出来的。
如果发送一个致命信号到多线程, 那么内核将杀死该应用的所有线程, 而不仅仅是接收信号的那个线程。
调度
主动:陷入阻塞,进程结束,创建进程
被动:时钟中断
核心:在由内核态切换至用户态时检查调度位
算法:FIFO、最短作业优先、多级反馈队列、时间片轮转
上下文切换
进入内核态:将PC、PSW、和ESP(用户栈指针)压入内核栈中。
线程上下文切换:切换内核栈指针,寄存器
进程上下文切换:虚拟内存资源,内核栈指针,寄存器。
中断上下文切换:寄存器。
文件系统
中断
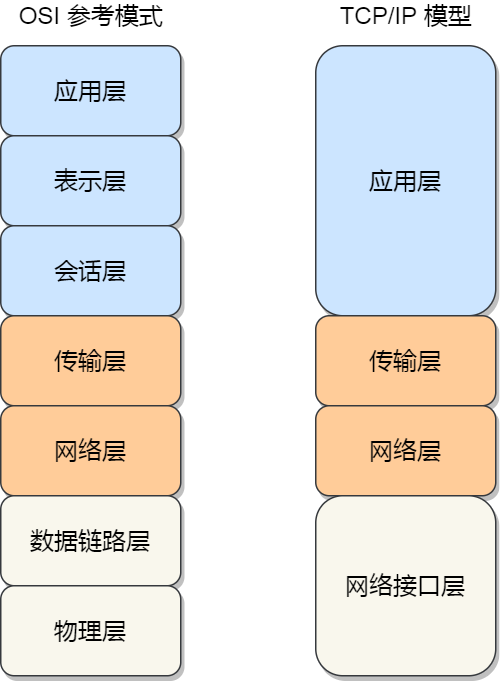
计网
输入网址到页面显示的过程
- 首先浏览器要对URL进行解析,分为:协议,服务器地址或域名,文件位置。
- 若输入的是域名,则需要DNS解析,首先找本机缓存,若没有则找本地DNS服务器,本地DNS服务器若没有,则代理本机进行迭代查询,从根域名到顶级域名再到权威域名......。最后返回IP地址。
- 在获取到目标主机的IP地址后,HTTP报文会进入协议栈,首先到达的是传输层,由于HTTP使用的是TCP协议,所以会传送到TCP层。首先要在端到端的层面完成三次握手,建立TCP连接。如果HTTP的报文长度超过了MSS,则会进行分段。
- 经过传输层,就会进入网络层,任务是完成主机到主机的传输。根据本地的路由表选择网卡发送,如果IP数据报超过了MTU,则会对其分片。
- 到了MAC层,任务是完成点到点的传输,重点是要获取到接收方的MAC地址。发送方的MAC地址是写在网卡的ROM中的。而接收方的MAC则需要进行一系列操作。首先我们要知道下一个点是谁,我们只需要在路由表中进行子网掩码运算就可找到gateway。接下来首先查询ARP高速缓存,若没有则进行广播,等待单播响应,若一个主机(包括路由器端口)接受到目的MAC不是自己的,则丢弃。
- 在本机的最后一步是通过网卡加上帧分界符和FCS后,将数据转换为电信号发送出去。
- 假设我们中间会经过交换机,其是工作在物理层和MAC层,故也称为二层设备。在经过FCS校验之后就根据转发表发送到下一个端口,注意交换机是透明的,无MAC地址。
- 假设我们要访问互联网,那么我们就到了路由器,路由器是三层设备,但实际上现在的路由器算是一个黑匣子,它的很多功能已经超过了三层设备的能力(firewall,NAT,入侵检测)。路由器的每个端口都有MAC和IP地址,在收到一个包时,判断是否发给自己,然后进行FCS检验,有误则丢弃。然后根据最长前缀匹配原则找到目标网段要从哪个网口发出,最后进行发送。默认互联网是
0.0.0.0 - 经过多次的路由器和交换机传递,其中源IP和目的IP是始终不会变的(除了隧道)。MAC是一直在变的。到最后一个路由器,发现目的IP在自己的内网,则会进行直接交付。
- 到了目的主机再逆向进行协议栈的解析,最终到达目的进程。
额外:
在三次握手后,可能会需要进行TLS四次握手。
在路由器时,可能需要经过NAT,常见的是基于端口的NAT代理,将
192.168.1.128:1111变为192.168.1.1:2222
IP层
IPv4
IP地址分为公有地址和私有地址,路由器收到目的地为私有地址的数据包不会转发。
IP分片:DF=0:可以分片,MF=1,后面还有分片。片偏移以8字节为单位,记录数据的偏移量。
IPv6
位数32->128,支持IP自动分配,无需DHCP,强制使用IPSec。
过渡:隧道,双协议栈
IPv6原生支持IPsec扩展头部,可以从各个方面保障数据传输的安全。
缩写:一段内连续0可省略,多个段的连续零和省略::
本地:::1
包头固定40字节。
TCP/UDP
可打开的TCP连接数量
- **TCP连接的客户端机:**每一个ip可建立的TCP连接理论受限于ip_local_port_range参数,也受限于65535。但可以通过配置多ip的方式来加大自己的建立连接的能力。
- **TCP连接的服务器机:**每一个监听的端口虽然理论值很大,但这个数字没有实际意义。最大并发数取决你的内存大小,每一条静止状态的TCP连接大约需要吃3.3K的内存。
同时收到linux最大文件打开数量的限制,
TCP和UDP的区别
- TCP面向连接,UDP无连接:TCP需要通过三握四挥建立连接才能通信。
- TCP可靠,UDP不可靠:TCP通过数据按数据包确认应答、按字节序编号、超时重传保证数据按序可靠交付。
- TCP面向字节流,而UDP面向数据包:TCP会对数据进行分包,一个HTTP包可能被分为多个TCP包。
- UDP效率较高:头部大小8B,无需握手,常用于游戏,直播,音视频等
TCP关于面向连接、可靠的辨析
TCP的三个重要机制:可靠传输、流量控制、拥塞控制。其中可靠传输靠的是序号、应答、重传。
而要想实现序号、应答、重传,则必须要双方建立连接,连接就是用于保证某些状态信息,包括 Socket、序列号和窗口大小。
三次握手
从状态和报文的角度来回答:
- 客户端主动向服务端发送SYN报文,其中序列号初始化随机数,随后客户端由CLOSE进入SYN_SEND状态。
- 当服务端收到之后,发送SYN+ACK报文,初始化自己的序列号随机数,应答号写入客户端的序列号加一,内核会将连接存储到半连接队列(SYN Queue)(SYN泛洪攻击)。随后由LISTEN进入SYN_RCVD状态。
- 客户端收到后发送ACK报文,应答号为服务端序列号加一,同时可以附加上应用层数据。然后进入ESTABLISHED状态。当服务端收到时,内核将连接从半连接队列(SYN Queue)中取出,添加到全连接队列(Accept Queue),也进入ESTABLISHED状态。代表着连接已建立。
为什么一定是三次握手
为什么不是两次握手:
- 无法避免历史连接,浪费资源:如果第一次的SYN阻塞,超时后又发送了一次SYN,新的SYN先到达建立连接。随后历史SYN到达,就会把连接重新初始化了。
- 用于同步序列号:如果采用两次握手,那么当服务器收到客户端的序列号后就建立连接,但此时服务器并不知道客户端是否接受确认到了序列号。
为什么不是四次握手:服务端返回给客户端的SYN和ACK可以合并,所以三次握手已经足以建立连接。
SYN泛洪攻击
典型的DDOS,攻击者不断的向服务器发出TCP握手,但是不进行第三次握手,导致服务器的半连接队列被占满,服务器无法和正常请求建立连接。
- 增大半连接队列。
- SYN cookies:服务器收到SYN报文后生成Cookie = Hash(密钥, 时间戳, 源IP, 目标IP, 源端口, 目标端口, MSS)放入序列号中,客户端收到后确认号为cookie+1,服务器收到后验证通过后建立连接。其中Hash算法
四次挥手
断开连接是双方都可以发起的操作,以客户端断开为例
- 客户端发出FIN报文,随机进入FIN_WAIT_1状态,不再发送数据,但还可以接收数据。
- 服务端收到后首先返回ACK报文,进入CLOSE_WAIT状态,此时还可以发送没有发送完毕的数据。
- 客户端收到后进入FIN_WAIT_2状态,等待服务端的FIN报文
- 服务端返回FIN报文,进入LAST_ACK状态。
- 客户端收到FIN报文,向服务端发送ACK报文,随机进入TIME_WAIT状态(只有主动关闭的一方才有此状态),等待2MSL时间后进入CLOSE状态。
- 当服务端收到ACK响应后,直接进入CLOSE状态。
MSL
MSL:30S。
防止历史连接中的数据,被后面相同四元组的连接错误的接收;
