本文仅对kernel-bypass做一个简单的介绍,对其有个直觉。
C10M
在跨越了C10K的门槛后,不知不觉中就来到了C10M的门前,正如上面的文章所述:
The kernel isn’t the solution. The kernel is the problem.
面对规模为的Gbp/s数据流量,关键节点的挑战是用户态协议栈和多核并发问题。这个时候Linux 网络协议栈进行的各种优化策略,基本都没有太大效果。网络协议栈的冗长流程才是最主要的性能负担。
这时我们就要从硬件和操作系统下手了。
网络
绕过内核的网络协议栈,自定义处理数据。
- 将内核工作向上转移:DPDK
- 将内核工作向下沉淀:RDMA,XDP,eBPF
CPU
使用无锁并发代替加锁:构建一个高速公路架构而不是红绿灯的十字路口架构。
设计一个优秀的线程模型架构,更高程度上增大CPU的利用率,而不是单纯的等待。
让OS使用的核心和应用程序使用的核心分离,避免中断应用程序,绑定核心。
内存
绑定CPU,利用CPU的亲和性,减少高速缓存缺失的情况。
使用大内存页,降低页缺失的概率。 减少页的数量,增加快表命中率。
减少数据拷贝。
使用NUMA,加速内存访问(本地内存)。
压缩数据,使用高效内存结构。
kernel-bypass
中文名叫做内核旁路,顾名思义,就是在内核旁边开辟一条道路,不经过内核,将数据层的操作交由我们自己处理,内核只需要执行控制层的事情。
内核旁路有两类的技术代表:
- upload:使用 DPDK 技术,跳过内核协议栈,直接由用户态进程用轮询的方式,来处理网络请求。同时,再结合大页、CPU 绑定、内存对齐、流水线并发等多种机制,优化网络包 的处理效率。
- offload:使用内核自带的 XDP 技术,在网络包进入内核协议栈前,就对其进行处理,这样也可以实现很好的性能。使用网卡的RDMA技术,直接将数据放入远程主机的指定地址,或直接读取远程主机指定地址的数据。
DPDK
- 用户态模式的PMD驱动(Poll Mode Driver的缩写,即基于用户态的轮询机制的驱动),去除中断,避免内核态和用户态内存拷贝,减少系统开销,从而提升I/O吞吐能力
- 用户态有一个好处,一旦程序崩溃,不至于导致内核完蛋,带来更高的健壮性
- 针对NUMA系统,使用同一NUMA的本地内存
- 使用无锁的并发结构
- HugePage,通过更大的内存页(如1G内存页),减少TLB(Translation Lookaside Buffer,即快表) Miss,Miss对报文转发性能影响很大
- 多核设备上创建多线程,每个线程绑定到独立的物理核,减少线程调度的开销。同时每个线程对应着独立免锁队列,同样为了降低系统开销
- 向量指令集,提升CPU流水线效率,降低内存等待开销
- 内存池技术:DPDK 在用户空间实现了一套精巧的内存池技术,内核空间和用户空间的内存交互不进行拷贝,只做控制权转移。这样,当收发数据包时,就减少了内存拷贝的开销(mmap)。
- UIO(用户空间的 I/O):DPDK 能够绕过内核协议栈,本质上是得益于 UIO 技术,通过 UIO 能够拦截中断,并重设中断回调行为,从而绕过内核协议栈后续的处理流程。
传统的内核网络数据流程:
硬件中断--->取包分发至内核线程--->软件中断--->内核线程在协议栈中处理包--->处理完毕通知用户层
用户层收包-->网络层--->逻辑层--->业务层
DPDK网络数据流程:
硬件中断--->放弃中断流程
用户层通过设备映射取包--->进入用户层协议栈--->逻辑层--->业务层
RDMA
RDMA(英文全称:Remote Direct Memory Access),意思是远程直接内存访问,这种技术是一种最早应用于高性能计算领域的网络通讯协议,目前已在数据中心逐渐普及。RDMA允许用户程序绕过操作系统内核,直接和网卡交互进行网络通信,从而提供高带宽和极小时延。所以RDMA网卡的工作原理是,与传统的TCP/CP网卡相比,RDMA网卡省略了内核(CPU)的参与,所有数据的传输直接从应用程序到达网卡。
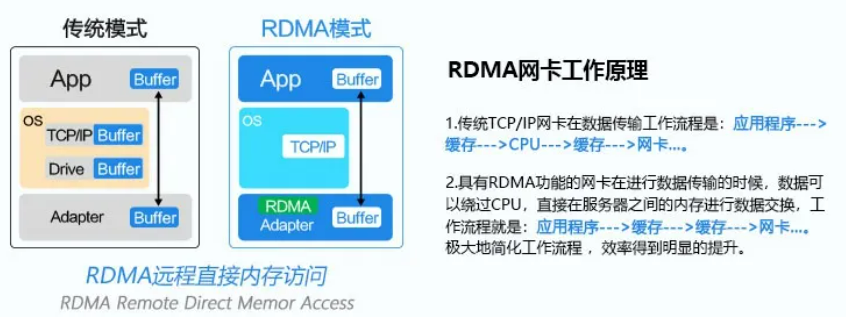
将可靠数据传输的协议栈交由网卡处理(硬件 offload)
减少数据拷贝与用户程序共用内存,减少数据拷贝。
XDP-eBPF
XDP全称eXpress Data Path,即快速数据路径,XDP是Linux网络处理流程中的一个eBPF钩子,能够挂载eBPF程序,它能够在网络数据包到达网卡驱动层时对其进行处理,具有非常优秀的数据面处理性能,打通了Linux网络处理的高速公路。XDP让灌入网卡的eBPF程序直接处理网络流,bypass掉内核,使用网卡NPU专门干这个事**。**