本章主要讲了虚拟化memory。
地址空间抽象
易用性、高性能、可靠性的目标。
早期系统
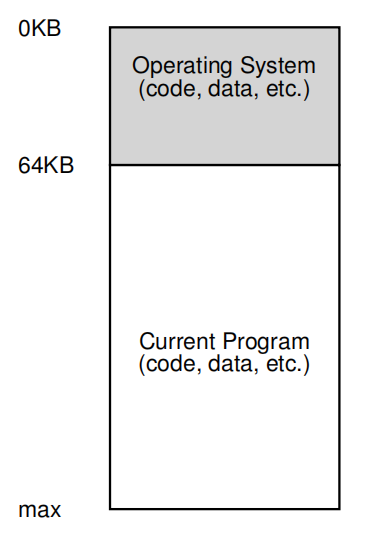
从内存角度,早期系统并没有为用户提供太多抽象。操作系统是一组例程(实际上是一个库),它存储在内存中(在本例中从物理地址0开始),并且将有一个正在运行的程序(进程)当前坐在物理内存中(在本例中从物理地址64k开始),并使用其余的内存。
多道程序以及分时共享
多道程序( Multiprogramming),即,多个进程可以在给定的时间运行,操作系统会在它们之间切换,例如,当一个进程决定执行I/O时。而分时共享在多道程序的基础上更加注重交互的领域。
分时系统和多道处理系统都存在时间分片,但是分时系统多了一个中断这一大杀器。
实现分时的一种方法是运行一个进程一段时间,给它完全访问所有内存,然后停止它,保存所有的状态到磁盘(包括所有的物理内存),加载其他进程的状态,运行一段时间,从而实现某种简单共享。
但是很明显,它很慢,每次切换都要对磁盘进行操作。所以我们希望在进程之间切换时将进程留在内存中,允许操作系统有效地实现时间共享。

但是现在允许多个程序同时驻留在内存中使保护(protection)成为一个重要问题。不希望进程能够读取,或者写入其他进程的内存。
地址空间
所以,操作系统需要创建一个易于使用(easy to use)的物理内存抽象。我们将这个抽象为地址空间(address space),它是系统中运行程序的内存视图。
进程的地址空间包含正在运行的程序的所有内存状态。例如,程序的代码(指令)必须存储在内存中的某个地方,因此它们就在地址空间中。该程序在运行时,使用一个堆栈来跟踪它在函数调用链中的位置,以及分配本地变量、传递参数和从例程返回值。最后,堆用于动态分配的、用户管理的内存。
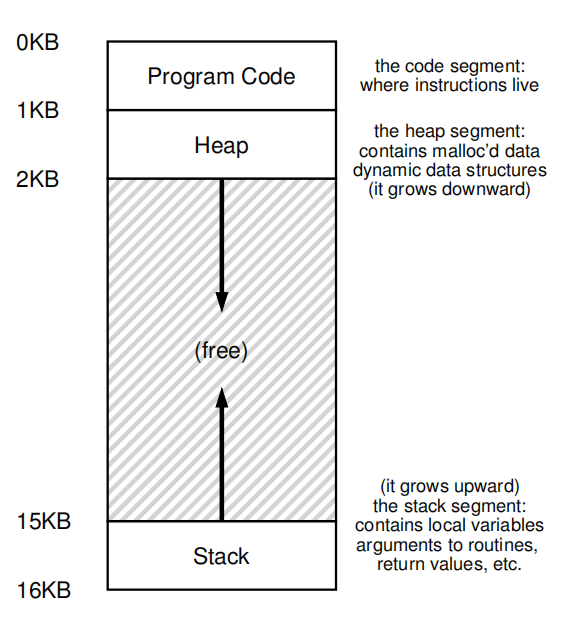
注意这里的0KB实际上是抽象地址,对应映射到的物理地址可能是上个图中的Process A、B、C,whatever。
当进程试图在地址0(虚拟地址 virtual address)处执行加载时,操作系统,结合一些硬件支持,将必须确保负载实际上不会去物理地址0,而是物理地址320KB,这是内存虚拟化的关键,并且是世界上所有现代计算机系统的基础。
隔离(Isolation)原则
隔离是建立可靠系统的关键原则。如果两个实体适当地相互隔离,这意味着一个实体可以失败而不影响另一个实体。操作系统努力将进程彼此隔离,并以这种方式防止其中一个进程伤害另一个进程。通过使用内存隔离,操作系统进一步确保运行的程序不会影响底层操作系统的操作。一些现代操作系统进一步隔离,将操作系统与其他操作系统隔离。因此,这种微核可能比典型的单片核设计提供更大的可靠性。
目标
虚拟地址的一个主要目标是透明(transparency),OS应该以运行的程序不可见的方式实现虚拟内存。因此,程序不应该意识到内存是虚拟化的事实。相反,程序的行为表现得好像它有自己的私有物理内存。在幕后,操作系统(和硬件)在许多不同的工作中完成多重内存的所有工作,因此实现了这种错觉。
虚拟地址的另一个目标是提高效率(efficiency)。OS应该努力使虚拟化尽可能高效,无论是在时间上还是在空间上(即对支持虚拟化所需的结构不使用太多的内存)。在实现高效的虚拟化时,OS将不得不依赖硬件支持。
最后一个目标是保护(protection)。OS应该保护进程彼此之间以及OS本身不受进程的影响。当一个进程执行加载、存储或指令读取时,它应该不能以任何方式访问或影响任何其他进程或OS本身的内存内容(即其地址空间之外的任何内容)。因此,保护使我们能够在进程之间传递隔离的特性。
地址转换
类似于虚拟化CPU,对于内存的虚拟化也需要硬件的支持。这里会使用一种可以被看作受限直接访问的补充,地址转换(address translation)。通过地址转换,硬件将每个内存操作(例如,指令获取、加载或存储)转换,将指令提供的虚拟地址更改为实际所在的物理地址。
然后OS通过管理内存(manage memory),跟踪哪些位置是空闲的,哪些位置正在使用,并明智地干预以保持对内存使用方式的控制。
在这里先提出一个假设:
- 用户的地址空间必须连续地放置在物理内存中。
- 地址空间的大小不能太大。具体来说,它小于物理内存的大小。(swap space)
- 每个地址空间的大小完全相同。
动态重定位