保证「被动关闭连接」的一方,能被正确的关闭;
TCP可靠传输机制
保证到达,按序
TCP会再初始序列号的基础上对字节编号保证数据的按序到达。
TCP默认采用累计确认,对于没有按序到达的包会缓存起来,直到目标数据包到达好一并交付并且应答。
TCP采用超时重传和快速重传(主要用于拥塞控制)。
TCP流量控制
TCP流量控制主要目的是解决两个主机之间速度不匹配的问题。为发送方引入接收窗口(rwnd),由接收方动态的进行调整。如果接受方发送零窗口通知,则发送方开始计时,到时后发送零窗口探测报文。
TCP拥塞控制
TCP拥塞控制目的解决网络拥塞的问题,是一个全局的问题。
拥塞控制包含四个算法:慢开始,拥塞避免,快送重传和快速恢复。
慢开始:为发送方引入拥塞窗口(cwnd),那么现在发送窗口=min{rwnd,cwnd},cwnd每经过一个RTT(可能是多个数据包同时发送)变大一倍(本质是每收到一个数据包就增加一)。
这种增大不是无限制的,当增大的值要超过门限(ssthresh)时,进入拥塞避免阶段。
拥塞避免:cwnd每经过一个RTT,只增加一。
如果发生超时,那么会将cwnd=1,ssthresh=cwnd/2,重新执行慢开始算法。为了解决偶尔几次的丢失,引入快重传和快恢复算法。
快速重传:每当发送方收到三个重复的ACK,则会对其进行重传,避免超时影响,随后进入快速恢复阶段。
快速恢复:cwnd = ssthresh = cwnd / 2
TCP粘包
由于TCP是面向字节流的协议,多次的应用层数据可能合并在同一个TCP报文中发送,此时就发生了粘包。需要应用层数据自己进行解决。
- 固定长度的消息
- 特殊字符作为边界(注意转义):HTTP是回车加换行
- 自定义消息结构。
基于UDP实现TCP & QUIC
如果要完全实现可靠传输,可以直接照抄TCP,但是TCP也有它的弱点,QUIC是Google推出的基于UDP的应用层协议,不仅实现了TCP的功能,同时也完善了TCP的缺点。
QUIC的核心概念:一个Connection(对比TCP 连接)中可以并行的建立多条无关的Stream流。
TCP队头阻塞问题
即TCP对于不按序到达的包仅缓存,直到目标包到达后滑动窗口才后移。在HTTP2中实现的Stream概念,如果TCP连接中的一个Stream被阻塞,那么所有的Stream都会被阻塞。
QUIC为每一个Stream都分配了一个滑动窗口,避免了一个Stream阻塞多个Stream的情况。
流量控制
由于QUIC对每一个Stream都分配了一个滑动窗口,所以QUIC存在基于Stream的流量控制和基于Connection的流量控制。
每当收到的字节数大于最大接受窗口的一半,最大接受窗口右移。
基于Connection的流量控制是将所有的Stream加在一起处理
拥塞协议
QUIC默认采用TCP的拥塞控制,重要的是QUIC是应用层协议,无需内核协议栈支持,可以很快的更新迭代。
更快的连接
在QUIC内部实现了TLS协议,可以做到一个RTT建立连接和加密。
HTTP
状态码
- 「200 OK」是最常见的成功状态码,表示一切正常。如果是非 HEAD 请求,服务器返回的响应头都会有 body 数据。
- 「304 Not Modified」不具有跳转的含义,表示资源未修改,重定向已存在的缓冲文件,也称缓存重定向,也就是告诉客户端可以继续使用缓存资源,用于缓存控制。 4xx 类状态码表示客户端发送的报文有误,服务器无法处理,也就是错误码的含义。
- 「400 Bad Request」表示客户端请求的报文有错误,但只是个笼统的错误。
- 「403 Forbidden」表示服务器禁止访问资源,并不是客户端的请求出错。
- 「404 Not Found」表示请求的资源在服务器上不存在或未找到,所以无法提供给客户端。 5xx 类状态码表示客户端请求报文正确,但是服务器处理时内部发生了错误,属于服务器端的错误码。
- 「500 Internal Server Error」与 400 类型,是个笼统通用的错误码,服务器发生了什么错误,我们并不知道。
- 「502 Bad Gateway」通常是服务器作为网关或代理时返回的错误码,表示服务器自身工作正常,访问后端服务器发生了错误。
常见字段
Host: www.A.com
Connection: Keep-Alive
Content-Type: text/html; Charset=utf-8
Accept: */*
Accept-Encoding: gzip, deflate
Content-Encoding: gzip
GET & POST
GET 的语义是从服务器获取指定的资源,POST 的语义是根据请求负荷(报文body)对指定的资源做出处理。
GET 的语义是请求获取指定的资源。GET 方法是安全、幂等、可被缓存的。 POST 的语义是根据请求负荷(报文主体)对指定的资源做出处理,具体的处理方式视资源类型而不同。POST 不安全,不幂等,(大部分实现)不可缓存。
HTTP 1.1
优点:相较于1.0将TCP升级为长连接,引入流水线技术
缺点:
- 明文传输。
- 效率低。
HTTP2
- 头部压缩:静态字典,动态字典,哈夫曼编码
- 由1.1的文本格式改为二进制格式
- 引入Stream流,多个Stream公用一个Connection
HTTP3
主要的优点都是QUIC的优点。
HTTPS
TLS相当于SSL 3.1
保密性、完整性、身份认证:见加密基础
主要介绍RSA握手:
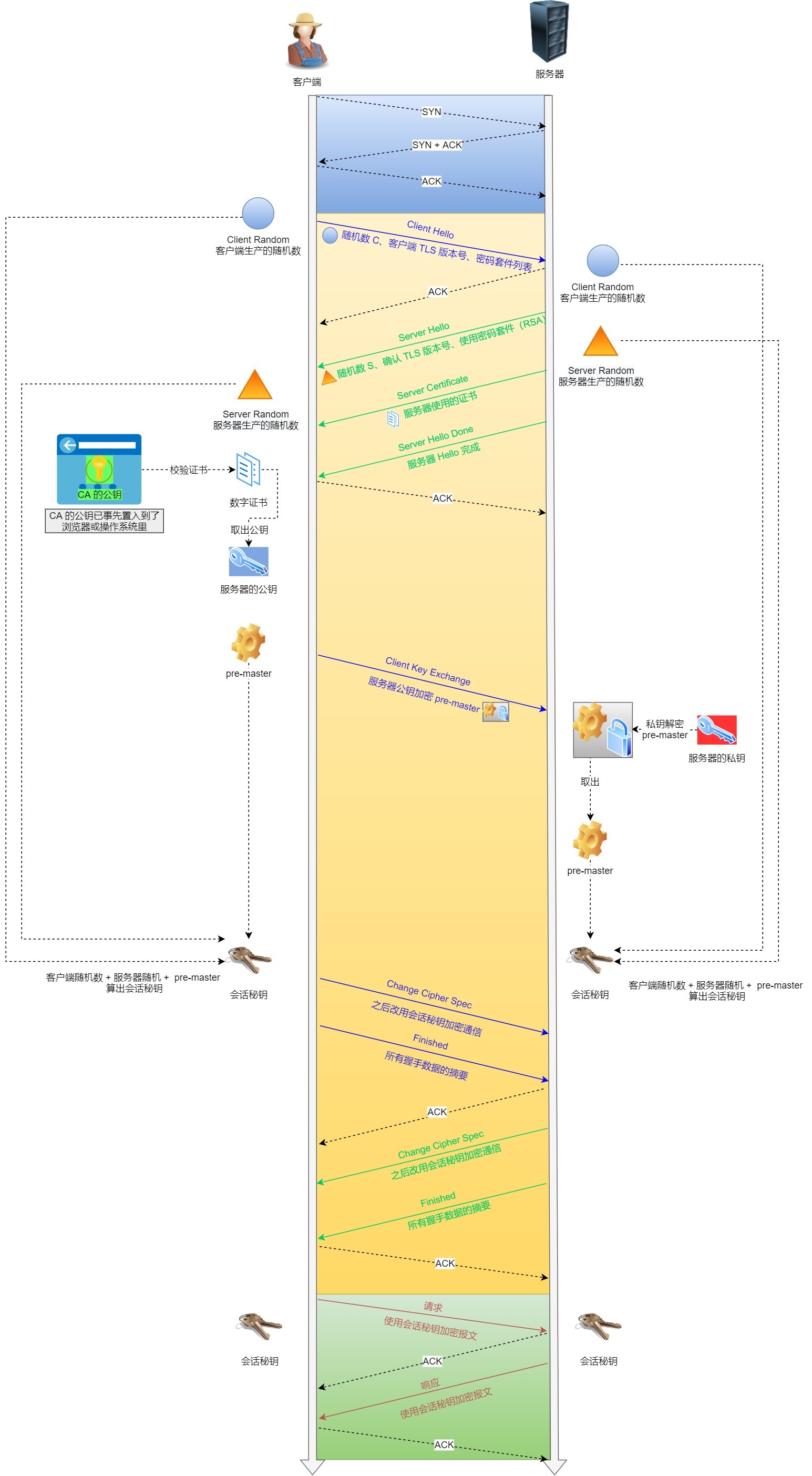
重点协议
内部网关协议
RIP(基于距离矢量)使用UDP,定时向邻居发送整个路由表。直达为1,不可达为16.适用于小型网络。
收到时先将下一跳更改,距离加一,若下一跳不同,则比较大小。若下一跳相同,则直接更新。
坏消息传播的慢:触发更新,源点抑制等
OSPF(链路状态协议),基于IP,适用Dijsktra算法。定时泛洪的向AS内DR交换整个链路状态数据库摘要。
分为骨干区域和非骨干区域,目的:减小流量。
外部网关协议
BGP,用于AS之间,BGP发言人
DNS
应用层协议,一般使用UDP,响应快,当一次查询过多时,采用TCP。都是53端口。
一般采用迭代解析。
首先找本机缓存,若没有则找本地DNS服务器,本地DNS服务器若没有,则代理本机进行迭代查询,从根域名(.)到顶级域名(com)再到权威域名(baidu.com)......。最后返回IP地址。
类型:A-ipv4,AAAA-ipv6,CNAME-别名,PTR-反过来
可能存在DNS劫持,导致访问钓鱼网站:
- 中间人DNS攻击:攻击者执行中间人(MITM)攻击以拦截用户和DNS服务器之间的通信并提供不同的目标IP地址,从而将用户重定向到恶意站点。
- 本地DNS劫持攻击:通过DNS缓存投毒,修改本地DNS服务器,恶意修改DNS映射。
- 路由器DNS劫持攻击:攻击者利用路由器中存在的固件漏洞来覆盖DNS设置,从而影响连接到该路由器的所有用户。攻击者还可以通过利用路由器的默认密码来接管路由器。
及时更新安全软件,使用公用安全的DNS服务器,DNSSEC数字签名以防假冒。
ARP
IP层协议。
主机会通过广播发送 ARP 请求,这个包中包含了想要知道的 MAC 地址的主机 IP 地址。
当同个链路中的所有设备收到 ARP 请求时,会去拆开 ARP 请求包里的内容,如果 ARP 请求包中的目标 IP 地址与自己的 IP 地址一致,那么这个设备就将自己的 MAC 地址塞入 ARP 响应包返回给主机。
