本章介绍了汇编语言的基础,讲解了机器级编程的概念
1. 程序编码
编译器基于编程语言的规则,目标机器的指令集和操作系统遵循的惯例,经过一些列的阶段生成机器代码。
假设有两个c文件p1.c 和p2.c,可以使用下面的命令编译为可执行文件
linux> gcc -Og -o p p1.c p2.c
gcc是linux默认的c语言编译器,-O是指定优化等级,-Og会生成符合原始c代码整体结构的代码的优化等级,另外还有更高级的优化等级(O1,O2)。
实际上gcc在编译过程中调用了一整套程序:
- 首先,c预处理器扩展源代码,插入所有
#include指定的文件,扩展所有#define声明的宏,生成两个源文件的汇编代码,称作p1.s和p2.s。 - 然后汇编器会将汇编代码转化成二进制目标代码文件,称作
p1.o和p2.o,但还没有填入全局值的地址。 - 最后,链接器将两个目标代码文件和库函数合并,并产生可执行文件,称作
p。
-o p :生成可执行文件p
-S:生成汇编代码
-c:生成二进制目标代码
在linux中可以使用下面的命令对一个可执行文件进行反编译,生成汇编代码。
linux> objdump -d p
1.1 机器级代码
对于机器级编程,有两种抽象很重要:
- 指令集架构(ISA)来定义机器级程序的格式和行为,它定义了处理器状态,指令的格式,以及每条指令对状态的影响。
- 机器级程序使用的内存是虚拟内存,提供的内存模型像是一个很大的字节数组
机器级代码中有很多处理器的状态都是可见的:
- 程序计数器(PC,在x86-64中以%rip表示),给出下一条指令在内存中的地址。
- 整数寄存器文件,包含16个64位的寄存器,有的用来记录某些重要的运行状态,有的用来保存临时数据(局部变量,返回值)。
- 条件码寄存器,保存着最近计算的状态信息,用来实现控制,或数据流的条件变化(if,while,for,switch)。
- 一组向量寄存器,用来存放多个正数或浮点数的值。
注意:程序的内存包括:程序的可执行的机器代码,操作系统需要的信息,用来管理过程调用和返回的栈,用户分配的内存块(malloc)。