动态重定位(dynamic relocation)的实现:在每个CPU中需要两个硬件寄存器:一个称为重定位寄存器(基本寄存器 base register),另一个称为边界(有时称为限制寄存器 limit register)。这将允许我们将地址空间放置在物理内存中的任何位置,同时确保进程只能访问自己的地址空间。
一个基本寄存器用于将虚拟地址(由程序生成)转换为物理地址。边界(或限制)寄存器可确保这些地址在地址空间的范围内。如果进程生成的虚拟地址大于边界,或一个负地址,CPU将引发异常,进程可能会终止。它们结合在一起,提供了一个简单而高效的内存虚拟化。
下面是一个示例:
void func() {
int x;
x = x + 3;
}
128: movl 0x0(%ebx), %eax ; 将0+%rbx所在地址的值加载到eax
132: addl $0x03, %eax ; %eax的值加3
135: movl %eax, 0x0(%ebx) ; 将%eax的值重新加载如原来的地址中
在虚拟内存空间,静态代码被防止0地址处,而假设x的地址为15KB(也就意味着%ebx为15KB),x的值为3000

实际上在物理内存的位置
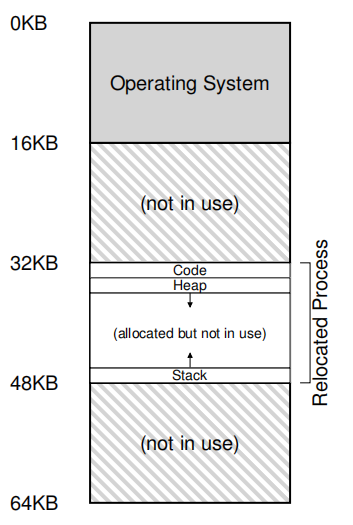
程序计数器(PC)设置为128;当硬件需要获取该指令时,首先将32 KB添加到基本寄存器值中,以获得物理地址32896;然后硬件从该物理地址获取指令。接下来,处理器开始执行该指令。然后在某个时刻,进程然后从虚拟地址15 KB发出负载,处理器获取并再次将其添加到基本寄存器(32 KB)中,获得最终的47 KB的物理地址,从而获得所需的内容。
通常把有助于地址转换的处理器部分称为内存管理单元(memory management unit)(MMU)。
OS支持
- 需要维护一个自由列表(free list),在进程创建时,为其在内存中寻找空间。
- 当一个进程被终止时,OS必须为其回收空间,设置free list。
- 当发生上下文切换时,必须要为当前进程保存base register和limit register,一般是保存到PCB(process control block),并且从PCB中取出新的值。
Segmentation
上面的形式有一个需要优化的地方,在堆和栈之间有一大块空白的空间。因此基于动态重定位的技术显得不是那么灵活。
广义边界
与其MMU只有一对base and bound,不如为地址空间的每一个逻辑单元都设置一对base and bound。在这里逻辑单元就是code、stack、heap。
物理空间:
| Segment | Base | Size |
|---|---|---|
| Code | 32K | 2K |
| Heap | 34K | 2K |
| Stack | 28K | 2K |
虚拟空间:
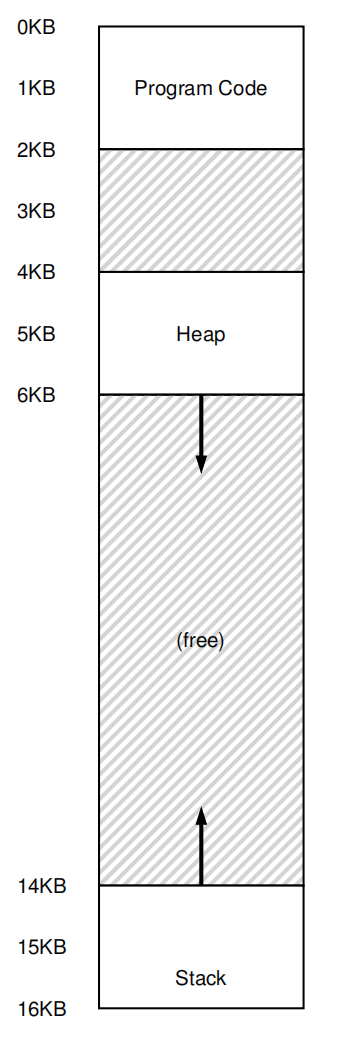
对于Code访问VM address 100:
100+32K=32868对于Heap地址访问VM address 4200:
4200 + 34K = 39016这是错误的,正确的是:4200 - 4K + 34K
所以一定要注意是Base+offset。
当访问超过Size限制的空间时,就会出现段错误(Segmentation fault)。
区分来源
硬件如何知道VM address是来自于哪一个segment呢?在这里可以使用前两位bit来区分。
对于VM address 4200:
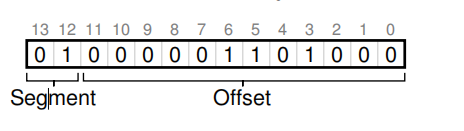
前两位为段标记,后面是对应偏移量。使用前两位01代表heap,而00代表代码段。
硬件还有其他方法来确定特定地址位于哪个段。在隐式方法中,硬件通过注意地址的如何形成来确定段。例如,如果该地址是从程序计数器生成的(即,它是一个指令获取),那么该地址在代码段内。如果地址是基于堆栈或基指针,它必须在堆栈段中;任何其他地址必须在堆中。
栈
对于栈,它的增长方向于其他两个相反,那么需要加入新的变量
| Segment | Base | Size | Grows Positive |
|---|---|---|---|
| Code | 32K | 2K | 1 |
| Heap | 34K | 2K | 1 |
| Stack | 28K | 2K | 0 |