操作系统通常会把第一次通过 ARP 获取的 MAC 地址缓存起来,以便下次直接从缓存中找到对应 IP 地址的 MAC 地址。
可能存在ARP欺骗:
- 单向欺骗:攻击者仅针对特定主机发送虚假ARP响应,例如篡改目标主机对网关的MAC地址映射。
- 双向欺骗:攻击者同时欺骗网关和主机,形成双向流量劫持。
静态绑定,交换器启用DAI(Dynamic ARP Inspection 动态ARP检测),发现ARP的响应不符合交换机的转发表,对其进行处理(断网,静默)。
路由器做ARP代理,达到跨网段ARP的作用。
DHCP
应用层协议,基于UDP。由于TCP是一对一的,所以无法使用。
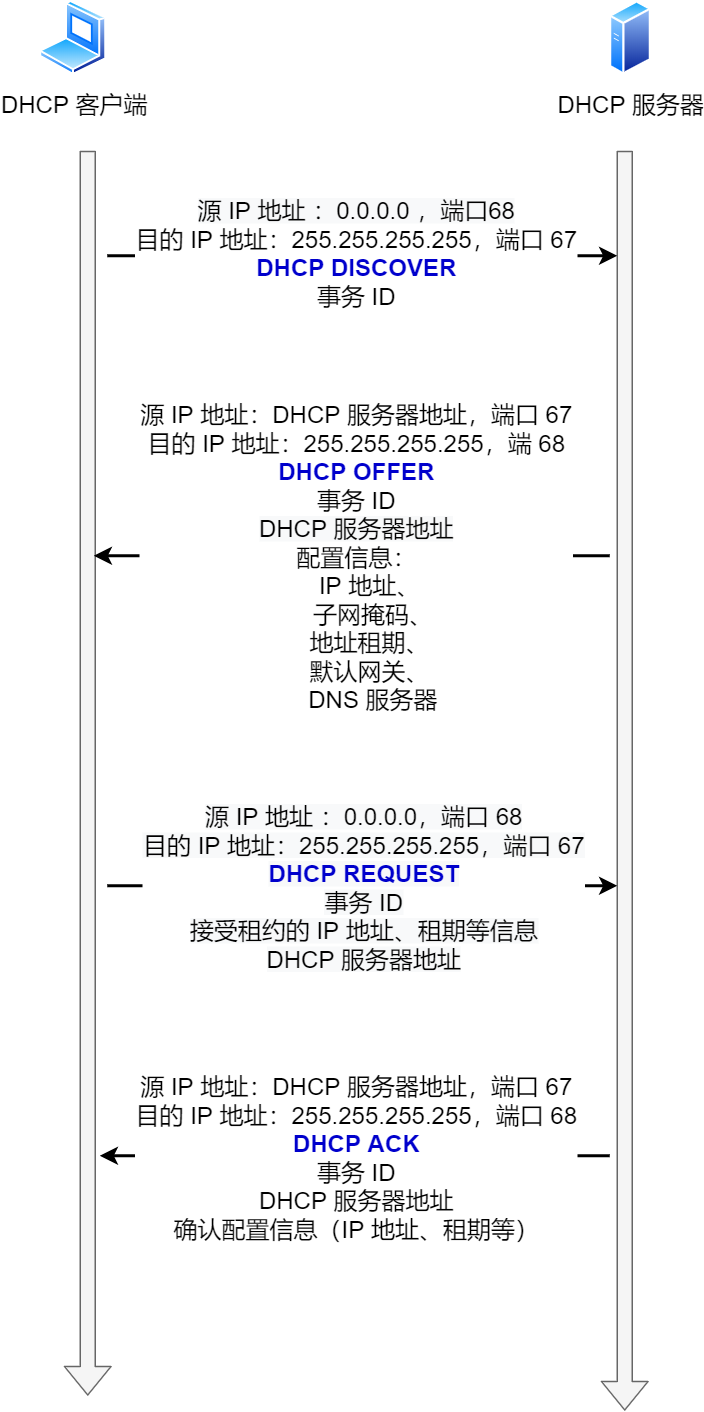
DHCP 中继代理:对不同网段的 IP 地址分配也可以由一个 DHCP 服务器统一进行管理。
DHCP 客户端会向 DHCP 中继代理发送 DHCP 请求包,而 DHCP 中继代理在收到这个广播包以后,再以单播的形式发给 DHCP 服务器。
服务器端收到该包以后再向 DHCP 中继代理返回应答,并由 DHCP 中继代理将此包广播给 DHCP 客户端 。
NAT
基于端口的NAT协议(NAPT)是传输层协议,因为要修改端口号。
生成一个 NAPT 路由器的转换表,就可以正确地转换地址跟端口的组合,这种转换表在 NAT 路由器上自动生成。例如,在 TCP 的情况下,建立 TCP 连接首次握手时的 SYN 包一经发出,就会生成这个表。而后又随着收到关闭连接时发出 FIN 包的确认应答从表中被删除。
ICMP
确认 IP 包是否成功送达目标地址、报告发送过程中 IP 包被废弃的原因和改善网络设置等。
ICMP 大致可以分为两大类:
- 一类是用于诊断的查询消息,也就是「查询报文类型」:回送请求(ping)
- 另一类是通知出错原因的错误消息,也就是「差错报文类型」:源点抑制,重点不可达,时间超过(TTL,如traceroute)等。
VPN
虚拟局域网,VPN在公共互联网上建立一条加密的虚拟通信通道(即隧道),将两个物理隔离的局域网从逻辑上整合为一个统一的网络。
移动IP
家乡地址、转交地址
邮件
smtp:发送
pop3,IMAP:拉取
只支持ASCII,其他使用MIME
网络信息安全
密码学
古典密码:人工计算为基础,算法为核心。置换和代换
现代密码:ji算计计算为基础,以密钥为核心。
现代加密基础
保证数据的保密性:使用非对称加密生成对称密钥,后面使用对称密钥通信。
保证数据的完整性和身份的正确性:对原文求数字摘要**,同时采用自己的私钥进行加密(数字签名)。接收方解开对称加密的数据,求数字摘要,同时使用公钥解开数字签名,求出另一个数字摘要,两个数字摘要进行比对。既可以保证数据是完整的,又可以保证数据是由私钥持有人发送的(私钥不被泄露)。
保证身份的可靠性:如果有人伪造服务端发放公钥,上面的就都无效了。这时引入PKI/CA,证书交换保证身份的可靠性。流程:首先服务端向CA注册自己的公钥,CA使用自己的私钥对服务端的公钥和其他信息进行签名(加密)。当客户端访问某个服务端时,首先取CA获取该服务端的证书,用CA的公钥进行解密(保证CA不被劫持),从中获取到服务端的公钥,这样就保证了访问的服务端一定是正确的。
加密算法
对称加密:DES,3DES,AES,IDEA
非对称加密:RSA(大整数因数分解),ECDHE(椭圆曲线),ElGamal(有限域上的离散对数)
安全协议
IPSec
网络层安全协议,
- AH(Authentication Header)协议:提供身份验证,完整性和抗重放攻击。在IP头后加入AH头。
- ESP(Encapsulated Security Payload)协议,可以选择加密传输层数据,也可以选择加密整个IP报文(隧道模式)。
TLS/SSL
传输层的安全协议,
SET
应用层安全协议。
安全漏洞扫描和入侵检测
- 安全漏洞扫描:维护安全漏洞扫描方法库
- 入侵检测:在网络系统运行过程中,对于正在进行的攻击进行报警和阻断。对于已经发生的攻击,分析日志。通常有两种方式:异常检测(将正常行为建立模型),误用检测(将网络攻击行为建立模型)。
网络攻击
主动
DDOS
攻击者发起攻击并向代理机发送控制指令,代理机就会向被攻击目标主机发送大量的服务请求数据包,这些数据包经过伪装,无法识别它的来源,而且这些数据包所请求的服务往往要消耗大量的系统资源,造成被攻击目标主机无法为用户提供正常服务,甚至导致系统崩溃。
分为直接DDOS(使用僵尸网络):SYN,ICMP,UDP。和反射:例如NTP,以很小的开销即可达成数十万倍的反射流量(服务广泛部署,基于UDP)。
流量清洗,限制带宽
- Web攻击:。
- 病毒和木马:病毒以破坏和传播为特点,而木马以隐藏和盗取控制为特点(客户端和控制端)
XSS
反射性XSS:将恶意脚本嵌入URL中,诱导受害者点击。
http://baidu.com?message=<script>alert("xss")</script>
存储型XSS:将恶意脚本存放到服务端,当受害者访问该页面时就会触发恶意脚本。论坛。
做好转义(< 转义为<)和 过滤。
XSS利用web客户端漏洞,CSRF利用web服务端漏洞。
SQL注入
select * from table where password = ' + password + ';
password = 123' or '1' = '1
则:select * from table where password = '123‘ OR '1' = '1';
CSRF跨站伪造请求
登录受信任站点A,并在本地生成Cookie。在不登出A的情况下,访问危急站点B。受害者点击B中指向A的链接发送有害请求。默认开启CSRF保护。
关键:看HTTP头的refer内容。
文件漏洞
如果外界可以指定文件名下载,且服务端未进行校验
OS命令注入
若服务端程序使用了OS的shell命令,则攻击者可以使用&运算符连接多个命令执行
社会工程
利用人的心理,做好伪装。伪装网站,邮件
缓冲区溢出
没有校验边界,攻击者向缓冲区写入可执行的恶意脚本,并且覆盖返回地址。
return-to-libc:若开启NX保护,数据段和栈是不可执行的,那么我们就需要到libc中寻找system()和/bin/bash,最后覆盖main函数返回地址。
EBP,ESP。
函数调用流程:
- 从后向前参数压栈,返回地址压栈。
- 被调用者保护寄存器。
- 移动EBP
- 调用者保护寄存器,减小ESP,存放局部变量。
被动
- 窃听,流量分析
APT高级持续性威胁
有组织,有计划,长期的网络攻击方式
可信计算
一个RSA密钥存放在TPM芯片中,不可改变。形成一条BIOS-BootLoader-OS-Application的信任链
数字水印
鲁棒水印:用于版权保护,需要能够抵御压缩,噪声,滤波和其他恶意攻击。
脆弱水印:用于完整性保护,既能低于一般的压缩,噪声,又对篡改敏感。
场景
延迟双删
雪花算法
eBPF
eBPF 全称 extended Berkeley Packet Filter,中文意思是 扩展的伯克利包过滤器。它可以在特权上下文中(如操作系统内核)运行沙盒程序,然后在 JIT 编译器和验证引擎的帮助下,操作系统确保它像本地编译的程序一样具备安全性和执行效率。使得我们可以动态向内核添加新功能,而不需要修改重新编译内核。