1.2 数据格式
在x86-64中有以下术语:
| C声明 | Intel数据类型 | 汇编代码后缀 | 大小(字节) |
|---|---|---|---|
| char | 字节 | b | 1 |
| short | 字 | w | 2 |
| int | 双字 | l | 4 |
| long | 四字 | q | 8 |
| char* | 四字 | q | 8 |
| float | 单精度 | s | 4 |
| double | 双精度 | l | 8 |
由于浮点数使用的是一组完全不同的指令和寄存器,所以两个l不会有歧义。
2. 访问信息
一个x86-64的cpu中包含一组16个64位的通用目的寄存器

可以通过不同的指令访问到低4字节,低2字节,和最低的字节。当这些寄存器作为目标时,对于小于8个字节的命令,高位的字节会怎么改变呢?有两条规则:
- 生成1字节和2字节数字的指令会保证剩下的字节不变。
- 生成4字节的指令会把高位的4个字节值为零。
2.1 操作数指示符
大多数指令有一个或多个操作数,指示一个操作要使用的源数据以及放置结果的目的位置。
源数据可以以立即数(常数)给出,或从寄存器、内存中读出。结果可以存放在寄存器或内存中。
因此操作数可以分为三种类型,第一种是立即数,通常在前面加上$。第二种是寄存器,它表示寄存器中的值(任意指定低位1,2,4,8个字节)。第三种是内存引用,它表示内存中的值。以下的图更加清晰易懂。 
2.2 数据传输指令
最频繁使用的指令就是数据传输指令,mov指令把数据从源位置复制到目标位置,不做任何变化
根据操作数不同,有以下五种,其中内存复制到内存被认为是不安全的操作,不被允许 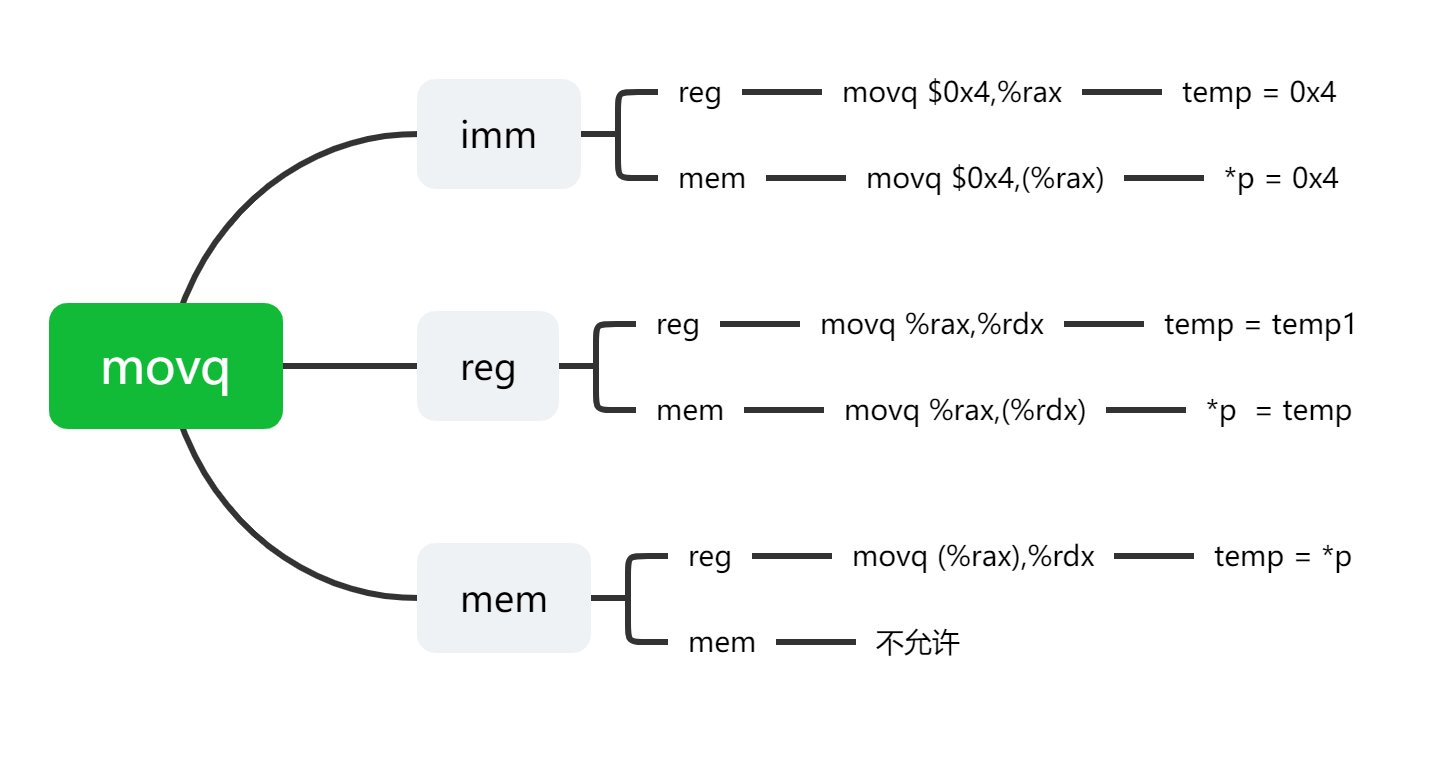
同时,根据数据类型的不同,可以分为
| MOV S,D | D<-S | 传送 |
|---|---|---|
| movb | 传送字节 | |
| movw | 传送字 | |
| movl | 传送二字 | |
| movq | 传送四字 |