对于访问15K:11 1100 0000 0000。通过前两位的11确定它是堆栈段。使用15K - 12K = 3K获取偏移量。由于它的Grows Positive为0,则3K -4K + 28K = 27K。
支持共享
对于现在的程序,代码共享(code sharing)是很常见的了,为了支持共享,需要一些额外的硬件支持,这就是保护位(protection bit)。为每个段增加了几个位,标识程序是否能够读写该段,或执行其中的代码。
| Segment | Base | Size | Grows Positive | Protection |
|---|---|---|---|---|
| Code | 32K | 2K | 1 | Read-Execute |
| Heap | 34K | 2K | 1 | Read-Write |
| Stack | 28K | 2K | 0 | Read-Write |
我们 可以将地址空间分成较大的、粗粒度的块,认为是粗粒度的(coarse-grained),但是,一些早期系统(如 Multics[CV65, DD68])更灵活,允许将地址空间划分为大量 较小的段,这被称为细粒度(fine-grained)分段。
OS支持
首先是在上下文切换时保存各个段寄存器。
其次的更为关键:管理物理内存的空闲空间。
有时会出现外部碎片问题(external fragmentation)。
一种解决方案是紧凑(compact)物理内存,重新安排原有的段。例如,操作系统先终止运行的进程,将它们的数据复制到连续的内存区域中去,改变它们的段寄存器 中的值,指向新的物理地址,从而得到了足够大的连续空闲空间。这样做,操作系统能让 新的内存分配请求成功。但是,内存紧凑成本很高,因为拷贝段是内存密集型的,一般会占用大量的处理器时间。
一种更简单的做法是利用空闲列表管理算法,试图保留大的内存块用于分配。
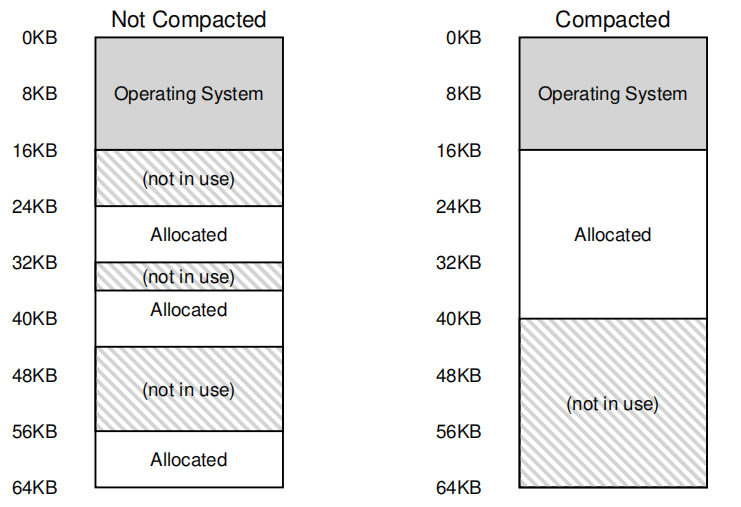
空闲空间管理
当分配的空间变为可变大小的单元组成时(malloc),就会发生外部碎片的问题。

假设
- 假设动态内存请求由malloc和free组成。
- 假设管理空闲空间的数据结构是一个列表。
- 当返回的内存大小大于请求的大小,无用的空间称之为内部碎片(internal fragmentation),这里只讨论外部碎片。
- 不会发生碎片整理(紧凑)。
- 每个内存区域的大小在它的生命周期内是不可变的。
底层机制
拆分与合并
对于上图,假设我们有一个空闲空间列表:
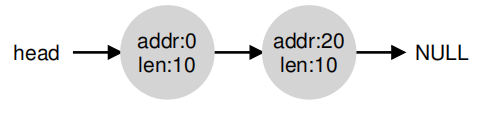
当请求大于10字节时,由于没有碎片管理,那么只能返回NULL。当大小等于10字节时,可以从两个空闲块中返回一个,当大小小于10字节时,只需选择一块进行拆分(split),返回即可,如下图:
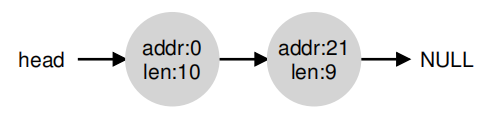
对于原始情况,如果10-19内存区域通过free被释放时,只是单纯的将其放入队列中,结果如下:

那么当大于10字节的请求发来时,我们将无法满足。所以,这里就要对内存块进行合并,当在内存中返回一个空闲块时,检查返回的块的地址以及附近的空闲空间块;如果新释放的空间位于一个(或两个)现有的自由块旁边,则将它们合并成一个更大的自由块,合并后如下图:
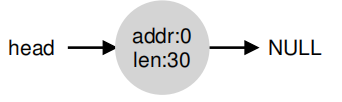
这实际上也是内存没有被分配的最原始的状态。
记录已分配区域的大小
注意free函数并没有指定释放空间大小,参数只有一个指针,实际上是在库中做了检查。通常会额外保存一个头部(header)信息。
例如:
ptr = malloc(20);
// 头部结构
typedef struct __header_t {
int size;
int magic;
} header_t;
void free(void *ptr) {
header_t *hptr = (void *)ptr - sizeof(header_t);
}
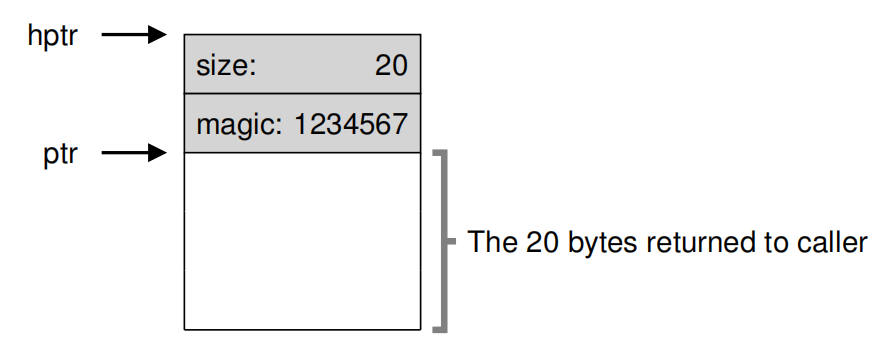
在释放时,通过当前的指针减去头部的大小,找到头部所在的地址,先去比较幻数(magic number)的值,作为非法检查。如果幻数相同就会将头部和使用内存一起释放。
空闲列表的构建
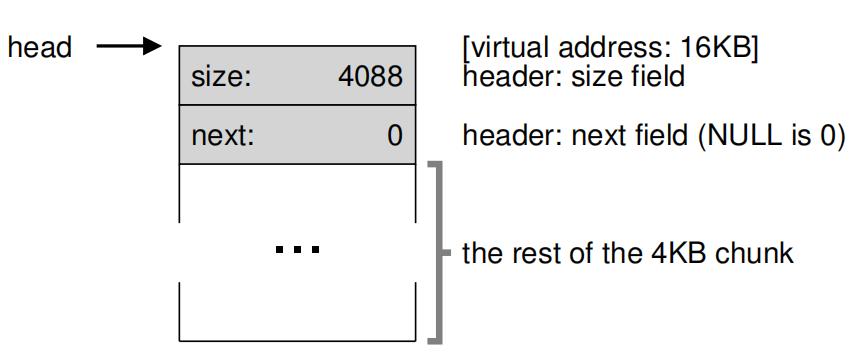
