本章主要讲关于二进制的相关知识
1. 信息存储
我们通常将八位(bits)定义为一个字节(byte),作为可最小寻址的内存单位,每个字节都有一个唯一的数字标识,称为地址,所有可用的地址集合称为虚拟内存地址
1.1 十六进制转化
很常用的十六进制和二进制的转换方法:一位十六进制对应四位二进制(同样八进制对应三位二进制数),举个例子:FF -> 1111,1111
1.2 字数据大小
每台计算机都对应着一个唯一的字长,大部分是32位字长和64位字长,对于自长为w的机器,他的虚拟内存地址范围就是0~2^w-1
linux> gcc -m32 main.c
linux> gcc -m64 main.c
可用于指定编译时的字长,对于32位程序可以在32或64位的机器上运行,因为64位机器是向下兼容的,但是64位程序只能在64位机器上运行
1.3 寻址和字节顺序
在机器中多字节的对象几乎都是连续存储的,这里设一个int数据类型的a变量,地址为0x100,在c语言中int占4个字节,所以它的内存寻址就是0x100-0x101-0x102-0x103
假设a的十六进制为0x01234567,通常称01为最高有效位,67为最低有效位。但是在存储顺序上,不同的机器有不同的方式
大端法
即将最高有效位存储在前
小端法
将最低有效位存储在前(常见)
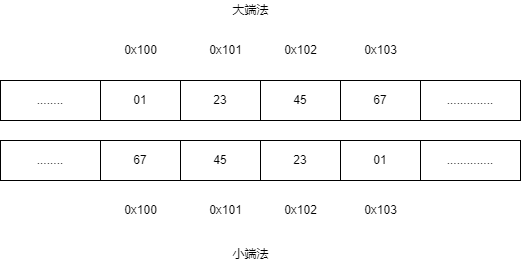
虽然有大小端之分,但是可以从图中看出,他们都是从内存的低地址到高地址
1.4 布尔代数
最常见的&,|,~,^,普通的运算规则不在介绍。
这里引入了一个位向量的概念,举例说明:对于二进制10010它的位向量是{1,4},两个二进制的数进行布尔运算就可以转化为位向量的集合运算。&对应的是集合的交运算,|对应的是集合的并运算,~对应的集合的补运算
1.5 c语言中的位,逻辑,移位运算
通常位运算和逻辑运算会搞混,逻辑运算会将所有非零的表示为true,零表示为false,并且只会返回一或零。
逻辑运算符||和&&他们有短路效果,例如0 & a = 1其中的赋值操作不会被执行
可以通过这个特性来避免空指针操作:p && *p++
移位运算包括左移右移
- 左移运算就是单纯的在末尾补零
- 右移运算分为两种情况
逻辑右移是补充零
算数右移是补充符号位
几乎全部机器对于有符号数的右移是算数右移,但是注意对于无符号数,右移一定是逻辑的
2. 整数表示
整数表示通常分为两种不同的方式,即无符号数(只能表示非负数),有符号数(负数,零,正数)
在这里通常称B(binary)为二进制,U(unsinged)无符号数,T(tow's-complement)也就是通常说的补码
2.1 无符号数的编码
很简单,举个例子
1001就是1*2^3 + 0*2^2 + 0*2^1 + 1*2^0 = 9它的公式为:
这里就可以看出
2.2 补码的编码
举个例子,还是使用上面的位模式
1001那么对应的就是-1*2^3 + 0*2^2 + 0*2^1 + 1*2^0 = -7它的公式为:
那么
这里会有两个注意点
其实是因为在非负数中还要额外表示一个零,所以 TMax的绝对值要小一些
在无符号数中,有的数在有符号书中是负数,同时有符号数的
-1和无符号数的UMax有相同的位表示,一个全一的串
2.3 有符号数和无符号数之间的转换
首先是有符号数转化为无符号数,对于有两种情况:
- 当
x < 0时:x + - 当
x >= 0时:x
很明显当x大于等于零时有符号和无符号数相等,当x小于零时,x的最高次位由转化为,即增加了
其次对于也是同样的:
- 当
x > TMax时:x - - 当
x <= TMax时:x
2.4 c语言中的有符号和无符号数
对于有符号和无符号数同时参与运算,会隐式的将有符号数转化为无符号数,再进行运算
举个例子:-1 < 0U 的运算结果是false:在有符号数中-1的位表示和无符号中UMax的位表示相同,都是一个全一串,所以UMax当然小于0喽
2.5 扩展一个数字的位表示
- 扩展就是在不同字长的整数之间转换,而又不改变数值,由一个较小的数据类型转化为一个较大的数据类型总是可行的
对于无符号数:直接在开头添加零,这种被称为零扩展
对于补码的扩展:一般是在开头添加其符号位,这种被称为符号扩展
当前有一种情况:需要将short转化为unsigned,需要怎么做呢?