eBPF程序分为内核态和用户态两部分,内核态一般用于逻辑处理,如进行异常推理,是否过滤,是否转发等。而用户态一般则是进行结果展示。两部分进行数据交换的唯一方法是eBPF Map。
eBPF验证
- 程序必须经过验证以确保它们始终运行到完成,例如一个 eBPF 程序通常不会阻塞或永远处于循环中。eBPF 程序可能包含所谓的有界循环,但只有当验证器能够确保循环包含一个保证会变为真的退出条件时,程序才能通过验证。DAG
- 程序不能使用任何未初始化的变量或越界访问内存。在每次从map中取值后都要判空。
- 程序必须符合系统的大小要求。不可能加载任意大的 eBPF 程序。1M,512KB。
- 程序必须具有有限的复杂性。验证器将评估所有可能的执行路径,并且必须能够在配置的最高复杂性限制范围内完成分析。
怎么做一个eBPF程序
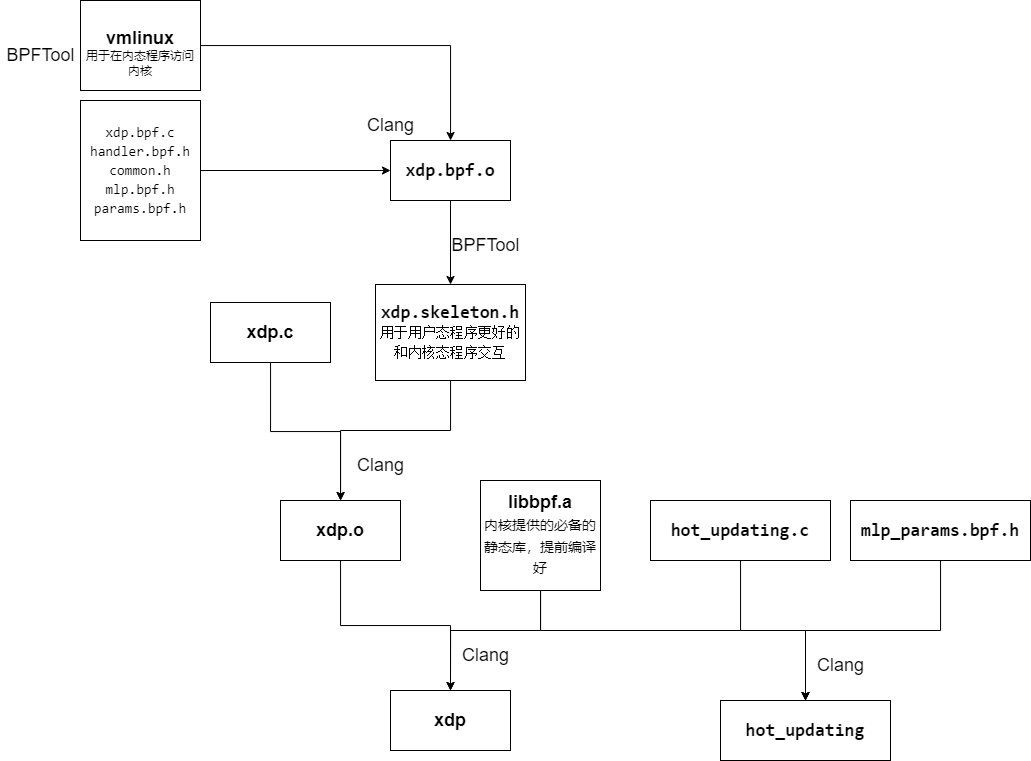
首先写好内核态和用户态的代码,编译libbpf和bpftool。
- 使用bpftool生成vmlinux头文件。
- 使用clang编译vmlinux和写好的内核态代码,生成内核态
.o文件。 - 使用bpftool生成xdp.skeleton.h骨架文件,便于用户态使用。
- 在使用clang将骨架文件,libbpf.a和用户态文件一起编译为可执行文件。
Map
用很多类型的eBPF Map,最常用的是Array和HashMap。还有QUEUE等。
Hash更新是原子的
network
| Hook 名称 | 主要位置 | 主要用途 |
|---|---|---|
| XDP | NIC (L2) | 高速过滤、负载均衡 |
| TC | 网络栈 (L3/L4) | QoS、包修改 |
复试准备
专业面
为什么没过六级
我现在自身也意识到了英语学习的重要性。对于英语的学习,我投入的精力和时间还是不够,再加上我的英语听力较弱,这也是我要提高的地方。我会在接下来的时间好好规划我的英语学习,为后续阅读文献打好基础,做好准备。
自我介绍:
不会的:
老师这个问题我没怎么了解过或者了解的不深入,但是我想结合自己所学谈一谈看法或者理解。根据我的专业所学,根据某某基本原理,这个事情应该是怎么个情况,我的看法是怎么个情况。然后再来一句,老师我这都是靠常理推测,不一定对,请老师批评指正。
为什么要选择考研,我们学校,方向
对某领域有很深的兴趣,尤其在本科接触到某个课程或某个项目之后,发现自己在理论和实践上仍然学习和提升,从而为未来的学术研究和发展打下坚实的基础,贵校在某领域好,尤其是具体方向具体老师对某方向的研究和论文和我的兴趣高度契合。
wait
引用和指针,Java和go和C++(GC,区别)
实验是什么为什么怎么做的
最后你有什么问题问我吗
辛苦老师本次面试,我没有什么问题了
毕设
总体
你这个设计的使用场景是什么,有什么优势
本设计主要用于实时入侵检测与预防,将入侵检测与预防工作负载转移到内核中,利用 eBPF 技术减少了实时网络数据捕获的开销,并且在模型性能和推理开销之间取得了较好的平衡。同时,通过重新设计神经网络推理机制和参数热更新机制,进一步降低了内存开销和推理时间,提高了系统的实时性和效率。
传统的入侵检测:
- 使用tcpdump获取数据包
为什么要嵌入内核,不会导致内核不安全吗
eBPF(是什么,为什么)
热更新怎么做的
使用param Map对神经网络参数做保留两份参数,同时使用一个idx Map保留当前使用的参数下标。当我们对参数进行热更新时,首先将参数更新至param Map未使用的一侧,然后更新idx Map。
为了保证在一个流检测过程中不会被热更新模型参数所影响,对每一个流增加一个下标属性,保留其在最开始使用的param Map下标。
目前国内外有相关的工作吗
很少,有在eBPF中实现DT的,效果要好于在用户态实现DT,但是使用DT有缺点:
- DT每次训练后形状不同,为存储在eBPF Map中造成了困难。
- 为了进行实时热更新,我们必须为DT留下最坏情况下的空间。
- 最坏情况下,假设深度为10,则DT占用空间至少为:
4为(特征索引,分割阈值,两个子节点)
流程
当一个新的网络流到达时,为其记录创建一个Map entry,每收到一个包就提取其特征(120ns),当发现RST或FIN为1时,对其进行入侵检测(5000ns,5us)。
首先对其进行归一化,然后不断的通过bpf tail call,进行linear(6\*32)-> relu -> linear(32\*32) ->relu->linear(32*2)
公式
自定义int32的数学公式怎么算的
特征选取
在采用eBPF方案后,首要的关注点是选择什么样的hook,最常用的hook有两种:XDP,TC。
- 其中XDP的触发时机是数据包到达网卡时,处于数据链路层。这时未进入内核协议栈,sk_buffer还未分配。性能最高,适合做负载均衡,流量过滤。
- TC处于网络层和传输层,此时已经分配sk_buffer,处于协议栈内部。性能低于XDP,适合做Qos,NAT等。
考虑到:
- 流量过滤和入侵检测通常会在流量较大的场景下使用(DOS)。
- 要尽可能的减少特征提取和推理对正常数据流通的影响。
这里综合考虑选择了XDP。
而XDP只能观测到RX方向上的数据,再加上eBPF的512KB的栈空间和1M的指令数大小,以及尽可能的降低内核负载,综合实验考虑选取了
包的最大长度,两个包之间的最大间隔,包的最小长度,目的端口,头部总字节数,总包数
这六个RX特征。
实验过程:
- 对所有RX方向的特征做决策树。
- 对特征按照基尼增益排序。
- 进行增量式的对比实验。
为什么自己造数据集,怎么造
去除了:
- 由于特征限制无法很好的进行判别的实例
- 已经过时的实例
- 重复出现的实例
最后选取了:
- 正常:FTP上传下载,HTTP,SSH
- 异常:暴力破解(FTP,SSH),端口扫描,XSS,DOS slowhttptest。
超参数设置
S的确定
根本做法是将浮点数转化为整数,同时要保证:
- 不溢出
- 性能不会失去太多
- 量化后绝对值不能小于1,否则会被截断
实验分析:
做了归一化,均值为0,标准差为1,一般不溢出。
性能方面当S等于时,四项指标都在90%左右。当S等于次方时,四项指标在98%左右。
在量化方面,根据ECDF(经验累积分布函数),当S等于时,量化后的参数被截断的概率达到了1%,而当S等于次方时,被截断的概率为0.5%。
最后选择了S=2^16.
模型的选择
DT有缺点:
- DT每次训练后形状不同,为存储在eBPF Map中造成了困难。
- 为了进行实时热更新,我们必须为DT留下最坏情况下的空间。
- 最坏情况下,假设深度为10,则DT占用空间至少为:
4为(特征索引,分割阈值,两个子节点)
SVM经过实验性能很差,因为kernel为linear的SVM只能拟合线性分布,而kernel为非linear的SVM训练时间过长,且相较于linear性能没有提升多少。
NN_int8 模型量化之后误差显著上升,导致精度降低
模型隐藏层大小和深度的选择
通过对比实验[6,32,32,2]是兼顾负载和性能的最佳选择,
参数内存占用仅为
怎么做的对比实验:枚举深度和层大小
性能
耗时是多少? 推理耗时:5us,特征提取:120ns
占用内存是多少? 模型:5KB,特征存储:,其中n是并发的流数目。
CPU占用多少:?