现在,假设由一个4KB大小的堆需要去管理,最初只有一个头部和空间,下面是对给空闲列表的节点描述:
// 头部目前只存size
typedef struct __node_t {
int size;
// 下一个节点地址
struct __node_t *next;
} node_t;
// 初始化操作
// mmap() returns a pointer to a chunk of free space
node_t *head = mmap(NULL, 4096, PROT_READ|PROT_WRITE,
MAP_ANON|MAP_PRIVATE, -1, 0);
head->size = 4096 - sizeof(node_t);
head->next = NULL;
最后得到如下图所示的内存结构,堆VM address起始为16KB:
现在需要分配100字节的空间,内存结构如下图:
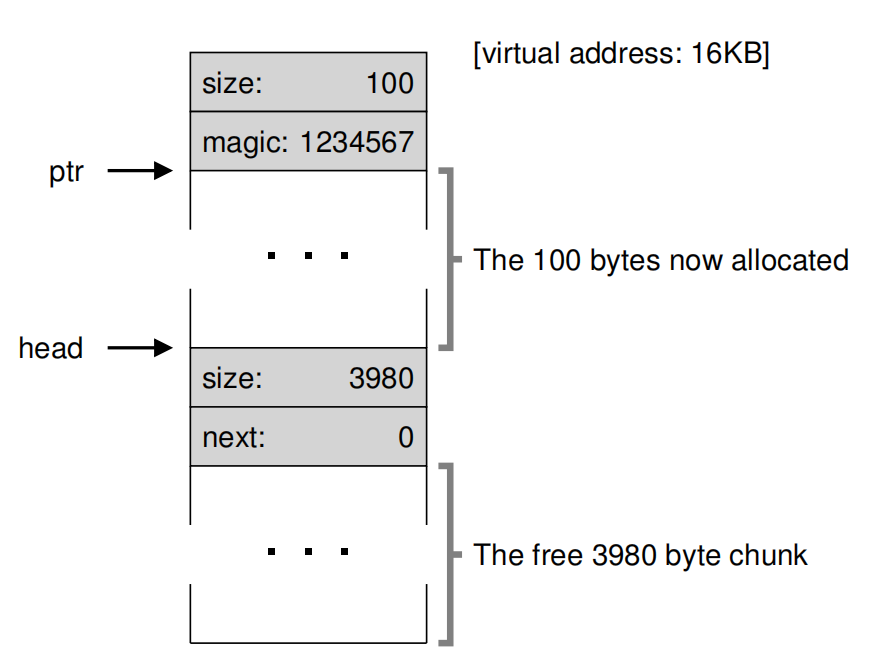
很明显:8 + 100 + 8 + 3980 = 4096 == 4KB。
接着再去分配两次,得到下图:
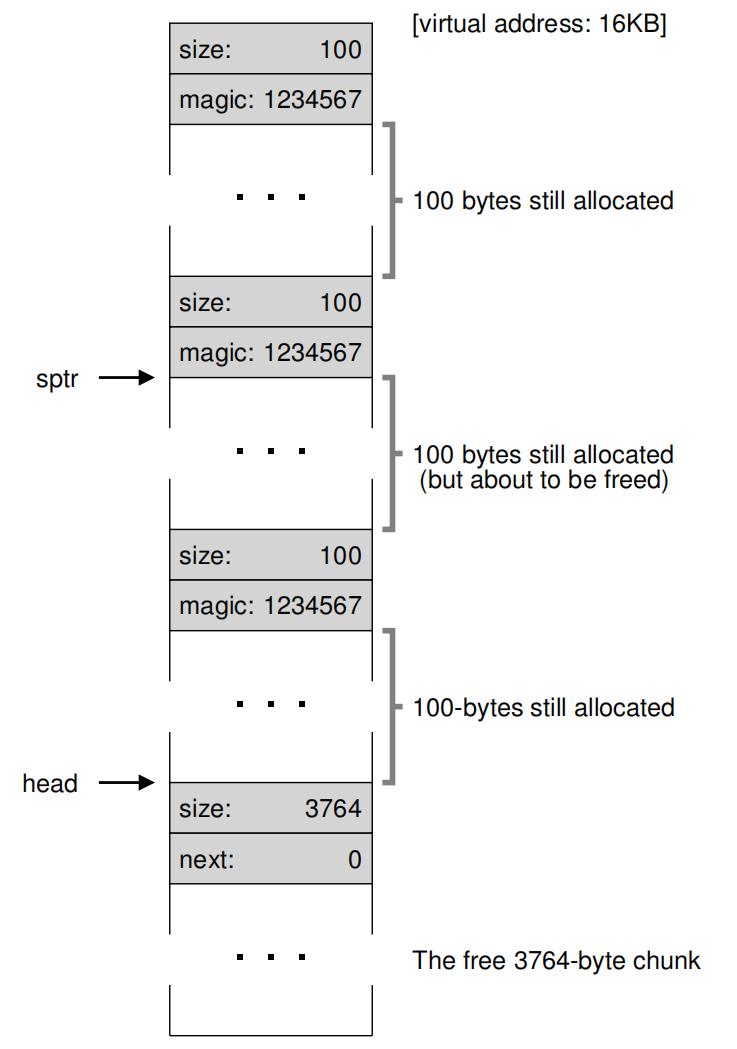
现在,需要释放16KB + 108 + 8 = 16500处内存,那么内存结构就如下图:
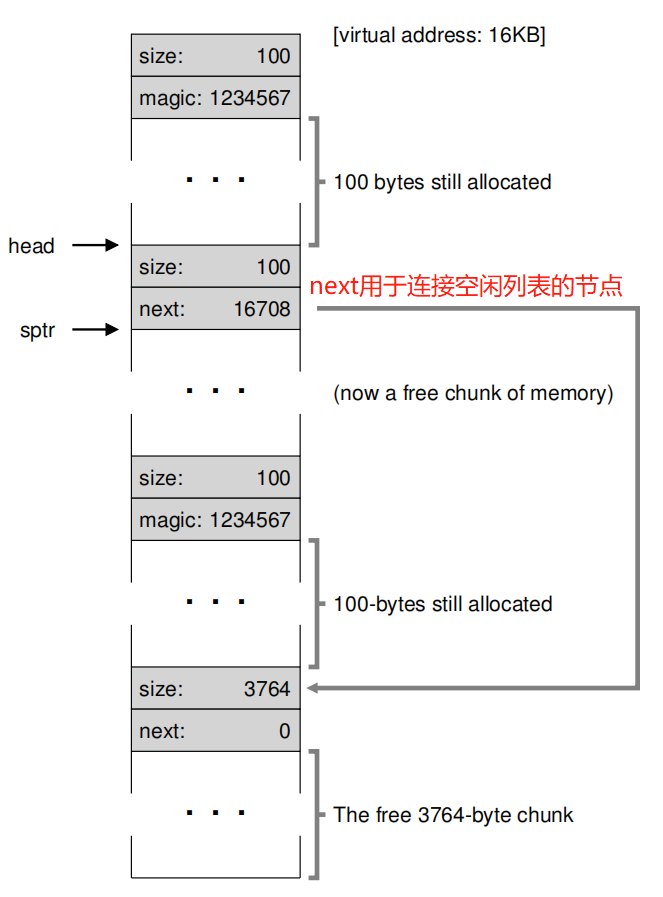
如果将剩下两个都释放,内存结构如下:
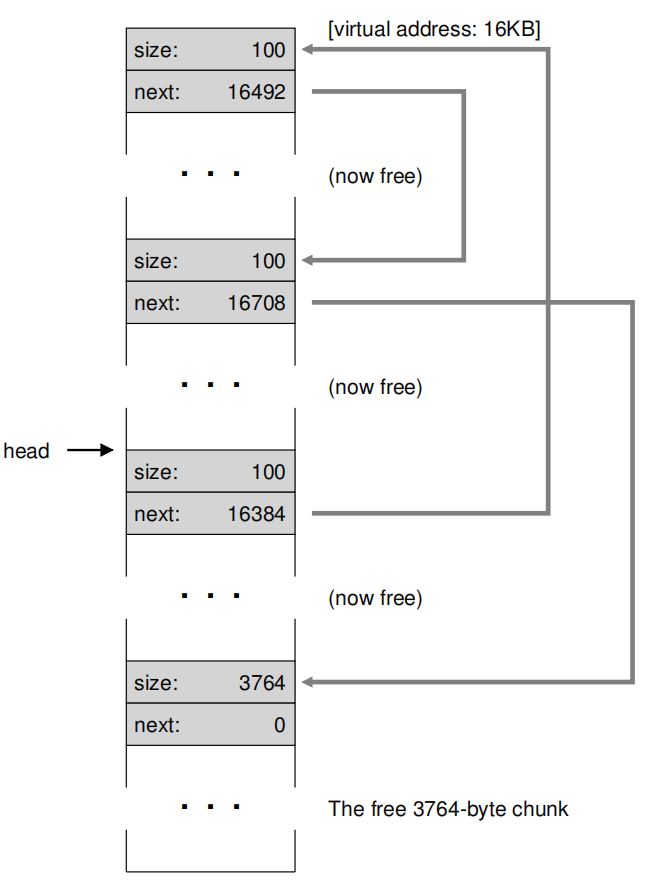
现在内存出现了很明显的外部碎片。这时候就需要去进行合并。
可变的堆
如果堆的空间耗尽,该怎么办?
- 最简单的方法就是要失败。在某些情况下,这是唯一的选择。
- 大多数传统的分配器从一个小的堆开始,然后在它们耗尽时向操作系统请求更多的内存。通常,这意味着他们会进行某种系统调用(例如,大多数UNIX系统中的sbrk)来增长堆,然后从那里分配新的块。
基本策略
在有了基本的机制保证后,这里提出几个基本的管理策略。
最佳匹配
Best Fit 首先找出所有大于等于请求大小的块,然后返回它们中的最小的块。
优点:
- 目的减少浪费空间,第一次找到的空闲分区是大小最接近待分配内存作业大小的。
缺点:
- 严重的性能损失。
- 产生大量难以利用的外部碎片。
最坏匹配
Worst Fit 和最佳匹配相反,返回最大的块。
优点:
- 效率高,分区查找方便;
缺点:
- 当小作业把大空闲分区分小了,那么,大作业就找不到合适的空闲区。
- 严重的性能损失。
首次适应算法
First Fit 一般是按照地址排序,只要找到第一个足够大的块就返回。
优点:
- 速度快,性能高,不需要穷尽搜索
- 为大作业在高地址留下了空间
缺点:
- 每次都是从头开始,会导致头部的碎片化严重
循环首次适应算法
Next Fit 会预留一个指针,记录上一次分配的地址,其他和First Fit相同。
优点:
- 性能高
- 分布均匀
缺点:
- 大作业有时很难被分配
其他的一些高级策略
Segregated Lists:隔离列表
if a particular application has one (or a few) popular-sized request that it makes, keep a separate list just to manage objects of that size; all other requests are forwarded to a more general memory allocator.
Buddy Allocation:预算分配
In such a system, free memory is first conceptually thought of as one big space of size 2 N . When a request for memory is made, the search for free space recursively divides free space by two until a block that is big enough to accommodate the request is found (and a further split into two would result in a space that is too small).