对于从小到大的传输,又有两种分类:movz和movs,举例说明:
movzbq将做了零扩展的字节传输到四字,等等。movsbq将做了符号扩展的字节传输到四字,等等。具体见P123
2.3 压入或弹出栈数据
在x86-64中,栈存放在内存中的一个区域,栈是向下增长的,也就是地址不断减小,发生增加或删除的一端称为栈顶,有一个寄存器专门用来保存栈顶指针,称作%rsp。对于压栈入栈操作,有:pushq和popq。
pushq 将寄存器的值或立即数压入栈中,popq 将栈中的值存入寄存器中(由于内存到内存的操作时禁止的,所以不能直接写入内存中)
将一个四字压入栈中有两步:
- 将栈指针减去8
- 将值写入新的栈指针
注意,pop之后元素不会消失,而是等待下一次被覆盖。
3. 算术和逻辑操作
分为四组:加载有效地址,一元操作,二元操作,移位,具体见下图: 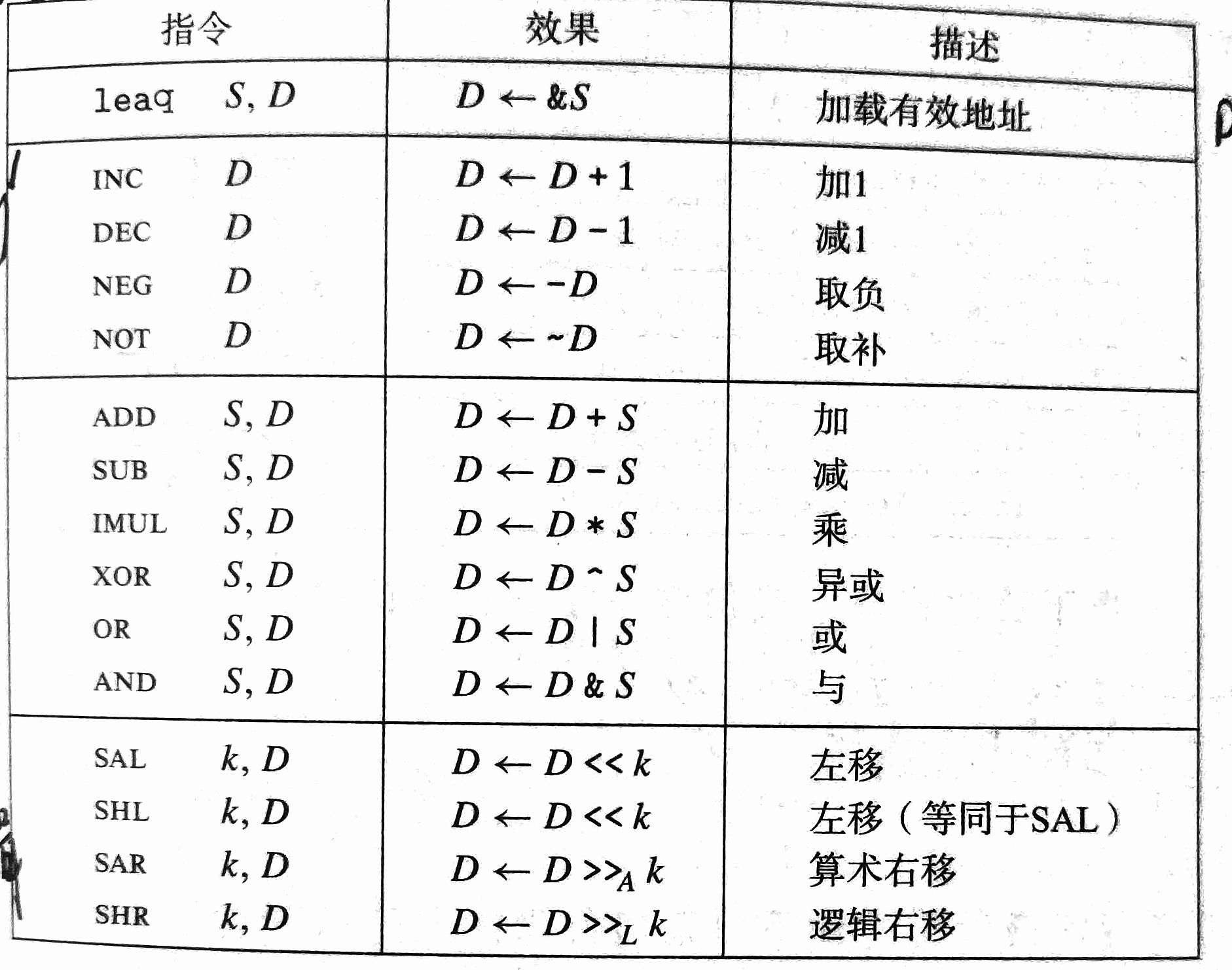
加载有效地址
它和
mov很相似,不过它不会去内存中加载数据,而是直接将计算结果存入目的地中,举例解释:设%rdx的值是x,则leaq 7(%rdx,%rdx,4),%rax就是将%rax的值设置为5x+7。当用于将有效地址写入目的数时,源操作数中存的就是地址,例如在c语言中使用&S取地址时会用到,详见过程调用中的栈上的局部存储一元操作和二元操作
包括一些加减乘,位操作等
- 移位操作
分为逻辑和算数移位
4. 控制
测试数据,然后根据测试的结果来改变控制流和数据流,这是机器代码实现有条件的行为。通过计算测试,将计算结果的一些特征(进位,零,符号,溢出)放入条件码寄存器,接着访问条件码,根据条件码,使用不同的jump指令实现条件判断。
4.1 条件码
在cpu中有一组单个位的条件码寄存器,它保留最近计算和逻辑操作的属性,包括
- CF:进位标志。最近的操作使最高位产生了进位,可以用来检查无符号操作的溢出。
- ZF:零标志。最近的操作得出结果位0。
- SF:符号标志。最近操作得到的结果为负数。
- OF:溢出标志。最近的操作导致补码正溢出或负溢出