为什么选用这些指标,怎么算的
后续
对持续连接的处理不足
- 缺点:当前实现的模型仅在流结束时进行检测,不适用于持久连接中的入侵检测。对于需要长时间保持的连接,无法实时检测入侵。
- 改进:可以考虑对每个接收到的数据包进行检测,或者在特定时间窗口内对流特征进行检测。虽然这会增加计算开销,但可以通过优化算法来平衡实时性和性能。
特征选择的局限性&对新型入侵的适应性
- 缺点:虽然作者通过特征重要性分析选择了6个特征,但这些特征可能不涵盖所有可能的入侵行为模式。此外,特征选择基于历史数据,可能无法适应新的入侵类型。且只支持TCP检测。
- 改进:可以定期重新评估特征的重要性,并根据新的数据和入侵模式更新特征集。此外,可以结合领域知识和专家意见,引入更多潜在的有用特征。
算法
int a = 1;
string s = to_string(a);
stoi(s);
atoi(s.c_str());
DP
有几种(组合数和排列数),最值,是否可以。
关于字符串,dp要留一个空字符串的状态(编辑距离)
优化前后i的取值,是否初始化,内层遍历顺序。
股票状态:持有 未持有
结果一定是dp[size - 1][target]吗?有没有可能是res=max(res, dp[i][j]),如果是res的话,有没有可能在初始化上修改res;
最长系列,最长连续不连续子序列的区别(怎么推导不连续的状态转移)
基础算法
堆排,前缀和
快排
void qs(int l, int r) {
if(l >= r) return;
int i = l - 1, j = r + 1;
int mid = q[(l + r) >> 1];
while(i < j) {
while(q[++ i] < mid);
while(q[-- j] > mid);
if(i < j) swap(q[i], q[j]);
}
qs(l, j), qs(j + 1, r);
}
二分
int left_bound(vector<int>& nums, int target) {
int left = 0, right = nums.size() - 1;
// 搜索区间为 [left, right]
while (left <= right) {
int mid = left + (right - left) / 2;
if (nums[mid] < target) {
// 搜索区间变为 [mid+1, right]
left = mid + 1;
} else if (nums[mid] > target) {
// 搜索区间变为 [left, mid-1]
right = mid - 1;
} else if (nums[mid] == target) {
// 收缩右侧边界
right = mid - 1;
}
}
// 判断 target 是否存在于 nums 中
// 如果越界,target 肯定不存在,返回 -1
if (left < 0 || left >= nums.size()) {
return -1;
}
// 判断一下 nums[left] 是不是 target
return nums[left] == target ? left : -1;
}
int right_bound(int[] nums, int target) {
int left = 0, right = nums.length - 1;
while (left <= right) {
int mid = left + (right - left) / 2;
if (nums[mid] < target) {
left = mid + 1;
} else if (nums[mid] > target) {
right = mid - 1;
} else if (nums[mid] == target) {
// 这里改成收缩左侧边界即可
left = mid + 1;
}
}
// 最后改成返回 right
if (right < 0 || right >= nums.length) {
return -1;
}
return nums[right] == target ? right : -1;
}
int search(vector<int>& nums, int target) {
int left = 0;
int right = nums.size() - 1;
while(left <= right) {
int mid = left + (right - left) / 2;
if(nums[mid] == target) {
return mid;
} else if (nums[mid] < target) {
// 注意
left = mid + 1;
} else if (nums[mid] > target) {
// 注意
right = mid - 1;
}
}
return -1;
}
数学
求最大公约数:gcd
试除法判断质数(i < x / i)
分解质因数:将一个数分解为多个质数和它的质数的形式,一个一个尝试
试除法求约数:(i < x / i)但是要加上 if(i != x / i) v.push_back(x / i);
数据结构
// 并查集
// 路径压缩 O(logn)-O(1)
int find(int x) {
if(p[x] != x) p[x] = find(p[x]);
return p[x];
}
p[i] = i; // 初始化
// 还有按秩合并,没有必要实现
图
图记住初始化:
- 链式前向星h -1
- 并查集p: i
- dist距离:INF
拓扑排序
图的初始化、手写队列、图的遍历(模拟邻接表)
#include <bits/stdc++.h>
using namespace std;
const int N = 2e5 + 10;
int h[N], e[N], ne[N], idx; // important
int n, m;
int in[N], q[N];
void add(int a, int b) { // important
e[idx] = b, ne[idx] = h[a], h[a] = idx ++;
}
bool tp() {
int head = 0, rear = 0; // important
int cnt = 0;
for(int i = 1; i <= n; i ++) {
if(in[i] == 0) {
q[head ++] = i; // important
}
}
while(head > rear) {
int t = q[rear ++]; // important
cnt ++;
for(int i = h[t]; i != -1; i = ne[i]) { // important
int j = e[i];
in[j] --;
if(in[j] == 0) {
q[head ++] = j;
}
}
}
return cnt == n;
}
int main() {
memset(h, -1, sizeof h); // important
cin >> n >> m;
while(m --) {
int a, b;
cin >> a >> b;
add(a, b);
in[b] ++;
}
if(tp()) {
for(int i = 0; i < n; i ++) cout << q[i] << " ";
}else cout << -1;
return 0;
}
Dijkstra
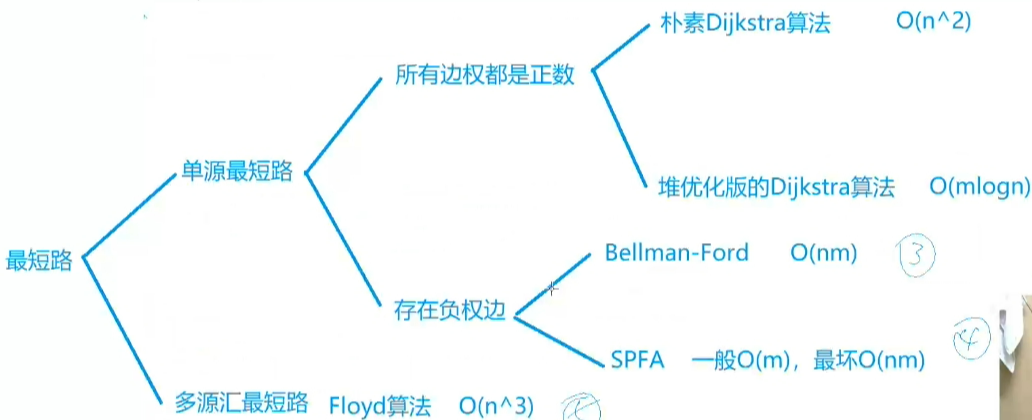
不能存在负权边。
朴素 稠密图
#include <bits/stdc++.h>
using namespace std;
const int N = 510, M = 1e5 + 10;
int h[N], e[M], w[M], ne[M], idx;
int n, m;
int d[N];
bool st[N];
void add(int a, int b, int z) {
e[idx] = b, w[idx] = z, ne[idx] = h[a], h[a] = idx ++; // important
}
void dij() {
d[1] = 0;
// st[1] = true; 这一句不能加 更新1号点的出边 important
for(int i = 1; i <= n; i ++) {
int t = -1;
for(int j = 1; j <= n; j ++) {
if(!st[j] && (t == -1 || d[t] > d[j])) t = j;
}
st[t] = true;
for(int i = h[t]; i != -1; i = ne[i]) {
int j = e[i];
d[j] = min(d[j], d[t] + w[i]);
}
}
}
int main() {
memset(h, -1, sizeof h);
memset(d, 0x3f3f3f3f, sizeof d); // important
cin >> n >> m;
while(m --) {
int a, b, z;
cin >> a >> b >> z;
add(a, b, z);
}
dij();
if(d[n] != 0x3f3f3f3f) cout << d[n];
else cout << -1;
return 0;
}
堆优化,小根堆的设置,去重的理解(可能多次入队)
#include <bits/stdc++.h>
using namespace std;
typedef pair<int,int> PII;
struct cmp { // important
bool operator()(PII a, PII b) {
return a.second > b.second;
}
};
const int N = 2e5 + 10, M = N;
int h[N], e[M], ne[M], w[M], idx;
int d[N];
bool st[N];
int n, m;
void add(int a, int b, int z) {
e[idx] = b; w[idx] = z; ne[idx] = h[a]; h[a] = idx ++;
}
void dijkstra() {
priority_queue<PII, vector<PII>, cmp> heap; // important
// 序号, 距离
d[1] = 0;
heap.push({1, 0});
while(heap.size()) {
PII t = heap.top(); heap.pop();
int a = t.first, v = t.second;
if(st[a]) continue; // important
st[a] = true;
for(int i = h[a]; i != -1; i = ne[i]) {
int b = e[i];
if(d[b] > d[a] + w[i]) {
d[b] = d[a] + w[i];
heap.push({b, d[b]}); // important
}
}
}
}
int main() {
memset(d, 0x3f3f3f3f, sizeof d);
memset(h, -1, sizeof h);
cin >> n >> m;
while(m --) {
int a, b, c;
cin >> a >> b >> c;
add(a, b, c);
}
dijkstra();
if(d[n] != 0x3f3f3f3f) cout << d[n];
else cout << -1;
return 0;
}
Ford
当有负环存在a点到b点的最短路上时,a点到b点无最短路(-inf)。两点之间的最短路可以为负数,注意和负环的区别。
可以处理负权边,可以存在负环。
常用于解决有边数限制的最短路。(不超过K条边)
- 因为要遍历所有边,所以直接用结构体数组存。
- 使用backup数组保证本次松弛只使用上一次的数据(类似滚动数组)
- 由于0x3f并不是无穷大,它是有可能被负边更新的,所以采用更宽松的判断
// for n次
// for 所有边 a,b,w (松弛操作)
// dist[b] = min(dist[b],back[a] + w)
#include <bits/stdc++.h>
using namespace std;
const int N = 510, M = 10010;
int dist[N], backup[N];
struct edge { // important
int a, b, w;
}Edge[M];
int n, m, k;
void bf() {
dist[1] = 0;
for(int i = 0; i < k; i ++) {
memcpy(backup, dist, sizeof dist); // important 注意顺序
for(int j = 0; j < m; j ++) {
int a = Edge[j].a, b = Edge[j].b, w = Edge[j].w;
dist[b] = min(dist[b], backup[a] + w);
}
}
if(dist[n] > 0x3f3f3f3f / 2) cout << "impossible"; // important
else cout << dist[n];
}
int main() {
memset(dist, 0x3f, sizeof dist);
cin >> n >> m >> k;
for(int i = 0; i < m ; i ++) {
int a, b, w;
cin >> a >> b >> w;
Edge[i] = {a, b, w};
}
bf();
return 0;
}
判断负环
// for n次
// for 所有边 a,b,w (松弛操作)
// dist[b] = min(dist[b],back[a] + w)
#include <bits/stdc++.h>
using namespace std;
const int N = 2010, M = 10010;
int dist[N], backup[N], cnt[N]; // important
struct edge {
int a, b, w;
}Edge[M];
int n, m, k;
bool bf() {
for(int i = 0; i < n; i ++) {
memcpy(backup, dist, sizeof dist); // important
for(int j = 0; j < m; j ++) {
int a = Edge[j].a, b = Edge[j].b, w = Edge[j].w;
if(dist[b] > backup[a] + w) {
dist[b] = backup[a] + w;
cnt[b] = cnt[a] + 1; // important
if(cnt[b] >= n) return true;
}
}
}
return false;
}
int main() {
cin >> n >> m;
for(int i = 0; i < m ; i ++) {
int a, b, w;
cin >> a >> b >> w;
Edge[i] = {a, b, w};
}
if(bf()) cout << "Yes";
else cout << "No";
return 0;
}
SPFA
#include <bits/stdc++.h>
using namespace std;
const int INF = 0x3f3f3f3f;
const int N = 1e3 + 10, M = 1e5 + 10;
int h[N], e[M], ne[M], w[M], idx;
int d[N];
int n, m;
bool st[N];
void add(int a, int b, int c) {
e[idx] = b, w[idx] = c, ne[idx] = h[a], h[a] = idx ++;
}
void bf() {
d[1] = 0;
queue<int> q;
q.push(1);
st[1] = true; // important 注意st数组的用法,这里st只是为了保证一个元素不会同时入队两次,而前面的st都是为了一个元素只入队一次。
while(q.size()) {
int t = q.front(); q.pop();
st[t] = false;
for(int i = h[t]; i != -1; i = ne[i]) {
int j = e[i];
if(d[j] > d[t] + w[i]) {
d[j] = d[t] + w[i];
if(!st[j]) {
q.push({j});
st[j] = true;
}
}
}
}
if(d[n] >= INF / 2) cout << "unconnected";
else cout << d[n];
}
int main() {
memset(h, -1, sizeof h);
memset(d, INF, sizeof d);
cin >> n >> m;
for(int i = 0; i < m; i ++) {
int a, b, c;
cin >> a >> b >> c;
add(a, b, c);
}
bf();
return 0;
}
判断负环
#include <bits/stdc++.h>//spfa求负环
using namespace std;
typedef long long LL;
typedef pair<int,int> PII;
const int N=1e6;
int n,m;
int d[N],h[N],e[N],ne[N],w[N],idx,cnt[N];
bool st[N];
void add(int a,int b,int c)
{
e[idx]=b,w[idx]=c,ne[idx]=h[a],h[a]=idx++;
}
bool spfa()
{
queue<int> a;
for(int i=1;i<=n;i++)
{
a.push(i);
st[i]=true;
}
while(a.size())
{
int t=a.front();
a.pop();
st[t]=false;
for(int i=h[t];i!=-1;i=ne[i])
{
int j=e[i];
if(d[j]>d[t]+w[i])
{
d[j]=d[t]+w[i];
cnt[j]=cnt[t]+1;//每次成功更新,都让其经过的边数等于与上一个点加一,
if(cnt[j]>=n) return true;//如果说经过的变数大于总点数 ,那么一定有重复点,也就是存在环
if(!st[j])
{
st[j]=true;
a.push(j);
}
}
}
}
return false;
}
int main(){
ios::sync_with_stdio(false);
cin>>n>>m;
memset(h,-1,sizeof h);
for(int i=0;i<m;i++)