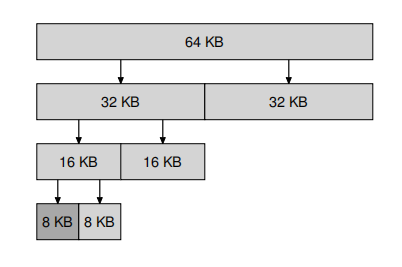
分页介绍
鉴于Segmetation不够灵活,同时碎片化又无法避免。在这里将空间不是按照逻辑进行分割而是分割为固定长度的大小每一页,在虚拟内存中,称之为分页(page)。把每一页称之为页帧(page frame)。
分页的优点:
- 灵活,通过完善的分页方法,操作系统能够高效地提供地址空间的抽象,不管进程如何使用地址空间。
- 能过更轻易的堆空闲空间进行管理。
为了记录地址空间的每个虚拟页放在物理内存中的位置,操作系统通常为每个进程保存一个数据结构,称为页表(page table)。
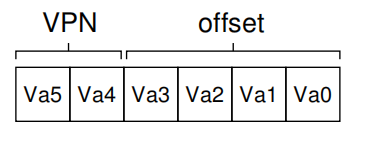
为了能够将虚拟地址翻译,这里将地址分为两个部分:页面号(virtual page number,VPN)和页内的偏移量(offset)。
下面是一个例子:
虚拟页面,64KB,分为4页,每页16KB:

物理页面:

很明显,这里的虚拟地址可以表示为下图:
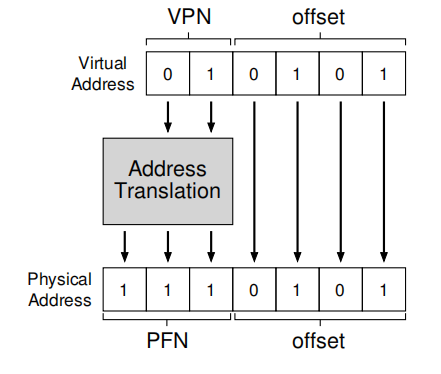
假设需要加载虚拟地址21的数据,转换过程如下:
对于32位甚至64位地址空间,页表可能变得非常大。一个典型的 32 位地址空间,带有 4KB 的页。这个虚拟地址分成 20 位的 VPN 和 12 位的偏移量,一个 20 位的 VPN 意味着,操作系统必须为每个进程管理 个地址转换(大约一百万)。假设每个页表格条目(PTE)需要 4 个字节,来保存物理地址转换和任何其他有用的东西,每个页表就需要巨大的 4MB 内存。
页表中的内容
- 有效位(valid bit) 通常用于指示特定地址转换是否有效。
- 保护位(protection bit),表明页是否可以读取、写入或执行。
- 存在位(present bit)表示该页是在物理存储器还是在磁盘上(即它已被换出,swapped out)。
- 参考位(reference bit,也被称为访问位,accessed bit)有时用于追踪页是否被访问。
- 脏位(dirty bit) 也很常见,表明页面被带入内存后是否被修改过。
下图显示了来自 x86 架构的示例页表项,它包含一个存在位(P),确定是否允 许写入该页面的读/写位(R/W) 确定用户模式进程是否可以访问该页面的用户/超级用户位 (U/S),有几位(PWT、PCD、PAT 和 G)确定硬件缓存如何为这些页面工作,一个访问位 (A)和一个脏位(D),最后是页帧号(PFN)本身。

速度
为了获取到每一个进程的页表,硬件必须知道当前正在运行的进程的页表的位置。现在让我们假设一个页表基址寄存器(page-table base register)包含页表的起始位置的物理地址。
现在,不仅占用空间大,速度也很慢,下面是将加载虚拟地址21到寄存器的代码示例
// VPN_MASK根据上文,在这里是0x30,即11 0000
// 获取虚拟页码的值
VPN = (VirtualAddress & VPN_MASK) >> SHIFT
// 获取到当前页表项的地址
PTEAddr = PTBR + (VPN * sizeof(PTE))
// 获取当前页表项
PTE = AccessMemory(PTEAddr)
// 检查有效性
if (PTE.Valid == False)
RaiseException(SEGMENTATION_FAULT)
// 检查是否可访问
else if (CanAccess(PTE.ProtectBits) == False)
RaiseException(PROTECTION_FAULT)
else
// OFFSET_MASK拿到偏移值,虚拟地址和物理地址的偏移值是相同的
offset = VirtualAddress & OFFSET_MASK
// 首先PTE.PFN获取PFN的值,注意此时的PTF只有20位,也就是0~19,所以需要左移得到高位的PFN
// 再和offset合并,获得真正的物理地址
PhysAddr = (PTE.PFN << PFN_SHIFT) | offset
// 访问地址,放入目的寄存器中
Register = AccessMemory(PhysAddr)
加速分页
每次有无法解决的问题,都要借助硬件的力量。这里要使用地址转换旁路缓冲存储器(translation-lookaside buffer)TLB,也成为地址转换缓存(address-translation cache)。
对每次VPN转换到PFN,硬件先检查 TLB,看看其中是否有期望的转换映射,如果有,就直接返回,不用访问页表 (其中有全部的转换映射)。
TLB的基本算法
// 控制流
VPN = (VirtualAddress & VPN_MASK) >> SHIFT
// 尝试去TLB中获取转换
(Success, TlbEntry) = TLB_Lookup(VPN)
if (Success == True) // TLB Hit
if (CanAccess(TlbEntry.ProtectBits) == True)
// 如果有那么就可以直接组装返回
Offset = VirtualAddress & OFFSET_MASK
PhysAddr = (TlbEntry.PFN << SHIFT) | Offset
AccessMemory(PhysAddr)
else
RaiseException(PROTECTION_FAULT)
else
// 没有就需要执行一般加载,然后放到TLB中
PTEAddr = PTBR + (VPN * sizeof(PTE))
PTE = AccessMemory(PTEAddr)
if (PTE.Valid == False)
RaiseException(SEGMENTATION_FAULT)
else if (CanAccess(PTE.ProtectBits) == False)
RaiseException(PROTECTION_FAULT)
else
TLB_Insert(VPN, PTE.PFN, PTE.ProtectBits)
RetryInstruction()
如果TLB没有被命中,需要多一次的内存引用,所以要尽量避免TLB未命中。
示例

对于上图的数组结构,访问0一定是未命中的,然后1、2都是命中,3不命中,4、5、6命中,7不命中,8、9命中。
同时注意到,如果加大页大小,TLB的命中几率也是会随之增大的。
这种情况就是空间局部性。如果一段时间内再次访问,就会全部命中,这就是时间局部性。
处理未命中
有两种可能分别是硬件与OS。
硬件
硬件必须通过页表基址寄存器知道页表在内存中的确切位置,以及页表的确切格式。发生未命中时, 硬件会遍历页表,找到正确的页表项,取出想要的转换映射,用它更新 TLB,并重试该指令。
OS
发生 TLB 未命中时,硬件系统会抛出一个异常,这会暂停当前的指令流,将特权级提升至内核模式,跳转至陷阱处理程序(trap handler)。这个陷阱处理程序是操作系统的一段代码,用于处理 TLB 未命中。 这段代码在运行时,会查找页表中的转换映射,然后用特别的特权指令更新 TLB,并从陷阱返回。此时,硬件会重试该指令(导致 TLB 命中)。
问题
- 不同于服务调用的从陷阱中返回,这里需要返回后执行当前语句,因此,根据陷阱或异常的原因,系统在陷入内核时必须保存不同的程序计数器,以便将来能够正确地继续执行。
- 当程序代码未命中时,需要注意OS的陷阱处理程序,也是需要进行TLB转换的,有可能不存在于TLB中,这样就会有无限循环,这里提供两种解决方式。
- 可以把 TLB 未命中陷阱处理程序直接放到物理内存中。
- 在 TLB 中保留一些项,记录永久有效的地址转换,并将其中一些永久地址转换槽块留给处理代码本身,这些被监听的(wired) 地址转换总是会命中 TLB。
TLB内容
和记录Segmentation相同,TLB中也不可能是单独的VPN和PFN,一定有一些其他的控制位。例如有效位,保护位,地址空间标识符,脏位等。
上下文切换的影响
当上下文切换时,如果出现两个不同的进程有相同的VPN映射到不同的PFN,这样会让硬件无法区分。所以要想办法是TLB正确而又高效的支持跨进程的虚拟化。
一种做法是每当上下文切换就简单的清空TLB,或将有效位置为0,很明显这种做法简单而低效。
- 在清空后,下一次访问时都会触发TLB未命中。
- 很难支持跨进程。
另一种做法就是加入地址空间标识符(Address Space Identifier,ASID)。可以把 ASID 看作是进程标识符(Process Identifier,PID),但通常比 PID 位数少(PID 一般 32 位, ASID 一般是 8 位)。操作系统在上下文切换时,必须将某个特权寄存器设置为当前进程的 ASID。
如果正在运行的进程数超过 256个怎么办?