除了算数和逻辑操作符可以设置条件码,还有两个指令cmp和test也可以设置
- cmp的行为和sub相同,但不会改变寄存器的值
- test和add行为相同,但不会改变寄存器的值
4.2 访问条件码
使用条件码的三种形式:
- 根据条件码多不同组合,将一个字节设置为0,1
- 根据条件码,程序可以条件的跳转到程序的某个其他部分
- 有条件的传送数据
这里讨论第一种情况,通常使用set指令,set的指令表如下: 
4.3 跳转指令
跳转指令可以使程序切换到一个全新的位置,这些跳转的目的地通常使用标签(label)来指明,下面是一段伪代码:
movq $0,%rax
jmp .L1
movq (%rax),%rdx
.L1:
popq %rdx
.L1是跳转的标签,程序会跳过jmp下面的一条指令,跳转到指定地址。
jmp跳转是无条件跳转:分为直接跳转和间接跳转,直接跳转即跳转目标是作为指令的一部分编码的,间接跳转级跳转目标是从寄存器或内存位置中读出来的。
下图是jump指令表: 
前面两个是无条件跳转,在c语言中类似goto,后面的是配合条件码实现有条件跳转,也就是条件码的第二种使用方式,下面举个例子:
cmpq %rsi,%rdi
jge .L1
inc %rdx
.L1:
popq %rdx
cmpq判断的结果存放在条件码中,jge通过条件码的组合,判断是否是大于等于,如果满足条件,就跳转。这就是基于条件控制来实现条件分支。
实现条件分支,还有一种方法,叫做条件传送,也就是条件码的第三种使用方式,大致意思是程序会将每一个分支中的程序都计算一边,将结果存放到不同的地方,最后根据条件进行数据传送(函数返回,数据复制等等),这样的性能会更好。
下图是条件传送指令表 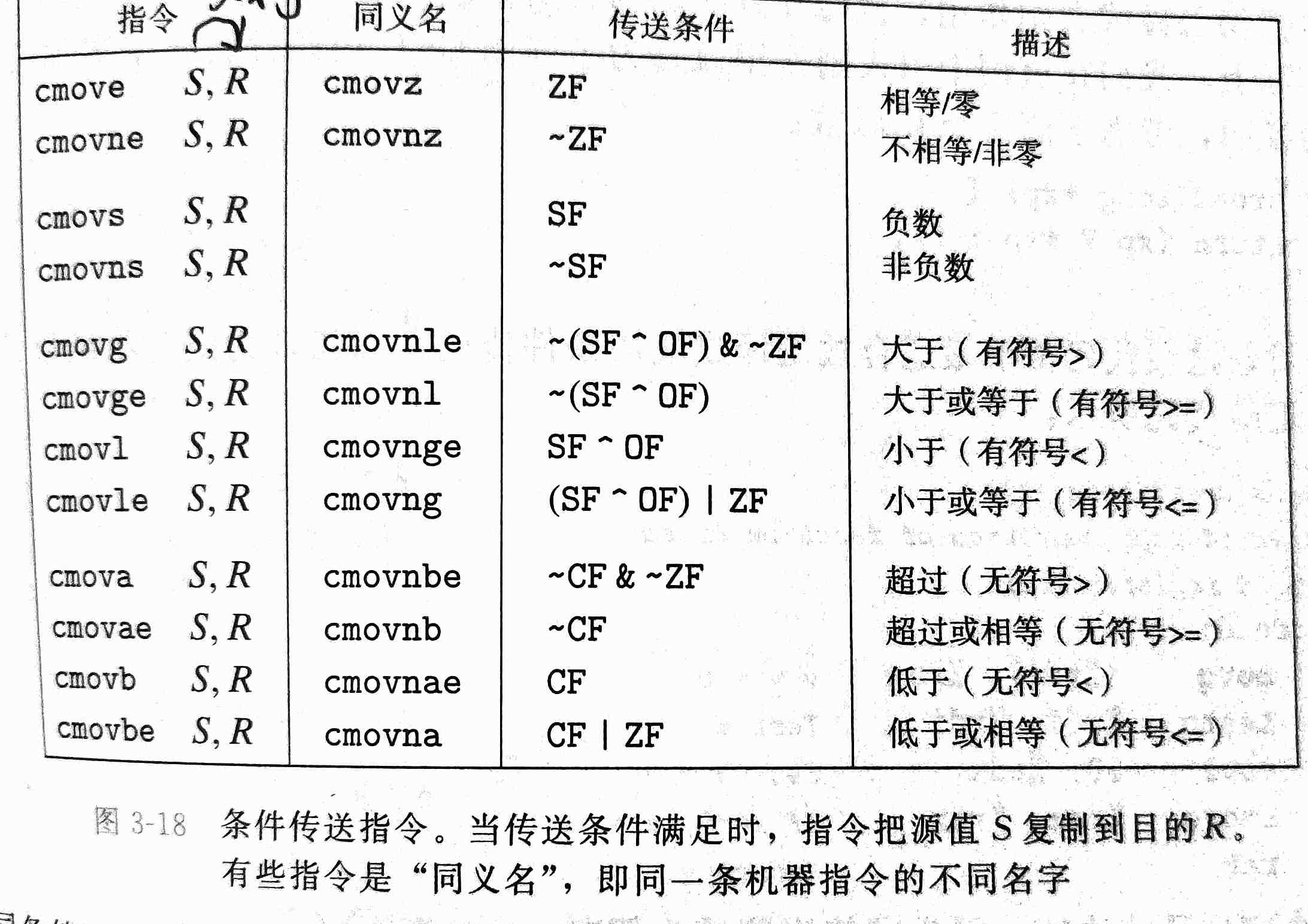
为什么性能会好呢?因为cpu有一种叫做流水线(pipelining)的工艺,一条指令会分成很多步,比如从内存中取出指令,确定指令类型,读数据,运算,写数据,更新PC等,在内存中取一条指令时,它会执行前一条指令的运算操作,要实现这个功能,就必须对条件分支进行预测,如果预测对了还好,预测错了它就会丢掉所有做错的指令,会导致性能严重下降。