其实这里涉及到了扩展和符号转换,顺序一般是先进行扩展转换(short->int),再进行符号转换(int->unsigned)
2.6 截断数字
- 截断是在不同字长的整数之间转换,而又不改变数值,由一个较大的数据类型转为一个较小的数据类型
对于无符号数:要将原数截断为长度为k的数:通常是
对于有符号数:先当作无符号数进行一边无符号数的操作,再进行一边
- 举个例子:对于
10101要截断为三位,截断后的十进制数为?
先对13进行截断 即:得到101也就是5,然后进行得到-3
3. 整数运算
3.1 无符号数的加法、乘法
无符号数的相加,如果两个数的和小于UMax,那么一切正常。但是如果一旦超过了UMax,那么就会发生溢出的情况,在无符号数的溢出状态下,会对其进行取模操作,同时也可以将不溢出的状态也纳入取模的操作中:
乘法类似于加法:
一般情况下溢出是指完整的运算结果无法放入数据类型的字长限制中,这时候会对其进行截断操作
检测无符号数相加是否溢出:
对于 如果 成立时,就发生了溢出
无符号数求反:
对其位表示每一位都求反,然后再加1,最后进行
3.2 补码加法
同样,补码的加法也存在溢出(当符号不同时,一定不会发生溢出),不过有两种情况
- 当时,被称为正溢出,解决方法和无符号数相同
- 当时,被称为负溢出,这种情况通常会进行的操作
检测补码加法是否溢出:
补码的非
对其位表示每一位都求反,然后再加
1,最后进行
3.3 补码乘法
补码的乘法有一些特点:
它的截断值和相同位模式下的无符号数的截断值相同
使用二进制计算补码乘法时,需要进行符号扩展,参考这篇文章:关于补码(有符号)乘法遇到的疑惑
当两个数都是正数时其实和无符号数相同,只有当存在负数时才有些特别。
举个例子:设字长是4位,计算-3*3:
如果只计算截断值,那么就可以利用第一个特性:
- 将两个数的位模式看为无符号数:
1101*0011 - 那么就变成了计算
13*3得出二进制:00100111 - 再进行
4位截断得到:0111 - 那么补码
-3*3的四位截断就是0111
- 将两个数的位模式看为无符号数:
计算全部值可以通过十进制计算,也可以通过二进制计算,具体可以看上面的文章
3.4 乘以常数
对于乘法运算,通常可以使用移位运算和加法运算进行组合代替。
先考虑乘二的幂的情况,很明显,
再概括为乘任意的数:
举例:计算:,有,那么就有,也就是 ,这样就将一个比较耗时的乘法运算转换为了移位运算和加法运算结合
3.5 除以2的幂
对于无符号数和补码的正数来说,除以2的幂就是对其进行右移补零:,这个的计算结果是向零取整
对于补码的负数,很明显是要进行算数右移,补一。但是单纯的这样计算会发现,计算的结果是向负无穷取整,不符合预期,所以这里在移位之前,需要加一个**偏置 **n:,其中k是要移位的位数。
举例:计算:
- 首先计算偏置:
- 然后计算
- 之后进行移位计算得到,使用得到结果为
-1
这里有一道题目很有趣,不能使用除法、模运算、乘法、条件语句、循环语句和比较运算符,实现一个函数,输入int 类型x,返回x/16,int是32位长。
很明显这里要分情况讨论:当x大于等于零时,要直接右移四,但是当小于零时,还需要加上偏置,这里不让使用判断条件,比较麻烦。但是题目中告诉我们这里的int类型是32位的,联想到补码的知识,那么我们就可以通过右移31位来判断是否是负数。同时通过16计算出偏置为15也就是0xF。
当它是负数时,右移31位的末尾4位就是
1111,当它是 正数时,右移31位的末尾4位就是0000,这样我们就可以想到使用与运算符,可以达到类似掩码的效果,偏置:,那么之后就return (x+n)>>4
4. 浮点数
4.1 二进制小数