In all of the previous methods, each process has an ASID and so the OS data structure that represents a process needs to have a field that stores the ASID. An alternative method is store the currently allocated ASIDs in a separate structure. ASIDs are allocated to processes dynamically at the time when they need to execute. Processes that are not active will not have ASIDs assigned to them. This has two advantages over the previous methods. First, the ASID space is used more efficiently since mostly dormant processes do not unnecessarily consume ASIDs. Second, all the currently allocated ASIDs are stored in the same data structure, which could be made small enough to fit within a few cache lines. In this way, finding new ASIDs can be done efficiently.
大致意思就是会将ASID存储在一个共享的数据结构中,只有当一个进程是活跃的时候,才会分配ASID。
TLB替换策略
最常用的就是最近最少使用(least-recently-used,LRU)。LRU 尝试利用内存引用流中的局部性,假定最近没有用过的项,可能是好的换出候选项。
另一种就是随机(random)策略,它可以用来避免LRU无法解决的极端情况,当一个程序循环访问n+1个页,但是TLB只能存放n个页。这时每次都会引发TLB未命中。
真实的TLB
这个例子来自 MIPS R4000,它是一种现代的系统,采用软件管理 TLB。

MIPS R4000 支持 32 位的地址空间,页大小为 4KB。所以在典型的虚拟地址中,预期会看到 20 位的 VPN 和 12 位的偏移量。但是只有 19 位的 VPN。 事实上,用户地址只占地址空间的一半(剩下的留给内核),所以只需要 19 位的 VPN。VPN 转换成最大 24 位的物理帧号(PFN),因此可以支持最多有 64GB 物理内存( 4KB 内 存页)的系统。
MIPS TLB 还有一些标识位。比如全局位(Global,G),用来指示这个页是不是 所有进程全局共享的。因此,如果全局位置为 1,就会忽略 ASID。我们也看到了 8 位的 ASID,操作系统用它来区分进程空间(像上面介绍的一样)。最后,我们看到 3 个一致性位(Coherence,C),决定硬件 如何缓存该页;脏位(dirty),表示该页是否被写入新数据;有效位(valid),告诉硬件该项的地址映射是否有效。页掩码(page mask)字段,用来支持不同的页大小。最后,64 位中有一些未使用(灰色部分)。
MIPS 的 TLB 通常有 32 项或 64 项,大多数提供给用户进程使用,也有一小部分留给操作系统使用。操作系统可以设置一个被监听的寄存器,告诉硬件需要为自己预留多少 TLB 槽。这些保留的转换映射,被操作系统用于关键时候它要使用的代码和数据,在这些时候, TLB 未命中可能会导致问题(例如,在 TLB 未命中处理程序中).
减小分页
更大的页
最简单的方式就是增大页的大小。然而,这种方法的主要问题在于,大内存页会导致每页内的浪费,这被称为内部碎片(internal fragmentation)问题(因为浪费在分配单元内部)。因此,结果是应用程序会分配页,但只用每 页的一小部分,而内存很快就会充满这些过大的页。
分段与分页结合
在这里,将Segmentation和page结合,将page中vpn的一部分用来表示segmentation的索引。为每个逻辑分段提供一个页表。同样,每个段都有base和limit寄存器。只是再这里,我们使用base不是指向段本身,而是保存该段的页表的物理地址。limit用于指示页表的结尾(即它有多少有效页)。
一个32 位虚拟地址空间包含 4KB 页面,并且地址空间分为 4 个段。在这个例子中,我们只使用 3 个段:一个用于代码,另一个用于堆,还有一个用于栈。则VM如下所示: 
当TLB未命中时,加载物理地址的流程如下:
// 计算属于哪个段
SN = (VirtualAddress & SEG_MASK) >> SN_SHIFT;
VPN = (VirtualAddress & VPN_MASK) >> VPN_SHIFT;
// 使用对应的Base寄存器的值计算PTE的地址
AddressOfPTE = Base[SN] + (VPN * sizeof(PTE));
但是由于分段的存在,此方法还是不够灵活,会有大量外部碎片的产生。
多级页表
多级页表(multi-level page table),将线性页表变成了类似树的数据结构。页目录(page directory)记录页表的页在哪里。
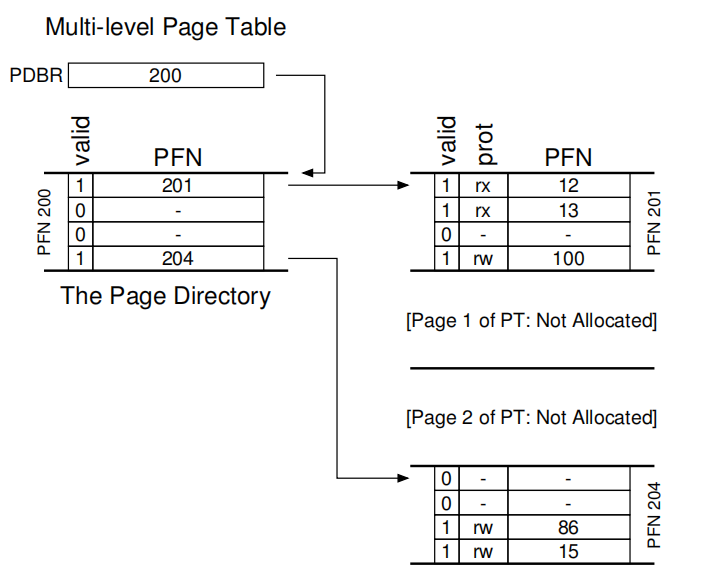
通过这个目录,我们就可以将PT分布在内存的各个位置上,不需要存放在连续的物理内存中。为了获取到真正的物理地址,我们需要对内存操作两次,因此性能有所下降。同时明显复杂度有所上升。
这里通过一个例子来理解多级页表的原理。一个大小为 16KB 的地址空间,其中包含 64 字节的页。因此,我们有一个14位的虚拟地址空间,VPN 有8位,偏移量有6位。假设每个PTE 的大小是4个字节,则每页可以容纳16个PTE,一共有16页,页总大小为1KB(256×4 字节)。那么就需要为为这16页建立索引,使用VPN的前4位形成PDIndex。那么PDEAddr = PageDirBase +(PDIndex * sizeof(PDE))。同时使用VPN剩下的位数指定PTIndex。所以有PTEAddr = (PDE.PFN << SHIFT) + (PTIndex * sizeof(PTE))
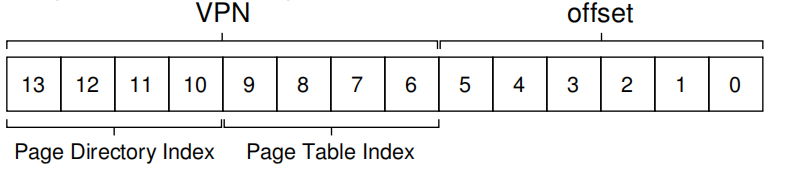
假设PD和PT中有以下数据:
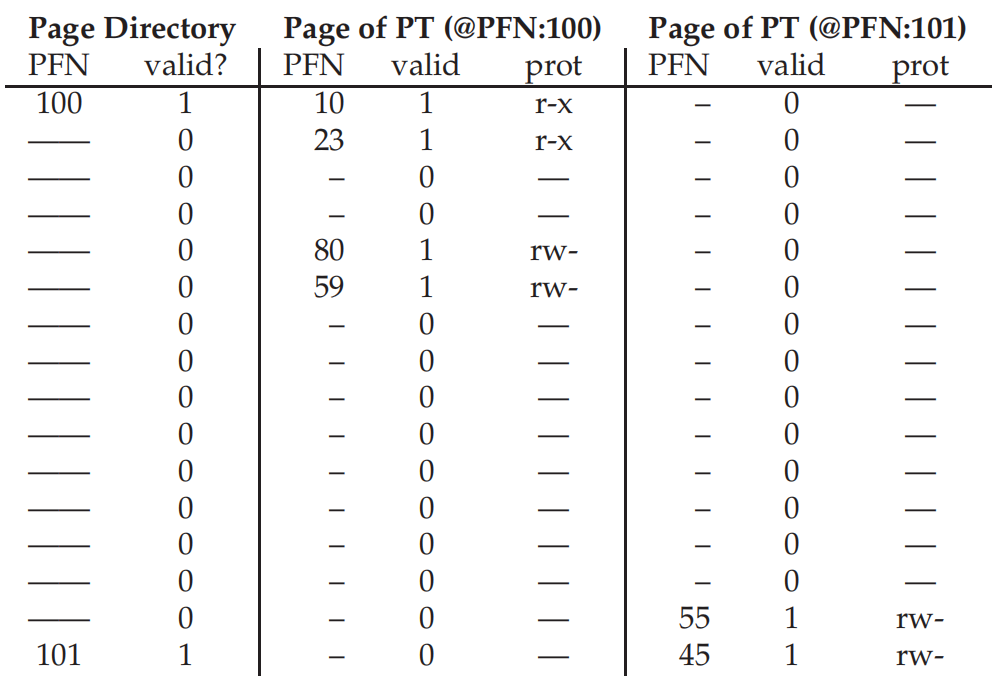