但是使用条件传送有时会导致错误,如:
long cread(long *p){
return (p ? *p : 0);
}
created:
moveq (%rdi), %rax
testq %rdi, %rdi
movel $0, %edx
cmove %rdx, %rax
ret
这段代码本来是预防了空指针错误,但是由于编译器会都执行一边,导致出错。
条件传送也不一定会提高效率。如果在分支中存在大量的计算也会增加很多运行时间。
编译器会在安全性和性能方面都均衡考虑,选择最佳的编译方式。
4.4 循环和switch
在c语言中分为三种循环do-while、while、for,可以先学习do-while,然后进一步扩展到while和for。
4.4.1 do-while
do-while的c语言通用格式如下:
do
body-statement
while(test-expr)
这种通用形式可以翻译为如下的条件测试和goto语句:
loop:
body-statement
t = test-expr;
if (t)
goto loop;
其中逻辑已经可以使用汇编中的条件码和跳转指令来实现了。
.L2:
...
cmpq ...
jg .L2
jg可以换为其他的跳转指令。
4.4.2 while
while的通用语句如下:
while(test-expr)
body-statement
实现其的汇编代码有两种方式:jump to middle和guarded-do。
第一种策略是使用了do-while的模板,然后在最开始使用无条件跳转到测试处。下面是使用goto的实现:
goto test;
loop:
body-statement
test:
t = test-expr
if (t)
goto loop;
第二种策略也是使用do-while的模板,不同的是,会在最开始条件测试,它和循环种的测试是相同的,下面是goto的实现:
t = test-expr;
if (!t)
goto done;
loop:
body-statement