{
int a,b,c;
cin>>a>>b>>c;
add(a,b,c);
}
if(spfa()) cout<<"Yes";
else cout<<"No";
return 0;
}
Floyd
#include <bits/stdc++.h>
using namespace std;
const int N = 1e3 + 10, INF = 0x3f3f3f3f;
int g[N][N];
int n, m;
void floyd() {
for(int k = 1; k <= n; k ++) {
for(int i = 1; i <= n; i ++) {
for(int j = 1; j <= n; j ++) {
g[i][j] = min(g[i][j], g[i][k] + g[k][j]);
}
}
}
}
int main() {
cin >> n >> m;
for(int i = 1; i <= n; i ++) {
for(int j = 1; j <= n; j ++) {
if(i == j) g[i][j] = 0; // important init
else g[i][j] = INF;
}
}
for(int i = 0; i < m; i ++) {
int a, b, c;
cin >> a >> b >> c;
g[a][b] = min(g[a][b], c);
g[b][a] = min(g[a][b], c);
}
floyd();
int k;
cin >> k;
while(k --) {
int a, b;
cin >> a >> b;
if(g[a][b] == INF) {
cout << -1;
}else cout << g[a][b];
cout << endl;
}
return 0;
}
prime
#include <bits/stdc++.h>
using namespace std;
const int N = 1e5 + 10, M = 1e6 + 10;
const int INF = 0x3f3f3f3f;
int n, m;
int h[N], e[M], ne[M], w[M], idx;
void add(int a, int b, int c) {
e[idx] = b, w[idx] = c, ne[idx] = h[a], h[a] = idx ++;
}
int d[N];
bool st[N];
int prime() {
int res = 0;
memset(d, INF, sizeof d);
d[1] = 0;
for(int i = 1; i <= n; i ++) {
int t = -1;
for(int j = 1; j <= n; j ++) {
if(!st[j] && (t == -1 || d[j] < d[t])) t = j;
}
if(d[t] == INF) return INF; // important 剪枝
res += d[t]; // important 每找到一个距离集合最近的点,这条边就是最小生成树的一条边
st[t] = true;
for(int i = h[t]; i != -1; i = ne[i]) {
int j = e[i];
d[j] = min(d[j], w[i]); // important 和dj的区别
}
}
return res;
}
int main() {
memset(h, -1, sizeof h);
cin >> n >> m;
for(int i = 0; i < m; i ++) {
int a, b, c;
cin >> a >> b >> c;
add(a, b, c);
add(b, a, c);
}
cout << prime();
return 0;
}
kruskal
#include <bits/stdc++.h>
using namespace std;
const int N = 1e5 + 10, M = 1e6 + 10;
int n, m;
int d[N], p[N];
struct edge {
int a, b, w;
}Edges[M];
int find(int x) {
if(p[x] != x) p[x] = find(p[x]);
return p[x];
}
bool cmp(edge a, edge b) {
return a.w < b.w;
}
int main() {
cin >> n >> m;
for(int i = 0; i < n; i ++)p[i] = i; // important
for(int i = 0; i < m; i ++) {
int a, b, c;
cin >> a >> b >> c;
Edges[i] = {a, b, c};
}
sort(Edges, Edges + m, cmp);
int res = 0;
int cnt = 0;
for(int i = 0; i < m; i ++) {
int a = Edges[i].a, b = Edges[i].b, w = Edges[i].w;
int pa = find(a), pb = find(b);
if(pa != pb) {
p[pb] = pa;
res += w; // important
cnt ++;
}
}
if(cnt < n - 1) cout << -1;
else cout << res;
return 0;
}
stl
bool cmp_score(Student x,Student y){
return x.score > y.score;
}
sort(nums,nums+10);
sort(nums.begin(),nums.end(),cmp_score);
#include <queue>
// 声明一个整型优先队列
priority_queue<int> pq;
// 声明一个自定义类型的优先队列,需要提供比较函数
struct compare {
bool operator()(int a, int b) {
return a > b; // 这里定义了最小堆
}
};
priority_queue<int, vector<int>, compare> pq_min;
pq._min. top push pop empty
英文面试准备
问题
Can you introduce your competition Can you introduce your graduation thesis Introduce your research experience Introduce your college life Can you introduce your graduate program What do you think a qualified graduate student looks like Why choose our school Why do you want to take the postgraduate entrance examination The book you like Can you introduce your major Can you introduce your school Can you introduce your major Can you introduce your hometown
自我介绍
Good afternoon, teachers!
It is my honor to participate in this interview. My name is XX, 21 years old. I'm currently studying Network Engineering at the School of Software, Henan University.
During my undergraduate studies, I remained dedicated to my academics, achieving a GPA of 3.35. I was awarded the Henan University Scholarship and was recognized as a Merit (marryed) Student at Henan University. Additionally, I won the National Second Prize in the Chinese Collegiate Computing Competition.
In terms of personality, I consider myself an outgoing, positive, and hardworking person.
That concludes my self-introduction. Thank you for your time and attention!
专业词汇
retrieve augment generation
hallucination
Multilayer Perceptron
介绍缺点
My weakness is that I am not very good at time management. Sometimes, I pursue perfection too much, which makes it difficult for me to balance deadlines. I am constantly improving myself now.
你有什么兴趣爱好&你喜欢听什么歌曲&喜欢什么歌手
In my spare time, I enjoy listening to music, especially R&B songs, it helps me relax.My favorite singer is DT. quicksand
介绍一下你的家乡
My hometown, Anyang, is an ancient (enshente) city in China, known for oracle bone inscriptions and the Yin Ruins. It’s also home to the Red Flag Canal. With rich history and beautiful nature like Taihang Grand Canyon, Anyang’s spirit inspires me in my studies and research.
介绍一下你的学校&介绍一下你的专业
My university is Henan University, located in Kaifeng City,founded in 1912(nineteen twelve). although it is not a famous university,the learning atmosphere and campus environment are both very good. The teachers are very patient with students, students also encourage and help each other in study.
你准备报哪个方向 Which direction are you planning to choose
I would choose the direction of Intelligent Networks and Systems because I think it's similar to my undergraduate studies and graduation thises.
介绍一下你的专业
When I first used a computer, I became interested in how computers can access other computers, so I chose to major in Network Engineering. It not only has basic computer courses, but also some network related courses, such as network application programming and network information security technology
你喜欢的一本书
My favorite book is CSAPP, also known as "Computer Systems: A Programmer's Perspective", because when I was a freshman, I was also a newcomer in the field of computer science. This book helped me build a soild foundation for the computer field.It sparked my interest in computers
为什么选择我们学校&为什么你要考研
Because I am very interested in computer science, especially after studying computer related courses in my undergraduate studies, but I found that I still need to continue learning both in theory ˈ[θiːəri]and practice. Fudan University has a profound foundation in the field of computer science, and I believe I can further enhance myself here.
介绍一下你的研究生规划
In the first year, I will focus on professional courses(扣儿撒斯), reading paper, and building a solid foundation. In the second year, I will engage in research practice to enhance my research capabilities. In the third year, I will concentrate on my research topic, write high-quality Graduation thesis.
你认为一个合格的研究生是什么样的
I believe that a qualified graduate student has strong self-learning abilities, can quickly adapt to new environments, and has clear plans for the future
介绍你的大学生活
In my college life, I focused on learning professional knowledge such as operating systems, computer networks, etc [et ˈset(ə)rə] . At the same time, I joined technical clubs and was a technical director, this experience improve my professional and communication skills.
介绍一下你的竞赛&介绍一下你的毕业设计&科研经历
My graduation project was optimized based on my competition, and I conducted more detailed comparative experiments on it in order to obtain more accurate and reliable results.
My [Graduation thesis / competition project / research experience] is Design and Implementation of Real Time Intrusion Detection System Based on eBPF and Neural Network. The core mechanism (mykenezangmu)is to embed the inference process of neural networks into the kernel state to accelerate the intrusion detection process。
ebpf:Dynamically program the kernel for efficient networking, observability, tracing, and security
I compared SVM, DT,NN_int8,NN_int32, The result is that the NN_int32 I designed has the best effect. NN_int32 is that quantize the model parameter type from float to 32-bit int, times the original parameter by the hyperparameter S, then takes the integer to obtain the finally parameter.
面临的最大困难怎么解决
when i want to embed the NN into kernel, i found that ebpf has some
当我想要将神经网络嵌入内核态时,我发现ebpf存在512KB栈空间限制以及1M指令数限制。所以我做了多轮对比实验,包括内存占用,推理速度,推理精确度等,最后选择了NN_int32模型。
When I wanted to embed the neural network into kernel state, I found that ebpf has a 512KB stack space limit and a 1M instruction limit. So I conducted multiple rounds of comparative experiments, including memory usage, inference speed, inference accuracy, etc., and finally chose the NN_int32 model.
应急回答
i am sorry , i didn't hear that clearly. May i ask you to repeat it, please?