例如要加载虚拟地址 1111 1110 000000
通过前4位
1111,十进制16的PDIndex,利用公式获取到对应的PDE,查明有效值,获取PFN。
通过后四位
1110,十进制15的PTIndex,利用公式$PTEAddr = (PDE.PFN << SHIFT) + (PTIndex * sizeof(PTE)) $
获取到对应的PTE,公式中的
PDE.PFN就是第一步获取的值。拿到对应的PFN结合VM address的
offest结合获取到物理地址。
如果超过两级呢?
实际上结合树的结构以及递归的思想,和二级是差不多的。需要在地址划分上多划出一层。实际上由于现代系统内存都很大,二级页表是很难满足第一层页表可以放入一页中。
对于有一个 30 位的虚拟地址空间和一个小的(512 字节)页。虚拟地址有一个21位的虚拟页号和一个9位偏移量。我们必须将其划分为三层才可满足条件。
二层:
三层:

结合TLB,下面是一个二级页表的流程示例:
VPN = (VirtualAddress & VPN_MASK) >> SHIFT
(Success, TlbEntry) = TLB_Lookup(VPN)
if (Success == True) // TLB Hit
if (CanAccess(TlbEntry.ProtectBits) == True)
Offset = VirtualAddress & OFFSET_MASK
PhysAddr = (TlbEntry.PFN << SHIFT) | Offset
Register = AccessMemory(PhysAddr)
else
RaiseException(PROTECTION_FAULT)
else // TLB Miss
// first, get page directory entry
PDIndex = (VPN & PD_MASK) >> PD_SHIFT
PDEAddr = PDBR + (PDIndex * sizeof(PDE))
PDE = AccessMemory(PDEAddr)
if (PDE.Valid == False)
RaiseException(SEGMENTATION_FAULT)
else
// PDE is valid: now fetch PTE from page table
PTIndex = (VPN & PT_MASK) >> PT_SHIFT
PTEAddr = (PDE.PFN << SHIFT) + (PTIndex * sizeof(PTE))
PTE = AccessMemory(PTEAddr)
if (PTE.Valid == False)
RaiseException(SEGMENTATION_FAULT)
else if (CanAccess(PTE.ProtectBits) == False)
RaiseException(PROTECTION_FAULT)
else
TLB_Insert(VPN, PTE.PFN, PTE.ProtectBits)
RetryInstruction()
反向页表
保留了一个页表,其中的项代表系统的每个物理页,而不是有许多页表(系统的每个进程一个)。页表项告诉我们哪个进程正在使用此页,以及该进程的哪个虚拟页映射到此物理页。通常采用散列表的数据结构。
超越物理内存:底层机制
从现在开始,就需要讨论对于同时运行多个巨大的地址空间,操作系统如何保证其正常运行。
我们可以将一部分没有在使用的地址空间在硬盘中存储起来。
交换空间
首先,我们需要在硬盘上开辟一部分空间专门用于页面的移入和移出,一般这样的空间称为交换空间(swap space),
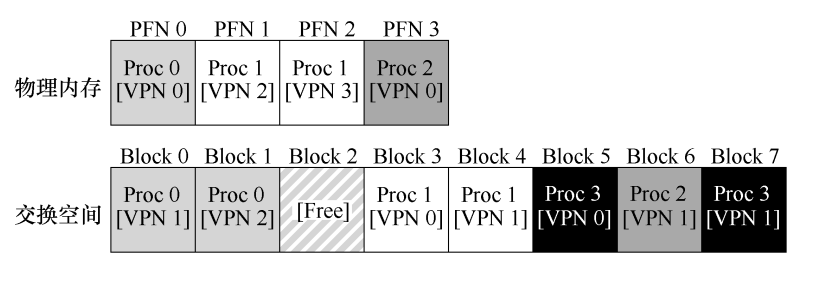
如图所示,进程0、1、2在物理内存和交换空间中都存在页,而进程3只存在于交换空间,因此很明显它没有在运行。
存在位
就像在分页介绍中的列表中的内容所述,需要一个额外的位来表示当前访问的页是在内存中还是在交换空间。
例如程序发出一个内存寻址请求,如果TLB中没有命中,就需要按照页表进行寻找,拿到PTE后如果PTE.PRESENT为1,那么和上面一样,单纯的把物理地址组装出来,放入TLB中重试指令即可。如果为0,这时候就会报出页错误(page fault)。
页错误
当操作系统接收到页错误时,它会在 PTE 中查找硬盘地址,并将请求发送到硬盘,将页读取到内存中。
当硬盘 I/O 完成时,操作系统会更新页表,将此页标记为存在,更新页表项(PTE)的 PFN 字段以记录新获取页的内存位置,并重试指令。下一次重新访问 TLB 还是未命中,然 而这次因为页在内存中,因此会将页表中的地址更新到 TLB 中(也可以在处理页错误时更 新 TLB 以避免此步骤)。最后的重试操作会在 TLB 中找到转换映射,从已转换的内存物理 地址,获取所需的数据或指令。
同时注意,在磁盘I/O进行时,进程是处于阻塞(blocked)状态,可以被操作系统调度放弃使用CPU。
// 流程控制
VPN = (VirtualAddress & VPN_MASK) >> SHIFT
(Success, TlbEntry) = TLB_Lookup(VPN)
if (Success == True) // TLB Hit
if (CanAccess(TlbEntry.ProtectBits) == True)
Offset = VirtualAddress & OFFSET_MASK
PhysAddr = (TlbEntry.PFN << SHIFT) | Offset
Register = AccessMemory(PhysAddr)
else
RaiseException(PROTECTION_FAULT)
else // TLB Miss
PTEAddr = PTBR + (VPN * sizeof(PTE))
PTE = AccessMemory(PTEAddr)
if (PTE.Valid == False)
RaiseException(SEGMENTATION_FAULT)
else
if (CanAccess(PTE.ProtectBits) == False)
RaiseException(PROTECTION_FAULT)
else if (PTE.Present == True)
// assuming hardware-managed TLB
TLB_Insert(VPN, PTE.PFN, PTE.ProtectBits)
RetryInstruction()
else if (PTE.Present == False)
// 主要是这里,当Present为假时,需要抛出页错误