t = test-expr;
if(t)
goto test;
done:
第二种通常是在开启了较高的优化等级之后才会采用的策略。
4.4.3 for
for循环的通用语句如下:
for (init-expr; test-expr; update-expr)
body-statement
等同于:
init-expr:
while(test-expr){
body-statement
update-expr;
}
编译器会根据优化等级来选择while模板
4.4.5 switch
switch根据一个整数索引进行多重分支,在底层的实现是使用了一个叫做跳转表的数据结构。跳转表是一个数组,每个元素是一个代码段的地址。下面是一个伪代码:
注意104后没有加break,这会导致接着执行106的语句。
void switch_eg(long n)
{
switch(n){
case 101:
statement
break;
case 104:
statement
case 106:
statement
break;
default:
statement
}
}
编译出来的汇编(伪代码)
switch_eg:
subq $101, %rdi
cmpq $6, %rdi
ja .L2
jmp *.L4(,%rdi,8) ; 间接寻址
.L3:
...
jmp .L2
.L5:
...
jmp .L2
.L2:
...
跳转表(伪代码)
.section .rodata ; 只读数据
.aligen 8 ;
.L4:
.quad .L3
.quad .L6
.quad .L6
.quad .L6
.quad .L5
.quad .L6
.quad .L5
首先编译器会将n减去101,并且将n的取值映射正整数到0~5,创建一个新的变量。注意比较使用的是无符号ja指令,如果n是补码负数,则会转化变为非常大的无符号数,这样就可以只判断是否大于5。然后根据跳转表跳转到指定的代码块进行执行。
当case的数量很少(4个)时,编译器会编译为if-else结构,当范围大且稀疏时,使用if-else加上二分的方式.。