TODO
你学的最好的一门课
复习408
分布式理论。
未来规划
方向相关的知识:如大数据,网安(计网)
了解研究方向
了解linux网络内核栈
SDN 中断 probe RDMA
毕设实际性能问题
数据漂移(Data Drift):入侵检测的过时数据。
数据漂移指的是模型输入数据的统计特性随时间发生变化。这种变化可能是由于数据的分布、范围或频率的变化导致的。例如,如果一个模型是基于某个特定时间段内收集的数据训练的,而随着时间的推移,输入数据的分布发生了变化,这可能会导致模型性能下降。数据漂移通常关注输入特征的变化,而不直接关注模型输出或目标变量的变化。
概念漂移(Concept Drift):口罩
概念漂移是指模型的输入数据与目标变量之间的关系发生变化。即使输入数据的分布保持不变,如果输入数据与目标变量之间的关联性发生了变化,也会导致概念漂移。例如,用户的行为模式可能随时间改变,导致之前有效的预测模型不再适用。概念漂移强调的是输入数据和输出目标之间的关系变化。
隐写:010 Editor
图片隐写:末尾,高度,LSB隐写(最后一位加一),多个图片最后,拼接,改后缀
复试题目
英语
自我介绍、介绍一下你的本科学校、为什么选择报考我们学校、在感受到压力时如何解压
面试
栈溢出
栈相较于堆访问和写快,为什么。追问:现代系统堆为什么读和栈差不多
机试
项目
ip包长度,分片
cookies
机试题目
2025年复旦大学机试真题,网上分享的,由于都是回忆版,可能出现错误,所以要结合着看,至于数据范围是真的记不清楚了,只记得暴力是远远不够的,应该能拿25%的分数。
1.计算
考察if-else和浮点数计算
2.螺旋数组
给n和m,对于n*m的螺旋矩阵,给n个询问i,j,求g[i][j]的值
n和m最大1e9
3.安排课程
学院需安排课程,每门课程有开始时间、结束时间和人数:
- 人数>20:必须使用大教室。
- 人数≤20:可用小教室或大教室。
- 动态调整:对于范围[l,r]的课程,我们可以将其分为[l,x]和[x,r]两部分时间安排,x属于[l,r]。例如若小班正在使用大教室,当需要安排新大班时,可申请小教室将小班转移,腾出大教室供大班使用。
目标:
- 最少的教室总数(大教室+小教室)。
- 在满足最少教室总数的前提下,最少需要多少间大教室。
4.回文串
求最长回文子序列,不仅要求长度,还要求这个子序列
5.树染色
加上对一个节点和它的子孙节点染色。
解析
此解析未经证实,仅供参考。
1: 螺旋矩阵
按照圈数来考虑:若n = m 此时对于任意相邻的两圈,外圈所包含元素数量一定比内圈所包含元素数量多8,因此圈与圈的元素数量就形成了一个等差为8的等差数列 对于询问i, j位置上的元素是几,首先判断i,j位于第几圈(假设最外圈是第一圈)圈数id = min((min(i, j) ) , n - max(i, j)), 此时id - 1圈的所有元素数量之和就可以通过等差数列求和求出来,也就是说我们可以知道第id圈的元素的起始元素的值, 然后判断i, j位于该圈的第几个元素上,最后将起始位置和这个值相加即可
若n != m此时就要考虑圈数与n,m的大小关系,如果圈数大于min(n, m) / 2就意味着此时相邻圈数的差值变成了4, 因此要先找出在第x圈时,这个公差会改变,若i,j位于圈数小于x则重复n = m的操作,反之将上述操作的公差8改为4重复
2: 最长回文子序列 区间dp dp[][]表示区间ij内最长的回文序列的长度 for(int len; len <= n; len ++ ) {//区间长度 for(int i = 1; i <= n - len + 1; i ++ ) {//区间起始点 int j = i + len - 1; if(len == 1) dp[i][j] = 1; else { dp[i][j] = max(dp[i + 1][j], dp[i][j - 1]); if(s[i] == s[j]) dp[i][j] = dp[i + 1][j - 1] + 2; } } }
此时求出了最长的数量cnt 再次dp pair<int, int> way[][]记录ij是由哪个状态转移来的 for(int len; len <= n; len ++ ) {//区间长度 for(int i = 1; i <= n - len + 1; i ++ ) {//区间起始点 int j = i + len - 1; if(len == 1) dp[i][j] = 1; else { dp[i][j] = max(dp[i + 1][j], dp[i][j - 1]);//如果dp[i + 1][j]大,就把way[i][j] = {i + 1, j};反之亦然 if(s[i] == s[j]) dp[i][j] = dp[i + 1][j - 1] + 2; //如果这个条件存在,那么dp[i + 1][j - 1] + 2一定比上面写的那俩大,也是为什么这里不加max的原因,所以如果出现这个条件,直接way[i][j] = {i + 1, j - 1} } if(dp[i][j] == cnt) {//如果等于最长长度 endi = i, endj = j; break;//这个break要把两层for都break掉,具体实现不写了 } } }
然后就是想办法输出,所有状态都是由len = 1转移来的,因此输出串的时候endi == endj就是结束条件, 此外, dp[i][j] = dp[i + 1][j - 1] + 2只有这个转移实质上对答案做出了贡献, 因此在找出答案时,倘若s[endi] == s[endj]就把这俩字符加入答案中,可以考虑用队列存,因为回文串要往两头加 while(endi != endj) { int tmpi = endi, tmpj = endj; endi = way[tmpi][tmpj].first; ...j = way....second; 如果(s[i] == s[j]) 加入.. } 此外,如果cnt是奇数,那么最后endi == endj时也要吧s[endi]加入 这是正确答案吗?显然不是,因为这个回文串是反过来的,因为这样操作先加到队列里的是最两端的, 考虑到回文串的性质,其实我们在加入答案时只添加一半(例如只添加s[endi]),最后倒着输出就是答案回文串的一边了
复试经验贴
复旦大学软件学院2025年全日制硕士研究生招生复试工作实施细则
复旦大学软件学院2025年全日制硕士研究生招生考试进入复试考生名单
复旦大学2025年拟录取硕士研究生名单(不含推荐免试硕士生)公示
复旦大学软件学院2025年招生63人,本人初试成绩第63名,复试成绩第4名,最终总成绩19名,复试帮助我成功逆袭上岸。由于复旦初复试为5:5,所以复试是相当重要的。
复旦的复试分为三天,第一天英语面试,第二天机试,第三天是面试。计院和软院的复试是分开的,但是软院的导师和实验室时计院的子集,所以直接看计院的方向即可。初试报名的方向是不算数的,需要在面试前重新选择方向(实时选择)。
分数占比为1:3:6,由于面试主观因素较多,所以机试必须保证能在平均水平。
复试流水账
下面我用流水线的方式带大家过一下我的复试流程,感受一下准备复试的心态以及博弈,不同的复试小组场合可能不一样,仅供参考。
二月二十四号上午10点出分,一般来说出分后会建立一个小群,在大群中通过准考证号进入复试小群。小群中会给出录分网站,这个网站是学长自己做的,经过多年的传播,录分网站已经可以做到十分收敛。同时小群中会有学长发布实验室的招生信息,用于提前面试。
如果你本科以前明确了研究方向或者毕设、项目和某个方向十分相关,建议提前联系实验室进行面试,会大大的增加面试通过的概率。但是听过一种情况,有的老师会养鱼,导致最后的报录比爆炸,例如大数据,智软等(不过这个每年都不一定,很难预测)
这段时间是非常挣扎的,尤其对于我这种双非低分仔,每天一边刷新录分网站看着自己排名下降,害怕自己掉出去,一边在纠结自己要不要联系老师,感觉自己什么都还没准备好。
三月三号联系了一个智软的一个老师(因为我本科做的大部分是开发工作),看上去老师对我兴趣还可以,把我推到了手底下的一个小导里,但是后面就卡住不动了。到后面选方向发现智软报录比炸了,才明白在养鱼。
后面又陆续联系了几个老师,都是已读不回,于是放弃了,专心准备。认真准备了我的毕业设计作为我的科研经历,最后在面试中为我立下了大功。也对ai和408做了大量的总结,不断的巩固知识点。同时专心的刷代码随想录和往年真题,练习完整输入输出格式。
三月十八号晚上,复试名单出来了,当时看复试名单找自己名字时心率直接爆了,找到自己的名字激动的要死,知道机会来了。
第二天发邮件通知复试时间以及复试联络员微信。这时就要在网上订宾馆,买车票,复试两天在江湾一天在邯郸,可以看价格酌情考虑,其实定在哪个校区都可以,只要在地铁旁就好,两个校区地铁通勤就二十分钟左右吧。同时也要关注复试细则,看看今年复试有没有什么新的变化。
同时这段时间是准备英语面试的黄金时间,前面一段时间不准备都可以,这段时间一定要投入一定的时间。
三月二十四号下午一点进行了英语面试,记得要拿好材料,进校园都是通过安保那边刷身份证进入。联络员会提前通知你的考试时间和地点,建议可以早点去,避免迷路。到那里可以找到一个拿着表的管理员,可以过去看看到几号了,其余时间要么再复习一下要么就是平一下心态,管理员会叫你拍照交材料,那就快到你了,到你的时候建议把手机放在外面以防万一。我进去的时候有三个人,一个在侧面用笔记本电脑,两个坐在对面,不过只有一个人在提问。看样子提问的可能是本专业的学姐,用的是中式英语口音,我问到的都是准备过的内容,所以倒也还好。听说有的问道专业知识和项目了,所以都要准备。
三月二十四号晚上就要选方向,联络员也会提前将信息告诉你,登入网站后,每年一般来说可能会多出几个方向或者少几个方向,这时就是勇者的游戏。例如软院的ai方向,往年根本没有这个方向,先开始根本没人敢报,直到最后也只是招8个报了9个还是10个。
由于我发现群里提前联系智软的人很多,要么初试分很高,要么9本,再加上感觉我的毕设(网络相关)是我的优势,所以我就准备跳车网安。临近面试前一天,我还给网安的老师发了邮件,不过没有回(也可能时间太紧了,老师也要避嫌)。
这个系统有两个志愿,一般来说第二个志愿不会起作用,只有当复试后第二志愿的第一志愿名额缺额时才可能有效。
一开放系统,我就直接锁了网管(为啥网安里锁了网管呢,纯粹是觉得这个方向名字难听,估计别人不想报),我是整个软院第一个报名的,表现出一种已经联系好了老师的样子(纯粹狐假虎威),后面网管报名人数就一直在3、4徘徊,最后落定在了4人。
三月二十五号下午进行了机试,也是建议提前去。我的机试地点时邯郸元创楼,那里的机房超级拥挤,桌子也比较小。临近机试这几天,重点看代码随想录的DP,图,树,贪心相关的题目,在机试考试前几个小时,我重点看了一道DP,结果就考到了。