RaiseException(PAGE_FAULT)
// 页错误处理程序
// 为要交换的页寻找空闲的物理帧
PFN = FindFreePhysicalPage()
if (PFN == -1) // no free page found
PFN = EvictPage() // 运行替换算法
DiskRead(PTE.DiskAddr, pfn) // sleep (waiting for I/O)
PTE.present = True // update page table with present
PTE.PFN = PFN // bit and translation (PFN)
RetryInstruction() // retry instruction
何时发生交换
OS一般会预留一小部分空闲的内存,同时设置高水位线(High Watermark,HW),低水位线(Low Watermark,LW),来帮助决定何时从内存中清除页。
当操作系统发现有少于 LW 个页可用时,后台负责释放内存的线程会开始运行,直到有 HW 个 可用的物理页。这个后台线程有时称为交换守护进程(swap daemon)或页守护进程(page daemon),它然后会进入休眠状态。
同时,许多系统会把多个要写入的页聚集(cluster)或分组(group),同时写入到交换区间,减少磁盘的操作。
所以上面的页错误处理程序有所修改,在没有空闲页时,会先进行释放页面。
超越物理内存:上层策略
在了解完底层机制后,就需要知道页换出的策略,怎样选择正确的页换出,如果选择不当,内存的效率甚至会退化到磁盘的程度。
缓存管理
在这里,内存中的页可以看作所有页的子集,所以可以视为系统中虚拟内存页的缓存(cache),这里的目标是使得缓存命中(cache hit)最多,缓存未命中(cache miss)最少。
通常使用程序的平均内存访问时间(Average Memory Access Time,AMAT)衡量缓存的效率,公式如下:
P是缓存命中和未命中的比例。由于和之间差了5个数量级左右,所以就算是的命中率,耗时也会很长。所以要尽量避免访问磁盘。
最优替换策略
最优替换策略(Optimal Replacement Policy,OPT)即替换内存中在最远将来才会被访问到的页,通俗的讲:在引用最远将来会访问的页之前,肯定会引用其他页。这更像是一个假想的策略,因为我们无法判断未来会发生的事情。
冷启动未命中(cold-start miss,或强制未命中,compulsory miss),即在最开始,缓存中没有任何数据,所以刚开始都是未命中。
容量未命中(capacity miss),当缓存空间不足是,不得不进行替换,将缓存中的一项踢出,以便引入新的一项。
冲突未命中(conflict miss),在缓存与外部存储映射时,会出现两个项映射到同一个缓存项上,此时就发生了冲突未命中。
FIFO
FIFO就是类似队列的思想,在给定额度的情况下,当缓存项占满后,第一个进入的缓存项被提出。
随机
随机策略会在缓存容量不足时,随机踢出一项,效率完全取决于当时的运气。
LRU
最少最近使用(Least-Recently-Used,LRU),我们虽然不能判断未来,但是可以通过历史预测未来,如果某个程序在过去访问过某个页,则很有可能在不久的将来会再次访问该页,实际上就是利用了程序的局部性原理。
使用的历史信息是访问的近期性(recency), 越近被访问过的页,也许再次访问的可能性也就越大。
最不经常使用(Least-Frequently-Used, LFU),使用的历史信息是频率(frequency)。如果一个页被访问了很多次, 也许它不应该被替换,因为它显然更有价值。
近似LRU
如果要实现一个完美的LRU,例如当页被访问时,时间字段将被硬件设置为当前时间。然后,在需要替换页时,操作系统可以简单地扫描系统中所有页的时间字段以找到最近最少使用的页。但是随着系统中页数量的增长,扫描所有页的时间字段只是为了找到最精确最少使用的页,这个代价太昂贵。
近似LRU会为每一个页多增加一个使用位(use bit),每当页被引用(即读或写)时,硬件将使用位设置为 1。但是,硬件不会清除该位(即将其设置为 0),这由操作系统负责。
时钟算法
我们把系统中的所有页都放在一个循环列表中,时钟指针(clock hand)开始时指向某个特定的页(哪个页不重要)。当必须进行页替换时,操作系统检查当前指向的页 P 的使用位是 1 还是 0。如果是 1,则意味着页面 P 最近被使用,因此不适合被替换。然后,P 的使用位设置为 0,时钟指针递增到下一页(P + 1)。该算法一直持续到找到一个使用位为 0 的页,使用位为 0 意味着这个页最近没有被使用过(在最坏的情况下,所有的页都已经被使用了,那么就将所有页的使用位都设置为 0)。
也可以不轮询,采用随机的特性。
考虑脏页
如果页已被修改(modified)并因此变脏(dirty),则踢出它就必须将它写回磁盘,这很昂贵。如果它没有被修改(因此是干净的,clean),踢出就没成本。物理帧可以简单地重用于其他目的而无须额外的 I/O。因此,一些虚拟机系统更倾向于踢出干净页,而不是脏页。
因此可以增加修改位(modified bit,又名脏位,dirty bit)。因此时钟算法可以稍作修改,以扫描既未使用又干净的页先踢出。无法找到这种页时,再查找脏的未使用页面
其他策略
在使用替换策略之前,同时可以配合使用其他策略如:
- 按需分页(demand paging),只加载出当前所需的页面。
- 预取(prefetching),OS会猜测一个页面即将被使用,从而提前载入(局部性)。
- 聚集(clustering)写入,或者分组(grouping),在大量页面替换时,能够减少磁盘的I/O操作。
抖动
当内存就是被超额请求时,系统将不断地进行换页,这种情况有时被称为抖动(thrashing)。
一些早期的操作系统有一组相当复杂的机制,以便在抖动发生时检测并应对。例如,给定一组进程,系统可以决定不运行部分进程,希望减少的进程工作集(它们活跃使用的页面)能放入内存,从而能够取得进展。这种方法通常被称为准入控制(admission control),它表明,少做工作有时比尝试一下子做好所有事情更好,这是我们在现实生活中以及在现代计算机系统中经常遇到的情况。 目前的一些系统采用更严格的方法处理内存过载。例如,当内存超额请求时,某些版本的 Linux 会运行“内存不足的杀手程序(out-of-memory killer)”。这个守护进程选择一个内存密集型进程并杀死它,从而以不怎么委婉的方式减少内存。虽然成功地减轻了内存压力,但这种方法可能会遇到问题,例如,如果它杀死 X 服务器,就会导致所有需要显示的应用程序不可用。