二进制表示小数同十进制,只是将位权从10变为2,但是二进制表示法只能表示的数,其他值只能近似的表示。而且在计算机中,对于给定的字长,我们需要在范围和精度之间进行衡量,当整数部分占的位数多时,小数部分就不能表示的更加精确,反之亦然。
4.2 IEEE浮点表示
IEEE浮点标准用 的形式来表示一个数,其中:
s用于决定符号,表示为负数,表示为正数M叫做尾数,是一个二进制小数,范围是或E称作阶码,它的作用是对浮点数进行加权,可能是负数
单精度浮点数和双精度浮点数的存储方式:

其中s是符号位,exp用来编码阶码,frac用来编码M。在编码阶码的过程中,通常会使用一个叫做偏置(bias)的值,因为E可以取正也可以取负,所以加上一个偏置,将其转换为一个无符号数exp,以简化运算。偏置的计算方法:$bias = 2^{k-1}-1 $,k是exp的位长度
根据exp的取值,通常将被编码的值分成三种情况:
规格化的值:
exp即不全为零又不全为一,这个时候同时,举个例子:- 对于单精度
3.25的位表示11.01,我们首先通常将它变成这样的形式,这个过程被称为规格化。我们会发现,这种情况下,前面的1是一定会存在的,那么我们就可以将其舍弃,这样就会多出一位存储空间。那么frac就是000...11(前面补零,补足23位) - 因为它是正数,所以
- 最后合起来就是
010000000000....11
- 对于单精度
非规格化的值:
exp全为0,这个时候,举个例子:- 对于单精度
0.25的位表示0.01,我们不再进行规格化,frac就是00...01(23位) exp全是0- 正数,
- 合起来就是
100000000000...01
- 对于单精度
当exp全是1时有两种情况:
- frac全是0,这时候代表无穷,s可以决定正还是负
- frac不是0,代表
NaN,同样有正负
非规格化的数的一些特性:
- 提供表示零的方式,因为规格化的数M总是大于等于一。同时零也分正负号,它们在
- 可以用来表示一些很小的数,并提供一种属性叫做逐渐下溢
- 有
E=1-bias,用于求出阶码值,这样设计的原因是提供了一种从非规格化值平滑的转换到规格化值的方式
这里有一个图,形象化的表示了分布范围:
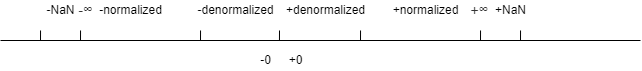
4.3 舍入
由于目前的表示方法限制了浮点数的范围和精度,所以我们希望使用可表示的来表示,这时就需要舍入。
舍入一般分四种:
- 向零舍入
- 向下舍入
- 向上舍入
- 向偶数舍入(默认)
前三种都好理解,最后一种是浮点数舍入的默认做法,它的具体步骤是这样的:
- 判断待舍入的值和中间值的大小
- 如果小于中间值,直接舍弃;大于等于中间值,向最近的偶数进行舍入
首先举几个十进制的例子,保留一位小数:
1.44我们对它进行直接舍弃,因为0.04小于中间值0.051.46首先0.06大于0.05,所以进行向偶数舍入,离它最近的偶数就是1.41.56,同理也向偶数舍入,这次舍入到1.6
在二进制中,1是奇数,0是偶数:
举几个二进制的例子,还是保留一位小数:
1.101,01小于10直接舍弃1.110,10等于中间值10,进行向偶数舍入,得10.01.0101,和上面相同,只不过这个向偶数舍入,得到的是1.0
这种向偶数舍入可以有效的避免统计误差
4.4 浮点运算
首先讨论乘法:
计算:,,
计算中需要进行一些调整:
- 如果,我们需要将M向右移动,同时增加E
- 如果
exp超出了的范围,那么就是溢出 - 如果
frac超出了范围,进行舍入
对于加法,这里贴一张图:
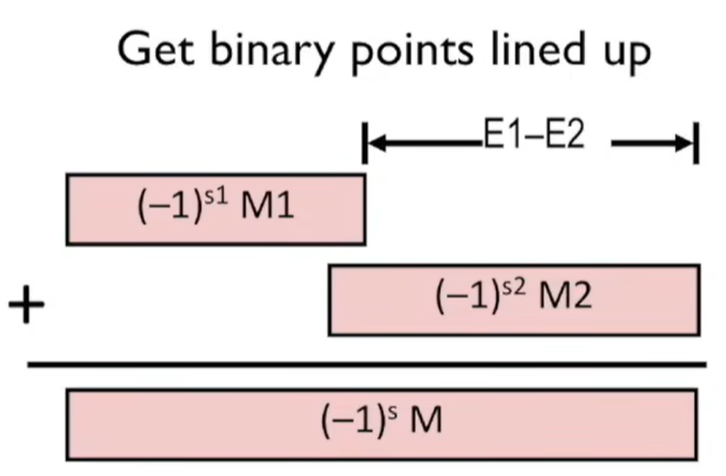 浮点加法还有许多其他的特性:
浮点加法还有许多其他的特性:
- 它没有结合性,比如:但是
- 浮点加法满足了单调性,它的符号是由一位的S所控制
注意在顺箭头类型转换时,会发生精度的丢失。