今年的OJ还是可以的,有在线的vscode,由于我都是printf打印调试,所以对这个不在乎。注意在考试时,你的评测是有频率限制的,今年是一分钟三次好像。系统上的ac仅仅表示你的样例都对了,但不代表你最后的分数,甚至有可能只有很少的分数。机试是完整输入输出形式,不是leetcode的核心代码形式。但是数据范围给的很详细,25%/50%/75%/100%的数据是多大数据,都会给你,看样子就是帮助你尽量拿分。
到后面注意要记一下题目,出来考场就记在手机里,第一时间问有ICPC经验的人或者问大模型,把正确答案的原理搞懂,写对的题看能不能拓展,因为面试时必问你的机试。
当天晚上联络员就会把你的面试时间和面试地点发给你。
三月二十七号进行了面试,也是建议早点到,叉二中间有座椅和沙发可以复习。建议打印资料把个人简历,个人陈述,成绩单订成一份,多打印几份。进去之后有一圈老师,一份一份的递给老师,然后开始进行自我介绍,这时老师看你的资料。然后就是对你进行提问,基本就是十五分钟左右。当时我前面的人面试了20多分钟,但是我就是准时准点的15分钟,出来我以为完蛋了,最后复试成绩第四。所以面试时间不具备参考价值,只要好好发挥就可以。
后面就结束了,上午面试完下午我就滚蛋了,当时觉得寄了,只想早点离开这个令我苦逼的城市,当时实习报告和毕业论文进度为零,压力暴大。
复试准备
提前联系导师
这一part没有什么能说的,对于本身bg比较好的,建议可以提前联系几个老师,小群里面会有学长发招生信息,或者直接去官网给老师发邮件。对于bg较差(像我这种双非低分)的同学,可以尝试少联系几个,没必要投入太多时间,还是把时间多多的投入在实力的提升上面。
英语面试
英语面试不建议提前投入过多时间,建议在临近一周的时候开始准备,一般来说拉不开分。本人无任何口语听力训练,感觉复旦口语考试也还可以,不会出听不懂的题目。
首先要去准备自我介绍和最基础的问题,在此基础上再去准备高级一点的问题。最基础的问题就是介绍本科、家乡,为什么报考我们学校,怎么放松等等。
这里的高级问题是什么意思呢?由于你进去时是什么都不带的,所以口语老师只能从你的自我介绍来了解你。于是高级问题就分为两点:一是基础408知识(我了解有问dfs的),二是你在自我介绍中提到的竞赛,论文等(我了解有问数学建模,自己的项目)。
由于我感觉英语面试主要是看你的英语听力和口语水平(大概够用就行),所以我的自我介绍中只简单的提到了我获得过一个国二,并没有展开说。以防展开说后问道一些专业术语忘记,以及可能出现的各种语法错误。
具体准备时一定要张开嘴说,我常用的一个联系方法是先自我介绍(计时一分钟),然后自问自答,也就是自己对自己的自我介绍进行提问,包括一些基础问题和高级一点的问题,或者用大模型也是不错的选择。
进到考场考试时,尽量不要冷场,不管怎样一定要说出来,没听懂可以重复或者申请换题等。表现的自然一点,就把面试官想象为学长学姐,正常聊天而已。
上机测试
2024机试题目(群友回忆版):
24年第一题是签到题,记不住了,反正白给的,三分钟的代码量
第二题是leetcode718,O(n^3)70分,动态规划O(n^2)就可以100分
第三题是求矩阵乘法,题目描述是两个 n*n 的稀疏矩阵,每个矩阵只有n个非0值,输入格式是第一个矩阵的 n 个数格式为n行 i j a,表示 i 行 j 列有个非 0 数 a。然后是n个第二个矩阵的数。要求给出矩阵乘法的结果,只给出所有不为0的结果。其中输入输出的这个 i j 都是要求按照 i j 的升序排列(i 小优先,i相等则 j 小排在前)。然后题目下面补充了一句输入n个数的位置足够随机。这句话是个坑,考场容易犯傻理解错然后做麻烦,去年很多死在这道题。这个随机不是说样例什么极端样例都有的意思(acm打多了很容易理解反),意思是就是数学上的足够随机、等概率,就是平均一行、平均一列就一个数的意思,因此这题标答就是在 A 的全部 i,j,B 的全部 k,l,构建 j==k 下的全部 (i,j,l) 三元组即可,就可以满分,因为这样的三元组很少。时间复杂度上,这题给分是 O(n^3) 给40分,O(n^2)给60分,O(n)给100分
第四题是字符串大模拟,中缀表达式求值,细节记不住了。下面范围说明给的非常细,样例点很细,从0分到100分都有可能,当然大部分人有bug其实往往可能整体会有大问题,大部分人一般会在0分附近
第五题是求最短路径条数,其实dijkstra就能做。然后数据范围很大,需要堆优化。也就是基本就相当于默写 dijkstra+堆优化 模板 =满分。O(v^2)好像40分吧,忘了。然后O(elogv)满分
机试建议从初试结束就立马开始准备,因为这是唯一一个只要你准备的够充分,分就不会低的考试,其他两个都带着一些主观因素。同时机试也影响着老师对你的第一印象,面试也会问你的机试。
机试题目建议是刷代码随想录+历年真题(考过原题),然后对一些重点题目在acwing上将其改为完整代码模式,熟悉IO。
机试的重点题是DP+树+图+贪心,到临近考试时,就要对重点题目和模板进行多次重复的刷题。在考试当天上午我想了一下,前几年考了两次回文子串,那么今年有没有可能改编一下,我看代码随想录有一道最长回文子序列,就记了一下,结果下午就考到了。所以历年真题需要深挖规律,不能轻视。
今年的机试题目相较于以前要难得多,如果说以前的题目像是从代码随想录抄的,那么今年就像是fdu的acm选手自己出的题目。所以进去考试不管题目有多难,一定要冷静,会的人总是少数,你要做的就是争取多拿一点分数。
专业面试
专业面试是重点中的重点,但也是不确定性因素最大的地方,关键在于没有考纲,我们不知道如何去准备。很多人就是蒙头瞎准备,根本没有自己的思考。就是听别人讲要准备ai项目,于是两个月就一直看那些苦逼的代码,最后一面试,发现根本没有老师提问,或者提问的都是自己没准备的角度。
我认为专业面试的可以分为两部分准备:
核心技能:简历(教育经历,项目,科研经历,实习,竞赛,专业技能)、408专业知识、初试分数、成绩单
非核心技能:临场表达(表达,神态)、面试技巧(主动拓展)
我认为如果你的核心技能够强,即使非核心技能欠缺一点也无妨,但如果你的核心技能稍有欠缺,非核心技能够帮助你狐假虎威,让你看起来很牛逼。
核心技能
首先针对简历,我的建议如下:
- 教育经历:大部分的信息你都已经无法改变,但是你可以尽量写对自己有利(高分六级,92本,一些三好学生和奖学金)的以及自己熟悉的主修课程。GPA怎么好看怎么写,排名或者rank选个好看的。
- 专业技能:写上自己在大学期间学过的专业技能,注意写上去的一定要熟悉。技巧是可以主动点出来该技能你掌握最熟悉的点,引导老师提问。
- 项目:这一部分就是写一些自己在本科期间做过的项目(玩具)。包括竞赛,大作业,自己找的开源项目,b站项目等等都可以。尽量选一些技术难度高一点的,不过老师一般都懂,本科生也大部分也做不出什么创新东西。尽量选择和自己所选方向相匹配的项目。技巧是对自己的项目进行分亮点、创新点描述,对每一点尽量使用数据说话。可以引入对比试验展现自己的科研基础能力。能使用英文专业名称不用中文专业名称,让简历看起来更专业。可以对重点关键词进行加粗,引导提问。
- 科研经历:这一part不强求,可以使用自己的毕设(如果是偏向研究的毕设),有论文更好,当然如果只有实验室打工的经验也可以写上去。但是要注意,写上去的一定要熟悉,务必不要弄虚作假。技巧和项目一样。
- 竞赛:这里有什么就写什么,如果有项目和科研经历,老师一般来说不会问这些东西。如果不是什么含金量很高的比赛,可写可不写,如果简历过于单薄可以写上凑字数。
- 实习:这一部分和和科研类似。
- 如何写一份好简历:首先声明,简历一遍是不可能写好的,简历是不断的修改得到的,可以自己不断的看,可以交给大模型看,可以交给别人看,总之要不断的打磨。我建议在超级简历上买一个永久会员(99),以后找工作也可以使用。简历核心:选一个较为清爽的版型、重点的模块要有、不能有错别字、专业术语必须用对、有重点表示以及段落而不是全文都凑在一起一坨等等。
而对于408专业知识,很多人在复试的时候忽视了,其实不是你不会,而只是你忘记了。但是复试时不建议再去翻王道书复习,我推荐将其看作找工作的八股文复习,推荐:小林coding。重点复习和自己方向相关的408知识,像网安就着重复习计算机网络和网络安全相关的知识。
像初试成绩和成绩单这两个方面,已经是无法改变的事实,如果有瘸腿的,首先准备一下怎么回答:为什么xx挂科、为什么xx考的低等问题,注意不要找借口,诚恳道歉认识到错误,表达未来发奋图强的信心即可。然后复试前看一下这科目的核心知识点即可。然后数学核心知识点还是建议看一下:像牛顿迭代法,泰勒展开,连续是否可导,秩,大数定理(举的这些例子都是曾经考过的)等。
这里我要提一点,很多人会想:我没有科研经历/竞赛...怎么办。我是这么理解这个事的,首先没有的东西大概率你是无法短时间内获得并且熟悉的,不如更加深入的了解你有的东西。其次我觉得面试是一个扣分的过程,不会因为你少了科研经历,你的满分就是90分,只有当问你简历上的问题/408时,你不熟悉,这才会扣分。但是如果你的简历过于单薄(连一个项目都写不上去),我觉得比别人分低一点也是没有什么疑问的吧。
非核心能力
这个能力对于参加过一些面试的人普遍较好掌握。面试就是这样,你如果没有参加过,第一次你大概率会较为紧张,发挥不出你本有的实力。但是经过很多轮的面试,你就会大概明白面试其实也就那样,就是让一个陌生人看你的简历并且你要帮助他了解你有多出色。这时候如何提升面试能力就是一个绕不开的话题。我在这里就简单提几点:
- 神态:我就是来和老师沟通交流的,不过度紧张。不去避免眼神接触,和老师进行眼神交流是尊重以及展现你的自信的方式。手不用过分拘谨,当你讲解的时候手可以稍微比划一下。注意脸自然的面带微笑,一些敬语该用就用上。
- 表达:可以略作思考,最好要分点回答,彰显自己的逻辑性。说话不要着急,不要过快,吐字清楚一点,很多人说话只顾着自己表达,根本没注意别人是否听懂了。
- 主动拓展:当一个老师提问问题时,你可以主动的拓展到更深或者更广的话题上(最好要会),引导老师问你,你如果回答出来了是大大加分的。我面试时就多次用到了这个技巧,有一个面试题是问我为什么栈的读写比堆快,我首先回答了一下,然后最后提了一嘴在现代操作系统中堆和栈读一般来说是差不多快的(这也是我偶然刷知乎看到的别人的测评),果然老师就问了为什么,这样就是很加分的。
具体联系可以通过自我面试(也就是自己问自己答的方式,最方便,要学会根据自己的简历问自己问题),大模型面试,如果能找别人帮忙面试会更好。和简历一样,只有通过不断的面试才能磨练自己的这些能力。
tips
- 对于项目/竞赛/科研,不要过于纠结代码。你要做的是:核心功能/模块的原理深入理解,整体功能的充分理解(也就是为什么,是什么,怎么好),背后知识点的熟练掌握。
- 永远不放弃,就算垫底也能逆袭。初试考的高也不轻视,防止翻车。
- 少听群里吹水,牛逼的人总是少数,大部分人都是普通人。